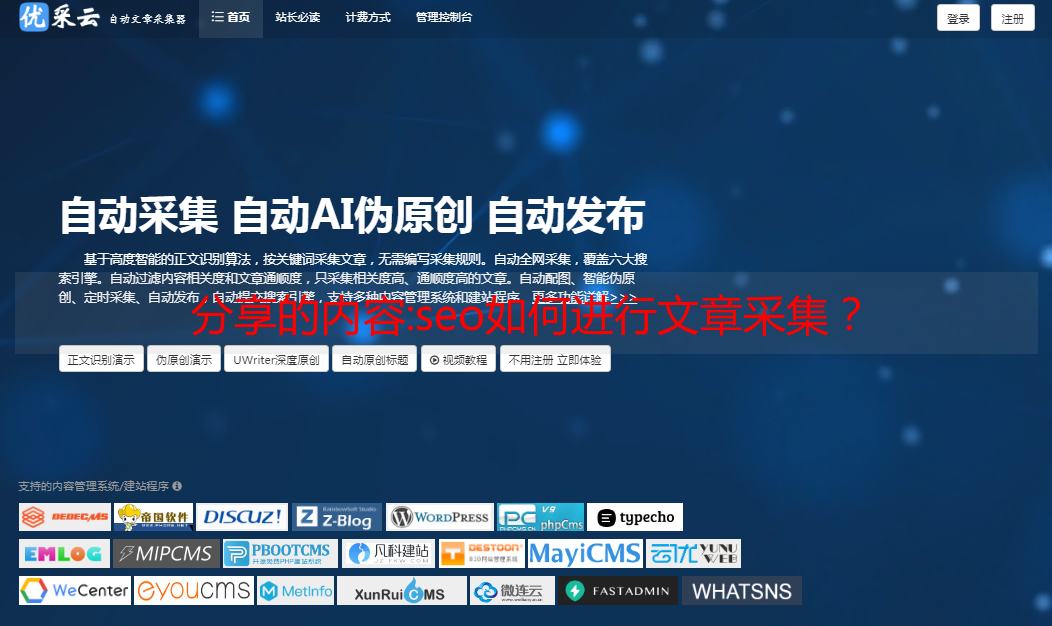
分享的内容:seo如何进行文章采集?
优采云 发布时间: 2022-11-20 00:09 分享的内容:seo如何进行文章
" target="_blank">采集
如果您的站点是新站点,请在上线后立即采集
。获得流量的唯一方法是拥有足够的外部链接。通常对于百度来说,只要没人举报你,它就能发展得很快。
但是很多人采集
的时候,什么都不改,就是采集
。这种情况比较困难。对于纯粹采集
的内容,搜索引擎阻止您的页面被收录的原因至少有两个:
1、内容过于重复
纯藏品的藏品来源单一,内容往往具有较高的重复性。对于搜索引擎来说,重复的内容=垃圾。
2.一次采集
,即可获得上千W条内容

" />
搜索引擎工程师不是自由职业者。别人做网站一年可能没有10000条内容,但是你一天可以做到10000条内容。不是采集
是什么?
所以想要采集
,不能一次采集
太多,更不能选择单一的采集
来源。
这时候你要考虑一件事,你打算把这个网站运营多久?减少采集
量,平均分配到每一天。对于采集源的选择,我建议网站每个栏目选择不同的采集源。不要为整个网站采集
一个网站的内容。这样的话,重复的程度就会很高。
关于采集源的选择:
1.至少3~5个备份采集源
建议每个栏目采集不同的网站,所以需要为不同的栏目准备3到5个不同的网站采集源。
" />
2.找文章
从准备好的几个合集资源中,随便挑一篇文章,复制其中的一句话,在百度或谷歌上搜索。
3.看结果
只要有这篇文章的网站都会列出来,然后你会看到很多同标题的网页,但是要小心!还有一些编辑手动调整了标题,嘿嘿!我们的目标是采集
这些页面。手工编辑的网站。
还有一点需要注意的是,如果做站内链接,一篇文章最好有3个内链,外链不要超过2个,否则文章根本没有重量。提一下我之前写的,关于增加内链页面权重的方法,有兴趣的朋友可以看看。
教程:浅谈Python网络爬虫
(2) 数据分析:了解HTML结构、JSON和XML数据格式、CSS选择器、XPath路径表达式、正则表达式等,以便从响应中提取出需要的数据;
(3)数据存储:MySQL、SQLite、Redis等数据库方便数据存储;
相关技术
以上就是学习爬虫的基本要求。在实际应用中,还要考虑如何使用多线程来提高效率,如何做任务调度,如何应对反爬虫,如何实现分布式爬虫等等。本文介绍有限,仅供参考。
六个python相关的库
在爬虫实现方面,除了scrapy框架,python还有很多相关的库可以使用。其中,数据抓取包括:urllib2(urllib3)、requests、mechanize、selenium、splinter;数据分析包括:lxml、beautifulsoup4、re、pyquery。
对于数据抓取,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,常见的类型有:get/post。其中urllib2(urllib3)、requests、mechanize用于获取url对应的原创响应内容;而selenium和splinter通过加载浏览器驱动获取浏览器渲染后的响应内容,具有更高的仿真度。
选择哪个类库要根据实际需要来决定,比如考虑效率,对方的反爬虫手段等。平时如果能用urllib2(urllib3),requests,mechanize等就尽量不要用selenium 和 splinter,因为后者由于需要加载浏览器而效率较低。
对于数据分析,主要是从响应页面中提取需要的数据。常用的方法有:xpath路径表达式、CSS选择器、正则表达式等。其中xpath路径表达式和CSS选择器主要用于提取结构化数据,而正则表达式主要用于提取非结构化数据。对应的库有lxml、beautifulsoup4、re、pyquery。
类库
文档
数据抓取
网址库2
要求
机械化
碎片
硒
数据分析
lxml
美丽的汤4
回覆
查询
相关图书馆文件
七、相关介绍
1 数据采集
(1) urllib2
urllib2是python自带的访问网页和本地文件的库。一般需要和urllib一起使用。因为urllib提供了urlencode方法对发送的数据进行编码,而urllib2没有对应的方法。
