最新版本:歪碰网站外链增加工具 v1.3 网站优化
优采云 发布时间: 2022-11-19 23:12最新版本:歪碰网站外链增加工具 v1.3 网站优化
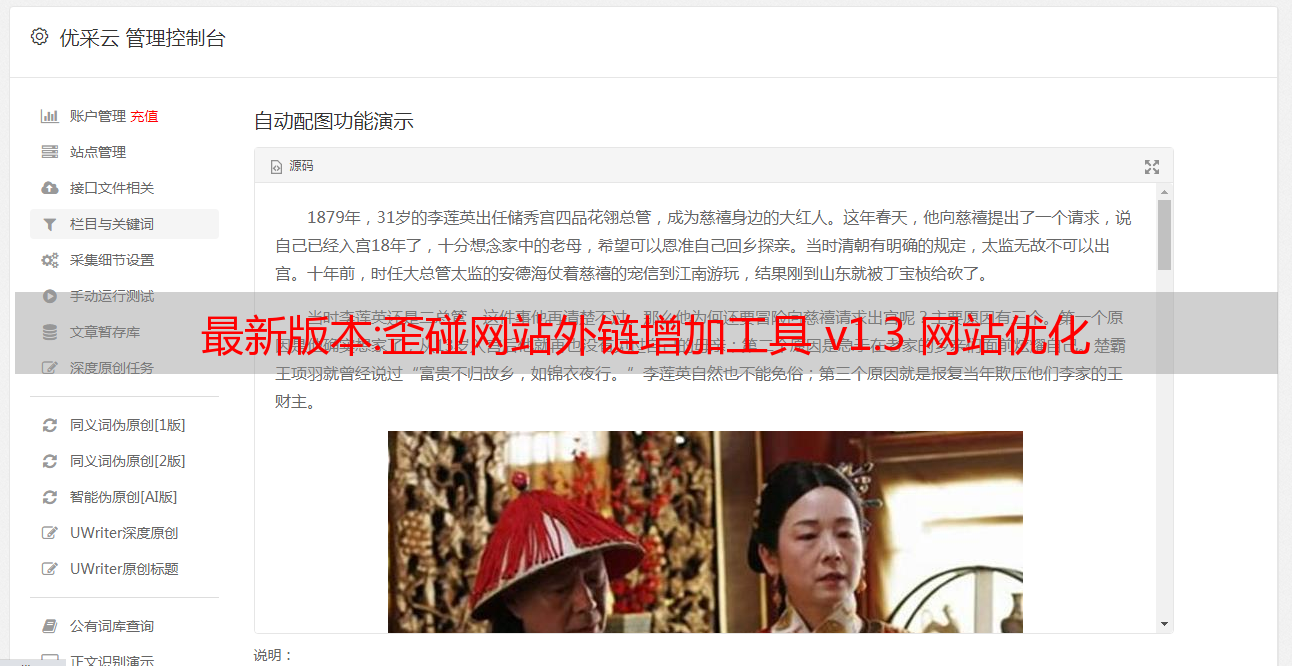
网站外链添加工具是一款自动添加网站外链的工具,简单易用。外鹏网站外链添加工具集成了ip查询、Alexa排名查询、pr查询等站长常用的各种搜索站点,因为这些站点大部分都有展示查询记录的功能,查询记录可以通过百度、谷歌、搜狗等搜索引擎。迅速收录,从而形成外链。因为这是一个正常查询生成的外部链接,这个外部链接可以显着增加索引,提高搜索引擎排名。
外鹏网站添加外链工具常见问题解答:
1、使用该工具增加外鹏网站的外链是否算做搜索引擎优化作弊?
外鹏网站添加外链工具只是一个简单的综合查询工具,模拟正常人工查询,不作弊。如果是作弊,那么可以利用工具增加外鹏网站的外链,推广竞争对手的网站,让它获得K。

" />
2、单纯依靠网站加外链和单向链接工具来优化网站是否可行?
网站优化不能简单的靠工具给网站加外链。需要结合普通外链和友情链接。可以在各大百科网站发布词条,在友情链接平台交换友情链接。
3、如何使用外鹏网站的外链增加工具达到更好的效果?
