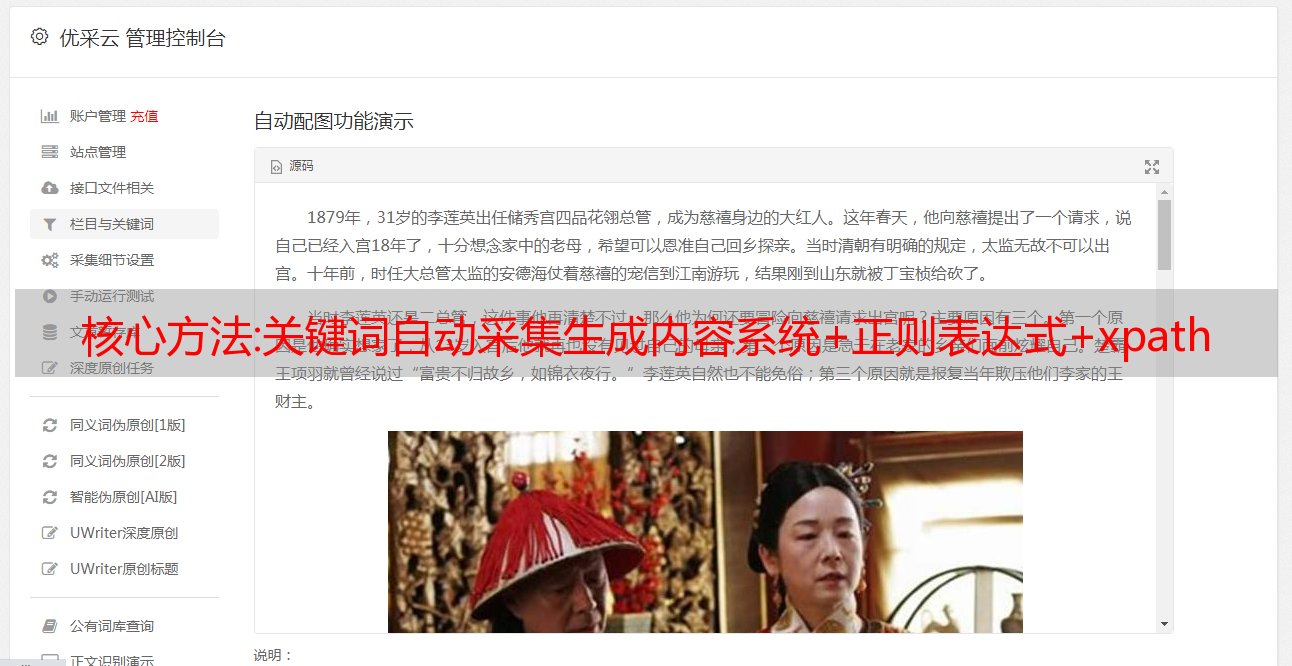
核心方法:关键词自动采集生成内容系统+正则表达式+xpath
优采云 发布时间: 2022-11-21 17:29 核心方法:关键词自动
" target="_blank">采集
关键词自动采集生成内容系统爬虫+正则表达式+xpath完成网站爬虫并自动生成代码
一般,直接使用代理,通过服务器的ip来解析网页。
因为国内带宽小,现在用代理爬虫爬海外的内容已经越来越少,个人一般是通过爬虫爬国内的,然后用xpath标注下关键词。如果有爬虫爬,想不到拿到怎么处理。如果有爬虫爬,想不到怎么办。
直接采集对方网站的js代码做样式处理或者把页面快照发送到对方网站的开发者平台去
抓包分析数据结构,改数据库数据库查询。
代理爬虫
代理referer的爬虫用jsoup
抓包啊
直接采集,速度快,而且大多是国外电影。

" />
抓包。
抓包分析数据结构,
抓包,抓包分析数据结构,改数据库数据库查询。我只用jsoup。
现在就需要爬虫来处理海外电影的html源代码,不过你说的爬虫爬取,应该是指googlecrawler那种吧?代码也很简单,可以看看你要的电影的html源代码,然后googlecrawler,选择需要的html源代码,并且设置代理,就能抓取下来了。jsoup用不上,因为jsoup大部分都是小电影啊。
1.目标网站无法抓取,那就用代理抓取方式抓取,代理是国内的,国外的用fiddler2或者proxycache,用国内的话比较麻烦2.目标网站已经抓取了,还得想办法抓取不限量的,那就用爬虫方式,找到解析xpath的库,比如爬虫之家的spider,可以去fiddler插件网找到破解spider。3.目标网站抓取到了,还得让它有高清的mp4或者avi,那就用正则表达式,csv,mp4都可以匹配出来。