下面介绍urllib2的简单封装,主要是将相关特性集中在一个类函数中,避免一些繁琐的配置工作。
urllib2 包说明
(2) 请求和机械化
requests是一个Python的第三方库,基于urllib,但是比urllib更方便,接口也简单。它的特性包括,关于http请求:支持自定义请求头,支持设置代理,支持重定向,支持维护session[request.Session()],支持超时设置,post数据自动urlencode;关于http响应:无需手动配置,直接访问响应中获取详细数据,包括:状态码、自动解码的响应内容、响应头中的各个字段;还有一个内置的 JSON *敏*感*词*。
mechanize是urllib2部分功能的替代品,可以更好的模拟浏览器行为,在web访问控制方面做的非常全面。其功能包括:支持cookie设置、代理设置、重定向设置、简单表单填写、浏览器历史记录和重新加载、添加referer headers(可选)、自动遵守robots.txt、自动处理HTTP-EQUIV和刷新等。
简单封装requests和mechanize后的接口和urllib2是一样的,相关的特性也集中在一个类函数中。此处不再赘述,可参考给出的代码。
(3) 分裂和硒
Selenium (python) 和 splinter 可以很好地模拟浏览器行为,它们都是通过加载浏览器驱动来工作的。采集信息方面,减少了分析网络请求的麻烦,一般只需要知道数据页对应的URL即可。由于需要加载浏览器,效率比较低。
默认情况下,首选 Firefox 浏览器。这里有chrome和pantomjs(无头浏览器)驱动的下载地址,方便搜索。
Chrome和pantomjs驱动地址:
铬合金:
pantomjs:
2 数据分析
对于数据解析,可用的库有 lxml、beautifulsoup4、re、pyquery。其中beautifulsoup4比较常用。除了这些库的使用,你还可以了解xpath路径表达式、CSS选择器、正则表达式的语法,方便从网页中提取数据。其中,chrome浏览器自带生成XPath的功能。
chrome查看元素的xpath
如果能够根据网络分析抓取到所需数据对应的页面,那么从页面中提取数据的工作就相对清晰了。具体使用方法请参考文档,这里不再详细介绍。
八防爬虫
1、基本的反爬虫方法主要是检测请求头中的字段,如:User-Agent、referer等,这种情况下,只要在请求中收录相应的字段即可。构造的http请求的各个字段最好和浏览器发送的完全一致,但不是必须的。
2、基于用户行为的反爬虫方法主要是在后台统计访问的IP(或User-Agent),超过一定的设定阈值就进行拦截。针对这种情况,可以通过使用代理服务器来解决,每隔几次请求切换所使用的代理的IP地址(或者使用User-Agent列表,每次从列表中随机选择一个)。这样的反爬虫方式可能会误伤用户。
3、如果你要抓取的数据是通过ajax请求获取的,如果你能通过网络分析找到ajax请求,分析出请求需要的具体参数,那么直接模拟对应的http请求,从对应的response中获取数据。在这种情况下,它与普通请求没有什么不同。
4、基于Java的反爬虫方式主要是在响应数据页面之前返回一个带有Java代码的页面,用于验证访问者是否具有Java执行环境,从而判断是否使用了浏览器。
通常,这段JS代码执行后,会发送一个带有参数key的请求,后台会通过判断key的值来决定响应的是真实页面还是假冒错误页面。因为key参数是动态生成的,每次都不一样,所以很难分析它的生成方式,导致无法构造出对应的http请求。
比如网站就是这样使用的,详见。
第一次访问网站时,响应的JS内容会发送一个带有yundun参数的请求,每次的yundun参数都不一样。
动态参数云盾
目前测试中,Java代码执行后,发送的请求不再带yundun参数,而是动态生成一个cookie,并在后续请求中携带cookie,与yundun参数类似。
动态cookie
对于这样的反爬虫方法,爬虫需要能够解析并执行Java。具体方法可以通过使用selenium或者splinter加载浏览器来实现。