外朋网站增加外链的工具不同于普通的外链。它是一个动态链接。只有经常使用外喷网站的外链添加工具进行优化,才能获得稳定的外链,最终使搜索引擎收录带有URLs页面的查询。
更新日志
歪网站外链添加工具V1.0 Build 111009
1.发布高质量版本。
要运行该程序,必须安装 .Net FrameWork 2.0 或更高版本。
最新版本:2-网站日志分析案例-基于Flume
" target="_blank">采集
文章目录 4.总结2-网站日志分析案例-基于水槽采集
WEB日志-视窗版本 1.水槽介绍
Flume 是一种分布式、可靠且可用的服务,用于高效采集
、聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有强大的容错能力,具有可调的可靠性机制和许多故障转移和恢复机制。它使用一个简单的可扩展数据模型,允许在线分析应用。
翻译:Flume 是一种分布式、可靠且可用的服务,用于高效采集
、聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调的可靠性机制以及许多故障转移和恢复机制,以实现稳健性和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
2.在Windows环境中安装Flume
1. 需要配置本地JAVA_HOME2.下载
水槽页面,我下载的版本是1.9.0
3. 启动命令测试
D:\apache\apache-flume-1.9.0-bin\apache-flume-1.9.0-bin\bin>flume-ng version
复制
安装简单。
3. 在基于Flume的Windows下完成日志采集
3.1过程
源类型选择:
因为窗口下没有 tail 命令,无法监控单个文件,需要通过 spooldir 监控日志目录 通道类型选择:为快捷方便,选择内存*敏*感*词* 类型选择:使用记录器和file_roll,其中记录器file_roll实现日志文件迁移,以检查是否成功
3.2 具体配置
# 配置agent1的三个组件
agent1.sources = source1
agent1.sinks = sink1 sink2 sink3
agent1.channels = channel1
# Describe/configure spooldir source1
agent1.sources.source1.channels = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = E://log
agent1.sources.source1.inputCharset = GBK
agent1.sources.source1.fileHeader = true
<p>
" />
#configure host for source
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# Describe sink1 file_roll
agent1.sinks.sink1.channel = channel1
agent1.sinks.sink1.type = file_roll
agent1.sinks.sink1.sink.directory = D://flume-collection
agent1.sinks.sink1.sink.rollInterval = 60
# Describe sink2
agent1.sinks.sink2.channel = channel1
agent1.sinks.sink2.type = logger
# Describe sink3
agent1.sinks.sink3.channel = channel1
agent1.sinks.sink3.type = hdfs
agent1.sinks.sinks.hdfs.useLocalTimeStamp = true
agent1.sinks.sink3.hdfs.path = /sx/logtable/%Y-%m-%d
agent1.sinks.sink3.hdfs.filePrefix = logevent
agent1.sinks.sink3.hdfs.rollInterval = 10
agent1.sinks.sink3.hdfs.rollSize = 134217728
" />
agent1.sinks.sink3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600</p>
复制
3.3 启动
D:\apache\apache-flume-1.9.0-bin\apache-flume-1.9.0-bin>.\bin\flume-ng agent --conf conf --conf-file conf\log2file.conf --name agent1 -property flume.root.logger=INFO,console
复制D:\apache\apache-flume-1.9.0-bin
\apache-flume-1.9.0-bin>.\bin\flume-ng agent --conf conf --conf-file conf\log2file.conf --name agent1 -property flume.root.logger=INFO, console
3.4 注意事项
1.需要确定读取日志文件的编码格式,默认读取格式为
UTF-8,如果编码不是默认的,则需要手动修改,如果编码格式不正确,可能会出现:
FATAL: Spool Directory source source1: { spoolDir: E://log }: Uncaught exception in SpoolDirectorySource thread. Restart or reconfigure Flume to continue processing.
java.nio.charset.MalformedInputException: Input length = 1
复制
2.agent1.sinks.sink1.sink.directory = D://flume-采集
,注意配置的键是sink.directory,否则会出现
Directory may not be null
复制
错误
4. 总结
本文主要基于 Flume 实现日志采集,这个案例并不复杂,但由于基于 Windows 实现的案例并不多,笔者试图在博客中描述自己遇到的问题,包括编码问题和配置注意事项,降低试错成本。

