解决方案:【机器学习】一文彻底搞懂自动机器学习AutoML:Auto-Sklearn
优采云 发布时间: 2022-11-22 05:18解决方案:【机器学习】一文彻底搞懂自动机器学习AutoML:Auto-Sklearn
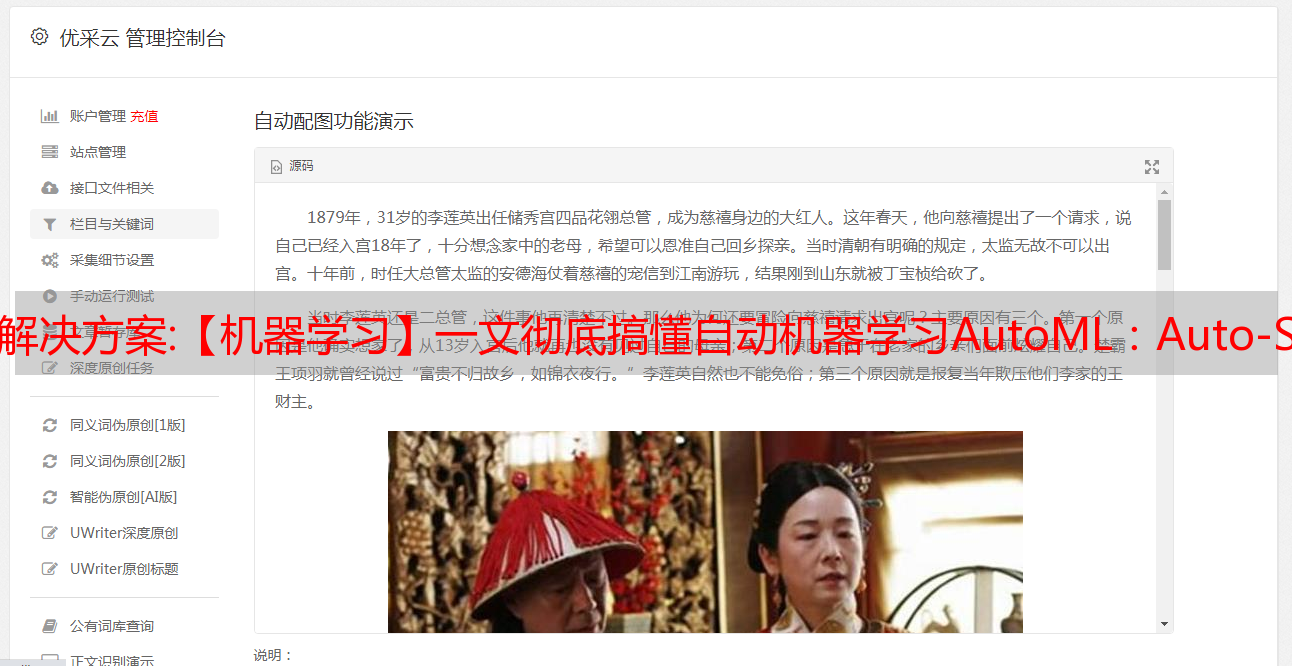
本文将系统全面地介绍自动机器学习常用的框架之一:Auto-Sklearn,介绍安装使用,分类回归小案例,介绍一些使用手册。自动机器学习
自动化机器学习 AutoML 是机器学习中一个相对较新的领域。它主要自动化机器学习中所有耗时的过程,例如数据预处理、最优算法选择、超参数调优等,可以节省大量构建机器的时间。在学习模型的过程中。
Automatic Machine Learning AutoML:对于,让表示特征向量,表示相应的目标值。给定训练数据集和从与其相同的数据分布中提取的测试数据集的特征向量,以及资源预算和损失度量,AutoML 问题是自动为测试集生成预测,而 AutoML 问题的解决方案损失值。
AutoML 是为数据集的数据转换、模型和模型配置发现性能最佳的管道的过程。
AutoML 通常涉及使用复杂的优化算法(例如贝叶斯优化)来有效地导航可能模型和模型配置的空间,并快速发现对给定预测建模任务最有效的算法。它允许非专业的机器学习从业者快速轻松地发现对给定数据集有效甚至最佳的方法,几乎不需要技术背景或直接输入。
如果你用过sklearn,应该不难理解上面的定义。下面结合一张流程图来进一步理解。
Auto-Sklearn 系统概述Auto-Sklearn
Auto-Sklearn 是一个开源库,用于在 Python 中执行 AutoML。它利用流行的 Scikit-Learn 机器学习库进行数据转换和机器学习算法。
它是由 Matthias Feurer 等人开发的。并在他们 2015 年题为“高效且稳健的自动化机器学习 [1]”的论文中进行了描述。
…我们引入了一个基于 scikit-learn 的强大的新 AutoML 系统(使用 15 个分类器、14 种特征预处理方法和 4 种数据预处理方法,产生具有 110 个超参数的结构化假设空间)
我们介绍了一个基于 scikit-learn 的强大的新 AutoML 系统(使用 15 个分类器、14 种特征预处理方法和 4 种数据预处理方法,产生了一个具有 110 个超参数的结构化假设空间)。
Auto-Sklearn 的好处是,除了发现数据预处理和模型来为数据集执行之外,它还能够从在类似数据集上表现良好的模型中学习,并可以自动创建性能最佳的集成作为优化过程的一部分找到的模型。
这个系统,我们称之为 AUTO-SKLEARN,通过自动考虑过去在类似数据集上的表现,并通过在优化期间评估的模型构建集成,改进了现有的 AutoML 方法。
我们称之为 AUTO-SKLEARN 的这个系统通过自动考虑过去在类似数据集上的表现并通过优化期间评估的模型构建集成来改进现有的 AutoML 方法。
Auto-Sklearn 是对通用 AutoML 方法的改进。自动机器学习框架采用贝叶斯超参数优化方法来有效地发现给定数据集的最佳性能模型管道。
这里添加了两个额外的组件:
这种元学习方法是对用于优化 ML 框架的贝叶斯优化的补充。对于与整个 ML 框架一样大的超参数空间,贝叶斯优化起步缓慢。选择了几种配置用于基于元学习的*敏*感*词*贝叶斯优化。这种通过元学习的方法可以称为热启动优化方法。再加上多模型自动集成的方式,整个机器学习过程高度自动化,将大大节省用户的时间。从这个过程来看,机器学习用户可以有更多的时间来选择数据和思考要处理的问题。
贝叶斯优化
贝叶斯优化的原理是利用已有样本在优化目标函数方面的表现来构建后验模型。后验模型上的每个点都是高斯分布,具有均值和方差。如果该点是已有的样本点,均值为优化目标函数在该点的值,方差为0。其他未知样本点的均值和方差由后验概率拟合,不一定接近真正的价值。然后用一个
" target="_blank">采集
贝叶斯优化
上图是贝叶斯优化应用于简单一维问题的实验图。这些图显示了四次迭代后高斯过程对目标函数的逼近。下面以t=3为例介绍图中各部分的作用。
上图中的两个评价黑点和一个红色评价是备选模型经过三次评价后的初始值估计,会影响下一个点的选择,可以画出很多通过这三个点的曲线。黑色虚线曲线是实际的真实目标函数(通常是未知的)。黑色实线是代理模型目标函数的平均值。紫色区域是代理模型目标函数的方差。绿色阴影部分是指采集函数的值,取最大值的点作为下一个采样点。只有三个点,拟合效果稍差。黑点越多,黑色实线和黑色虚线之间的面积越小,误差越小,
安装和使用 Auto-Sklearn
Auto-sklearn 提供开箱即用的监督式自动机器学习。从名字就可以看出,auto-sklearn是基于机器学习库scikit-learn构建的,可以自动搜索新数据集的学习算法,并优化其超参数。因此,它将机器学习用户从繁琐的任务中解放出来,让他们有更多时间专注于实际问题。
这里可以参考auto-sklearn官方文档[2]。
Ubuntu
>>> sudo apt-get install build-essential swig<br />>>> conda install gxx_linux-64 gcc_linux-64 swig<br />>>> curl `https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt` | xargs -n 1 -L 1 pip install<br />>>> pip install auto-sklearn<br />
蟒蛇
pip install auto-sklearn<br />
安装后,我们可以导入库并打印版本号以确认安装成功:
