采集器采集 最新信息:猫眼电影新闻资讯列表信息
优采云 发布时间: 2022-11-19 02:15采集器采集 最新信息:猫眼电影新闻资讯列表信息
本文介绍优采云采集器采集猫眼电影网新闻信息列表信息。操作流程如下:
步骤1:下载优采云采集器并在安装完成后打开软件
在软件起始页上,在“自定义采集”中输入 URL 或直接输入“新建”
步骤 2:抓取数据
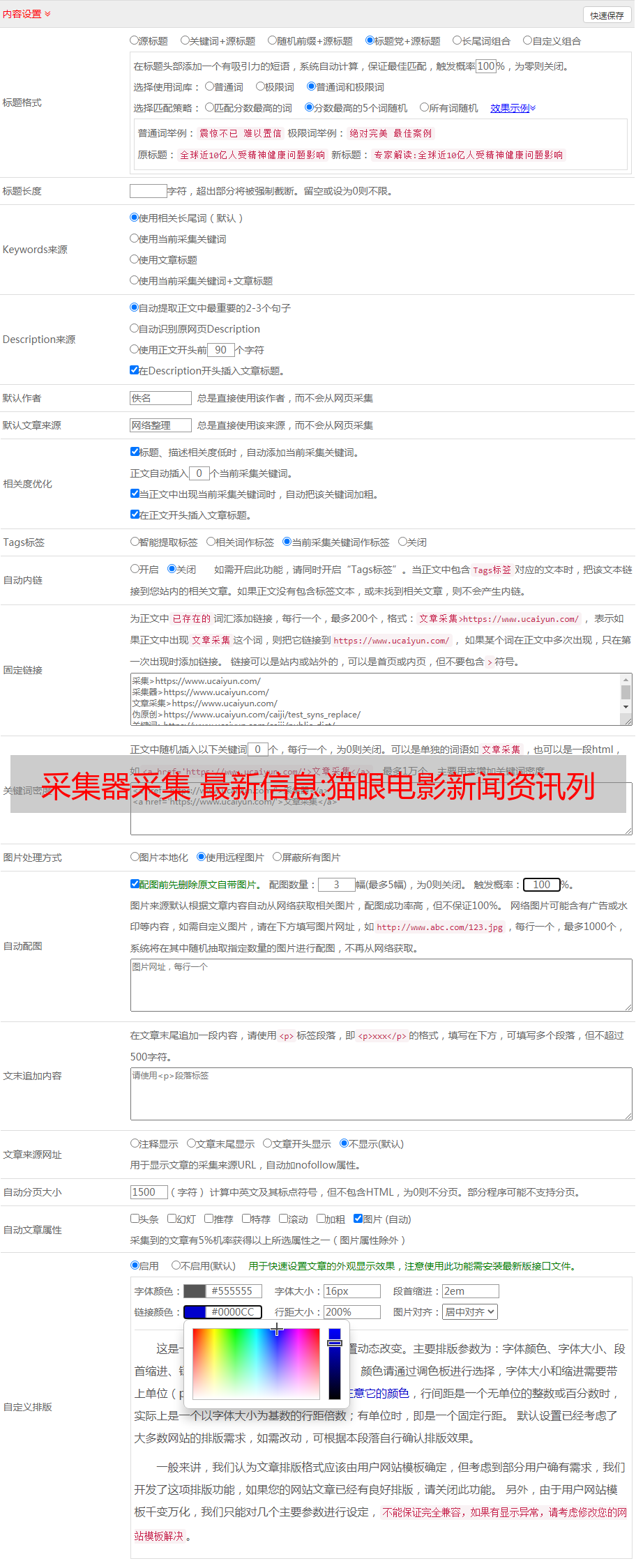
采集器列表数据的自动识别,因为采集页面很多,需要设置如下:“自动识别分页”(也可以自定义添加列表和修改标题名称)接下来,直到完成。
步骤 3:加载数据任务
列表:选择任务/右键单击/启动采集
从日志中,您可以看到加载的进程
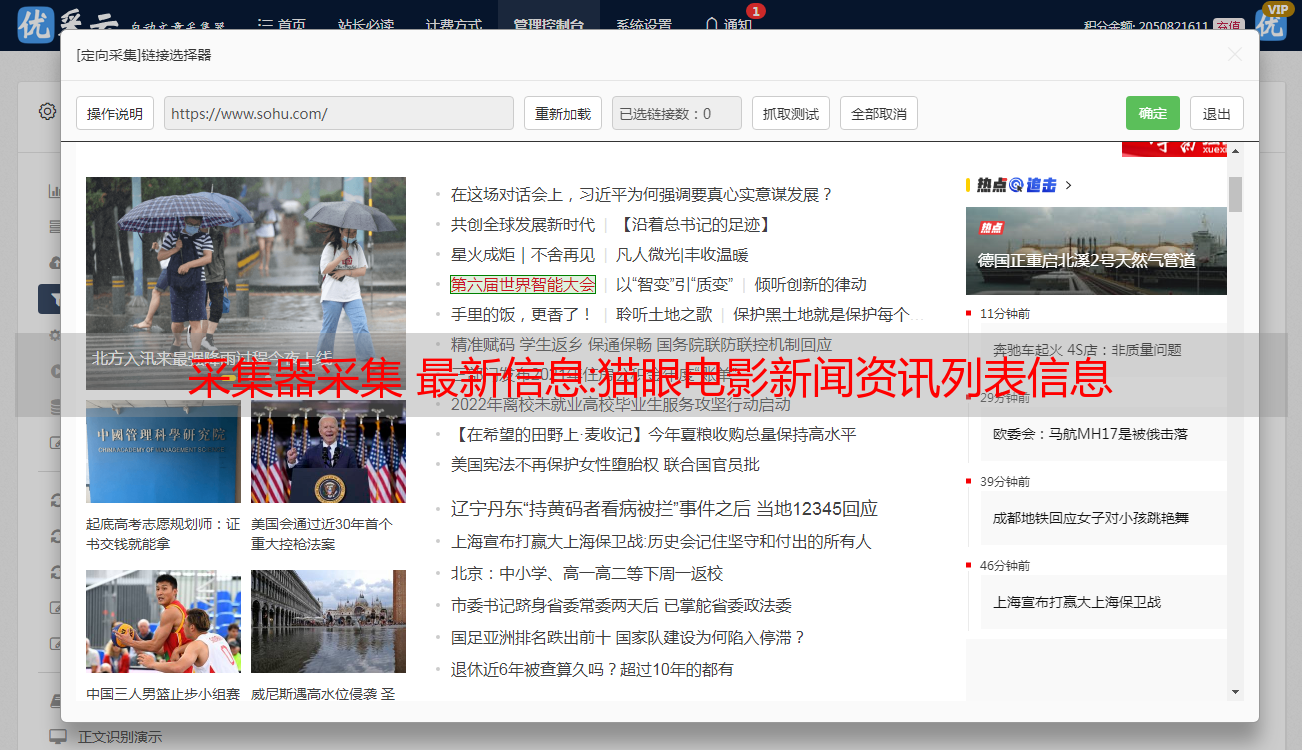
点击数据按钮,直接预览正在加载的数据
步骤 4:查看和保存数据 在任务中
列表:选择任务/单击“查看”导出数据
汇总:微信公众号数据采集
微信公众号资料采集目录1,采集公众号文章URL1。运行环境 1.Webdriver2.python运行环境 3.cx-oracle4.lxml 5.注册微信公众号 2.采集文章连接 1.配置config.txt2。启动程序2。 采集文章详细信息 1. 配置detail_config.txt2。启动程序3.数据1.数据库2.execl最近统计了感兴趣的公众号的阅读数据。这个文章会记录执行过程。本文仅供学习交流之用,请勿用于其他用途。1. 采集公众号文章URL 主要考虑这个程序。
大家好,我是建筑先生,一个会写代码会吟诗的架构师。今天说说微信公众号资料采集,希望能帮助大家进步!!!
目录
近期,我们统计了感兴趣公众号的阅读数据。这个文章会记录执行过程。本文仅供学习交流之用,请勿用于其他用途。
1. 采集公众号文章网址
这个程序的主要考虑是在window下运行。运行前,请确保您已经具备python的基本运行环境和相关的python插件。
一、运行环境 1、Webdriver
确保窗口环境有谷歌浏览器。如果您使用的谷歌浏览器版本不知道支持程序中提供的webdriver,有以下解决方案:
一种是在你的电脑上下载对应google浏览器版本的webdriver
二是安装文件中提供的gongle浏览器
三是自己找其他浏览器对应的webdriver(这里不推荐这个,除非你能解决你遇到的问题)
2.python运行环境