# print autosklearn version<br />import autosklearn<br />print('autosklearn: %s' % autosklearn.__version__)<br />
您的版本号应该相同或更高。
autosklearn: 0.6.0<br />
根据预测任务,无论是分类还是回归,都可以创建和配置 AutoSklearnClassifier[3] 或 AutoSklearnRegressor[4] 类的实例,将其拟合到数据集,仅此而已。然后可以直接使用生成的模型进行预测或保存到文件(使用 pickle)供以后使用。
AutoSklearn 类参数
AutoSklearn 类提供了大量的配置选项作为参数。
默认情况下,搜索将在搜索过程中使用数据集的训练测试拆分,为了速度和简单性,这里建议使用默认值。
参数n_jobs可以设置为系统的核心数,如果有8个核心,则n_jobs=8。
通常,优化过程会连续运行并以分钟为单位。默认情况下,它将运行一小时。
这里建议将time_left_for_this_task参数设置为这个任务的最大时间(你希望进程运行的秒数)。例如,对于许多小型预测建模任务(行数少于 1,000 的数据集)来说,不到 5-10 分钟就足够了。如果不指定该参数,进程将连续运行,以分钟计,进程运行一小时,即60分钟。此示例通过 per_run_time_limit 参数将分配给每个模型评估的时间限制为 30 秒。例如:
# define search<br />model = AutoSklearnClassifier(time_left_for_this_task=5*60, <br /> per_run_time_limit=30,<br /> n_jobs=8)<br />
还有其他参数,如 ensemble_size、initial_configurations_via_metallearning 可用于微调分类器。默认情况下,上述搜索命令会创建一组性能最佳的模型。为了避免过度拟合,我们可以通过更改设置 ensemble_size = 1 和 initial_configurations_via_metallearning = 0 来禁用它。我们在设置分类器时排除了这些以保持方法简单。
在运行结束时,可以访问模型列表以及其他详细信息。sprint_statistics() 函数总结了最终模型的搜索和性能。
# summarize performance<br />print(model.sprint_statistics())<br />
分类任务
在本节中,我们将使用 Auto-Sklearn 来发现 Sonar 数据集的模型。

" />
Sonar 数据集 [5] 是一个标准的机器学习数据集,由 208 行数据和 60 个数字输入变量和一个具有两个类值的目标变量组成,例如二分类。
使用重复分层 10 折交叉验证的测试框架,重复 3 次,朴素模型可以达到约 53% 的准确度。性能最好的模型在相同的测试框架上达到了大约 88% 的准确率。这为该数据集提供了预期的性能范围。
该数据集涉及预测声纳返回是指示岩石还是模拟地雷。
# summarize the sonar dataset<br />from pandas import read_csv<br /># load dataset<br />dataframe = read_csv(data, header=None)<br /># split into input and output elements<br />data = dataframe.values<br />X, y = data[:, :-1], data[:, -1]<br />print(X.shape, y.shape)<br />
运行该示例会下载数据集并将其拆分为输入和输出元素。您可以看到具有 60 个输入变量的 208 行数据。
(208, 60) (208,)<br />
首先,将数据集分为训练集和测试集,目标是在训练集上找到一个好的模型,然后评估在 holdout 测试集上找到的模型的性能。
# split into train and test sets<br />X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)<br />
使用以下命令从 autosklearn 导入分类模型。
from autosklearn.classification import AutoSklearnClassifier<br />
AutoSklearnClassifier 配置为使用 8 个内核运行 5 分钟,并将每个模型评估限制为 30 秒。
# define search<br />model = AutoSklearnClassifier(time_left_for_this_task=5*60,<br /> per_run_time_limit=30, n_jobs=8,<br /> tmp_folder='/temp/autosklearn_classification_example_tmp')<br />
这里提供了一个临时的日志保存路径,方便我们后面打印运行明细。
然后在训练数据集上执行搜索。
# perform the search<br />model.fit(X_train, y_train)<br />
报告搜索摘要和最佳性能模型。
# summarize<br />print(model.sprint_statistics())<br />
可以使用以下命令为搜索考虑的所有模型打印排行榜。
# leaderboard<br />print(model.leaderboard())<br />
可以使用以下命令打印有关所考虑模型的信息。
print(model.show_models())<br />
我们还可以使用SMOTE、集成学习(bagging、boosting)、NearMiss算法等技术来解决数据集中的不平衡问题。
最后评估模型在测试数据集上的性能。
# evaluate best model<br />y_pred = model.predict(X_test)<br />acc = accuracy_score(y_test, y_pred)<br />print("Accuracy: %.3f" % acc)<br />
也可以打印集成的最终分数和混淆矩阵。
# Score of the final ensemble<br />from sklearn.metrics import accuracy_score<br />m1_acc_score= accuracy_score(y_test, y_pred)<br />m1_acc_score<br />from sklearn.metrics import confusion_matrix, accuracy_score<br />y_pred= model.predict(X_test)<br />conf_matrix= confusion_matrix(y_pred, y_test)<br />sns.heatmap(conf_matrix, annot=True)<br />
运行结束时,打印的摘要显示评估了 1,054 个模型,最终模型的估计性能为 91%。
auto-sklearn results:<br />Dataset name: f4c282bd4b56d4db7e5f7fe1a6a8edeb<br />Metric: accuracy<br />Best validation score: 0.913043<br />Number of target algorithm runs: 1054<br />Number of successful target algorithm runs: 952<br />Number of crashed target algorithm runs: 94<br />Number of target algorithms that exceeded the time limit: 8<br />Number of target algorithms that exceeded the memory limit: 0<br />
然后在 holdout 数据集上对该模型进行评估,发现其分类准确率达到 81.2%,相当熟练。
Accuracy: 0.812<br />
返回任务
在本节中,Auto-Sklearn 用于挖掘汽车*敏*感*词*集的模型。
汽车*敏*感*词*集 [6] 是一个标准的机器学习数据集,由 63 行数据、一个数字输入变量和一个数字目标变量组成。
使用具有重复分层 10 折交叉验证和三个重复的测试框架,朴素模型实现了大约 66 的平均绝对误差 (MAE)。性能最佳的模型在同一测试框架上实现了大约 28 的 MAE。这为该数据集提供了预期的性能限制。
该数据集涉及根据不同地理区域的索赔数量预测索赔总额(千瑞典克朗)。
可以使用与上一节中相同的过程,尽管我们将使用 AutoSklearnRegressor 类而不是 AutoSklearnClassifier。
默认情况下,回归器将优化指标。如果需要使用均值绝对误差或MAE,可以在调用fit()函数时通过metric参数指定。
# example of auto-sklearn for the insurance regression dataset<br />from pandas import read_csv<br />from sklearn.model_selection import train_test_split<br />from sklearn.metrics import mean_absolute_error<br />from autosklearn.regression import AutoSklearnRegressor<br />from autosklearn.metrics import mean_absolute_error as auto_mean_absolute_error<br /># load dataset<br />dataframe = read_csv(data, header=None)<br /># split into input and output elements<br />data = dataframe.values<br />data = data.astype('float32')<br />X, y = data[:, :-1], data[:, -1]<br /># split into train and test sets<br />X_train, X_test, y_train, y_test = train_test_split(X, y, <br /> test_size=0.33, <br /> random_state=1)<br /># define search<br />model = AutoSklearnRegressor(time_left_for_this_task=5*60, <br /> per_run_time_limit=30, n_jobs=8)<br /># perform the search<br />model.fit(X_train, y_train, metric=auto_mean_absolute_error)<br /># summarize<br />print(model.sprint_statistics())<br /># evaluate best model<br />y_hat = model.predict(X_test)<br />mae = mean_absolute_error(y_test, y_hat)<br />print("MAE: %.3f" % mae)<br />
运行结束时,打印的摘要显示评估了 1,759 个模型,最终模型的估计性能为 29 MAE。