python版本>=3.6
3.cx-甲骨文
5.3版本 此版本对应服务器上oracle数据库版本11g,其他版本无法连接
pip 安装 oracle==5.3
4.lxml
execl文件操作需要的插件
pip 安装 lxml
5.注册一个微信公众号
你可以使用你已经拥有的
2. 采集文章 连接 1. 配置config.txt
该文件可以配置多个公众号,程序会下载配置好的公众号的文章url采集。注意格式是:
每个公众号一行
公众号名称开始时间结束时间
即采集的公众号名称,采集的开始时间和结束时间为必填项,以空格分隔,程序只会保存开始时间内的文章数据和结束时间。
2.启动程序
点击JZTravel_Artical_Url.bat,扫描微信,登录自己的微信公众号。登录成功后,您将进入微信公众号页面。不要关闭这个页面,因为程序会自动退出这个页面。页面退出后,程序将采集文章url。
程序运行后会在data文件夹下生成对应的文件,里面存放了需要采集的微信公众号文章的url。
注意:登录过程中,可能会出现如下错误,不用担心,这可能是当前网络问题,导致页面数据加载不完整,多试几次即可。
2.采集文章的详细信息 1.配置detail_config.txt
采集公众号详情配置文件
注意:由于cookie的原因,该文件只能配置一个公众号信息,需要采集的公众号必须对应cookie中的连接,格式为
公众号名称|数据存储方式
即需要采集的公众号,保存方式用“|”隔开。保存有三种方式,xls——另存为execl,oracle——保存到oracle数据库,other——同时保存到execl文件和oracle数据库。根据实际选择需要。
2.启动程序
点击JZTravel_Artical_Detail.bat,程序会自动生成采集文章详细数据。
注意:
错误一:当程序出现如下错误时,不会影响采集程序,也不会影响采集结果
错误二:当程序出现如下错误时,是cookie失效导致的,需要重新导入cookie数据。不用担心,已经采集的文章数据不会重复采集。
错误三:程序出现如下错误时,爬虫程序写入的Excel文件已经打开,需要关闭文件重新启动。也就是说,爬虫采集打不开execl文件。
3.数据
考虑到爬虫实际运行的网络环境,这里采用了多次数据备份。包括数据本地文件备份和数据库备份。
1.数据库
2.执行
按 采集 日期单独存储。
本文仅供学习交流之用,请勿用于其他用途。技术支持,按钮:3165845957