auto-sklearn results:<br />Dataset name: ff51291d93f33237099d48c48ee0f9ad<br />Metric: mean_absolute_error<br />Best validation score: 29.911203<br />Number of target algorithm runs: 1759<br />Number of successful target algorithm runs: 1362<br />Number of crashed target algorithm runs: 394<br />Number of target algorithms that exceeded the time limit: 3<br />Number of target algorithms that exceeded the memory limit: 0<br />
保存训练好的模型
上面训练的分类和回归模型可以使用python包Pickle和JobLib保存。然后可以使用这些保存的模型直接对新数据进行预测。我们可以将模型保存为:
1.泡菜
import pickle<br /># save the model <br />filename = 'final_model.sav' <br />pickle.dump(model, open(filename, 'wb'))<br />
这里的“wb”参数表示我们正在以二进制方式将文件写入磁盘。此外,我们可以将这个保存的模型加载为:
#load the model<br />loaded_model = pickle.load(open(filename, 'rb'))<br />result = loaded_model.score(X_test, Y_test)<br />print(result)<br />
这里的“rb”命令意味着我们正在以二进制模式读取文件
2. 工作库
同样,我们可以使用以下命令将训练好的模型保存在 JobLib 中。
" />
import joblib<br /># save the model <br />filename = 'final_model.sav'<br />joblib.dump(model, filename)<br />
我们也可以稍后重新加载这些保存的模型来预测新数据。
# load the model from disk<br />load_model = joblib.load(filename)<br />result = load_model.score(X_test, Y_test)<br />print(result)<br />
用户手册地址
让我们从几个方面解读用户手册[7]。
时间和内存限制
auto-sklearn 的一个关键特性是限制允许 scikit-learn 算法使用的资源(内存和时间)。特别是对于大型数据集(算法可能需要数小时和机器交换),一定要在一段时间后停止评估,以便在合理的时间内取得进展。因此,设置资源限制是优化时间和可测试模型数量之间的权衡。
虽然 auto-sklearn 减轻了手动超参数调整的速度,但用户仍然需要设置内存和时间限制。大多数现代计算机上的 3GB 或 6GB 内存限制对于大多数数据集来说已经足够了。由于时间紧迫,很难给出明确的指导方针。如果可能,一个好的默认设置是总时间限制为一天,单次运行时间限制为 30 分钟。
更多指南可以在 auto-sklearn/issues/142[8] 中找到。
限制搜索空间
除了使用所有可用的估计器之外,还可以限制 auto-sklearn 的搜索空间。以下示例显示如何排除所有预处理方法并将配置空间限制为仅使用随机森林。
import autosklearn.classification<br /><br />automl = autosklearn.classification.AutoSklearnClassifier(<br /> include_estimators=["random_forest",], <br /> exclude_estimators=None,<br /> include_preprocessors=["no_preprocessing", ], <br /> exclude_preprocessors=None)<br /><br />automl.fit(X_train, y_train)<br />predictions = automl.predict(X_test)<br />
注意:用于标识估计器和预处理器的字符串是不带 .py 的文件名。
关闭预处理
auto-sklearn中的预处理分为数据预处理和特征预处理。数据预处理包括分类特征的单热编码、缺失值的插补以及特征或样本的归一化。目前无法关闭这些步骤。特征预处理是一个单一的特征转换器,可以实现例如特征选择或将特征转换到不同的空间(如 PCA)。如上例所示,可以通过设置 include_preprocessors=["no_preprocessing"] 来关闭特征预处理。
重采样策略
可以在 auto-sklearn/examples/ 中找到使用 holdout 数据集和交叉验证的示例。
结果检查
Auto-sklearn 允许用户检查训练结果并查看相关统计数据。以下示例显示如何打印不同的统计信息以进行相应检查。
import autosklearn.classification<br /><br />automl = autosklearn.classification.AutoSklearnClassifier()<br />automl.fit(X_train, y_train)<br />automl.cv_results_<br />automl.sprint_statistics()<br />automl.show_models()<br />
并行计算
auto-sklearn 通过共享文件系统上的数据共享支持并行执行。在这种模式下,SMAC 算法通过在每次迭代后将其训练数据写入磁盘来共享其模型的训练数据。在每次迭*敏*感*词*始时,SMAC 加载所有新发现的数据点。我们提供了一个实现 scikit-learn 的 n_jobs 功能的示例,以及一个关于如何手动启动多个 auto-sklearn 实例的示例。
在默认模式下,auto-sklearn 已经使用了两个内核。第一个用于模型构建,第二个用于在每次新的机器学习模型完成训练时构建集成。序列示例显示了如何一次只使用一个内核按顺序运行这些任务。
此外,根据 scikit-learn 和 numpy 安装,模型构建过程最多可以使用所有内核。这种行为是 auto-sklearn 所不希望的,很可能是由于从 pypi 安装 numpy 作为二进制轮(参见此处)。做 export OPENBLAS_NUM_THREADS=1 应该禁用此行为并使 numpy 一次只使用一个核心。
香草自动sklearn
auto-sklearn主要基于scikit-learn的封装。因此,可以遵循 scikit-learn 中的持久性示例。
要在高效且稳健的自动机器学习材料中使用 vanilla auto-sklearn,请设置 ensemble_size=1 和 initial_configurations_via_metallearning=0。
import autosklearn.classification<br />automl = autosklearn.classification.AutoSklearnClassifier(<br /> ensemble_size=1, initial_configurations_via_metalearning=0)<br />
整体大小为 1 将导致始终选择在验证集上具有最佳测试性能的单个模型。将初始配置 meta-learn 设置为 0 将使 auto-sklearn 使用常规 SMAC 算法来设置新的超参数配置。
参考文献[1]
高效且强大的自动化机器学习:
[2]
Auto-sklearn官方文档:
[3]
AutoSklearnClassifier:#classification
[4]
AutoSklearnRegressor:#regression
[5]
声纳数据集:
[6]
汽车*敏*感*词*集:
[7]
用户手册:#manual
[8]
自动学习/问题/142:
[9]
[10]
往期精彩回顾<br data-darkmode-bgcolor-16019459903493="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16019459903493="rgb(255, 255, 255)" data-darkmode-color-16019459903493="rgb(163, 163, 163)" data-darkmode-original-color-16019459903493="rgb(0, 0, 0)" data-darkmode-bgcolor-16359090834904="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16359090834904="#fff|rgb(255, 255, 255)" data-darkmode-color-16359090834904="rgb(163, 163, 163)" data-darkmode-original-color-16359090834904="#fff|rgb(0, 0, 0)|rgb(62, 62, 62)|rgb(0, 0, 0)|rgb(51, 141, 175)|rgb(0, 0, 0)" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br data-darkmode-bgcolor-16019459903493="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16019459903493="rgb(255, 255, 255)" data-darkmode-color-16019459903493="rgb(163, 163, 163)" data-darkmode-original-color-16019459903493="rgb(0, 0, 0)" data-darkmode-bgcolor-16359090834904="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16359090834904="#fff|rgb(255, 255, 255)" data-darkmode-color-16359090834904="rgb(163, 163, 163)" data-darkmode-original-color-16359090834904="#fff|rgb(0, 0, 0)|rgb(62, 62, 62)|rgb(0, 0, 0)|rgb(51, 141, 175)|rgb(0, 0, 0)" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br data-darkmode-bgcolor-16019459903493="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16019459903493="rgb(255, 255, 255)" data-darkmode-color-16019459903493="rgb(163, 163, 163)" data-darkmode-original-color-16019459903493="rgb(0, 0, 0)" data-darkmode-bgcolor-16359090834904="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16359090834904="#fff|rgb(255, 255, 255)" data-darkmode-color-16359090834904="rgb(163, 163, 163)" data-darkmode-original-color-16359090834904="#fff|rgb(0, 0, 0)|rgb(62, 62, 62)|rgb(0, 0, 0)|rgb(51, 141, 175)|rgb(0, 0, 0)" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br data-darkmode-bgcolor-16019459903493="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16019459903493="rgb(255, 255, 255)" data-darkmode-color-16019459903493="rgb(163, 163, 163)" data-darkmode-original-color-16019459903493="rgb(0, 0, 0)" data-darkmode-bgcolor-16359090834904="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16359090834904="#fff|rgb(255, 255, 255)" data-darkmode-color-16359090834904="rgb(163, 163, 163)" data-darkmode-original-color-16359090834904="#fff|rgb(0, 0, 0)|rgb(62, 62, 62)|rgb(0, 0, 0)|rgb(51, 141, 175)|rgb(0, 0, 0)" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑<br data-darkmode-bgcolor-16019459903493="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16019459903493="rgb(255, 255, 255)" data-darkmode-color-16019459903493="rgb(39, 84, 255)" data-darkmode-original-color-16019459903493="rgb(2, 30, 170)" data-darkmode-bgcolor-16359090834904="rgb(25, 25, 25)" data-darkmode-original-bgcolor-16359090834904="#fff|rgb(255, 255, 255)" data-darkmode-color-16359090834904="rgb(39, 84, 255)" data-darkmode-original-color-16359090834904="#fff|rgb(0, 0, 0)|rgb(62, 62, 62)|rgb(0, 0, 0)|rgb(51, 141, 175)|rgb(0, 0, 0)|rgb(2, 30, 170)" style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />AI基础下载机器学习交流qq群955171419,加入微信群请扫码:
核心方法:网站标题seo怎么写?网站标题关键词写法规范-网站SEO标题分析工具
网站标题seo,网站标题怎么写?网站标题的作用是什么?网站的标题决定了你网站的排名,为什么这么说呢。因为搜索引擎通过识别标题来识别你网站的主题和你网站的类型。同样,如果用户看到您的标题没有焦点,他们也不会点击进入。所以现在你知道标题的重要性了。
常规标题写作技巧:
1.标题核心词-标题核心词2-标题核心词3-品牌词
2、标题核心词-吸引用户的词-品牌词
为什么我的标题区间符号是:“-” 因为百度官方说统计区间符号是单杠。这是一个关于如何写标题的教程。使用这个免费的SEO工具,你只需要输入一个标题词,自动
" target="_blank">采集
页面排名的所有标题。我们只需要将这些数据导出到表中,进行分析,创建自己的标题写法即可。(注意:标题一般不要超过30个字符)
一个新站想快速对其网站进行排名。方法其实很简单。只要认真按照我的方法去做,一定会有效果的。那到底是什么方法这么厉害呢?
网站处于什么阶段?
想要做好网站关键词排名,就像病人去看病一样。如果医生不明白他的病人怎么了,他就开药,有意识地打针。会发生什么?影响?连我们自己都不了解我们的网站,它现在是一个什么样的状态,我们该如何优化呢?因此,在前期,我们需要对网站进行阶段性判断。首先简单定位一下,可以分为初级、中期、高级3个阶段。阶段制定不同阶段的优化方法)。
新站的优化方法应该在什么阶段?有基础的朋友,新站应该知道属于前期,也就是初期优化阶段。我们应该如何开始这个初级优化阶段?为了让更多的朋友看得清楚,李勇简单地将这个初步的优化过程分成了4个小部分给大家。请继续仔细阅读。
1、分析新站的用户群体
做网站首先要知道谁会访问我们的网站?他们为什么访问我们的网站?只有在你对你的网站用户有了详细的了解之后,你才能进行下一步,为他们提供有价值的内容。比如李勇的SEO博客访问者一般都是站长或者研究SEO的人,或者是做营销推广的人。他们为什么来访问李勇的SEO博客?因为这个博客上有他们需要的内容!
2. 选择网站所有者 关键词
" />
一个网站主机关键词就相当于我们的名字,关键词的索引就相当于我们的人气,所以我们尽量选择最热门的,选择那个主机关键词我们确定(可以排名的是关键词),就像我的博客一样,主关键词是李勇SEO博客,因为我是做个人品牌的,所以你懂的,辅助的关键词包括合肥seo、合肥网站优化、合肥seo培训等,选择网站关键词可以说是看你提供的服务。如果你想做品牌,那没关系,主关键词就写你的品牌,如果你不是品牌,纯粹为了流量,建议选主关键词 有交通。
3.定位网站栏目分类
当用户进入你的网站时,他们基本上会查看你网站上的栏目,看是否有他们想看的内容,内容应该在那个栏目中。比如你去超市,如果你是买菜的话,你会直接去卖菜的地方。如果是买日用品,应该到卖日用品的地方去。网站栏目的分类我们要根据用户的需求来定位。
仍然需要充分理解基本理论。这里需要注意的是,学习SEO优化方法需要与时俱进,紧跟搜索引擎的脚步。网上很多理论都与百度的算法渐行渐远。如果你认为自己已经掌握了 SEO 而停滞不前,你就会落后于“时间”。另外,我们需要找到最好的seo学习网站,这个怎么说呢?很多时候seo是一件很随意的事情,大家可以谈一谈,哪些是有根据的,哪些是典型的seo谬论,需要仔细甄别。高效学习SEO的精髓也在这里。
关键词 是网站必不可少的东西。首先分析关键词的竞争力和搜索热度,准确识别长尾关键词。通常有两种新手。思路是专注于关键词,比如线上推广关键词,直接优化线上推广关键词。为什么?因为这个词有很多搜索量,但是有这样的想法。对于初学者来说,我想说的是,搜索量越大的关键词会更有竞争力,也更难优化,无法以吸引准确的客户,这些客户通常是长期搜索者。来自于结尾关键词,比如在前面加一个地区名“中山网络推广外包”,另一个想法是优化那些没有搜索量的词,为什么?因为这个词没有竞争力,每分钟都是优化的第一名,但是对于有这种想法的新手,我只想说,如果餐厅建在没有人的山顶上,还会有客人吗来吃饭?没有竞争力,没有搜索量,白费那么多力气做什么?

