解决方案:优采云采集文章列表地址列表错误 URL多了一层网址解决方法
优采云 发布时间: 2022-11-18 20:32解决方案:优采云采集文章列表地址列表错误 URL多了一层网址解决方法
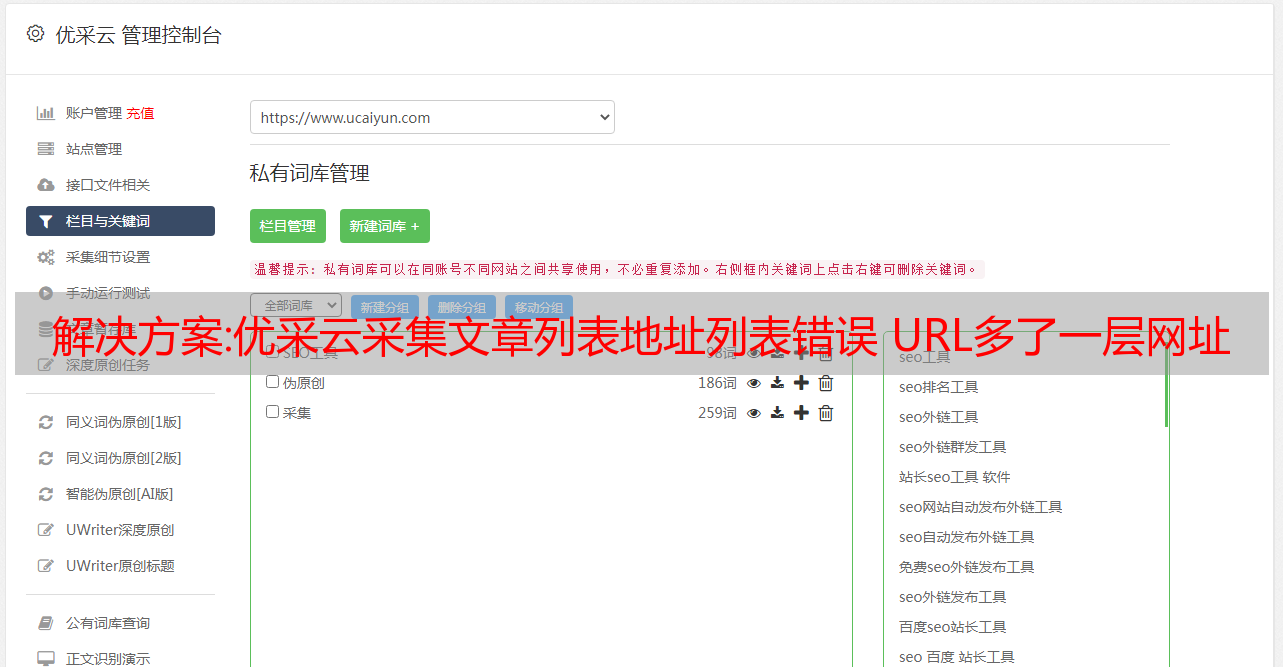
优采云采集文章列表地址列表错误 URL 会添加额外的 URL 解析层
今天我再次打开它优采云采集器我需要更新下一个网站,但是单击“开始”后发现错误。翡翠是重新修订采集规则列表。我没有仔细看,当我捕获 300 多个连接来导入数据库时,我犯了一个错误,并仔细查看了网站的文章列表页面以处理文章 URL 地址。
性能:
URL文章常规文章列表应该是/url.html“>是正确的,而网站处理是取消协议头https或http,这在一定程度上可以阻止很多采集程序、软件、爬虫。采集后,地址列表将具有额外的 URL 层,该层将变为 //url.html以便无法正确采集内容。
解决方法:
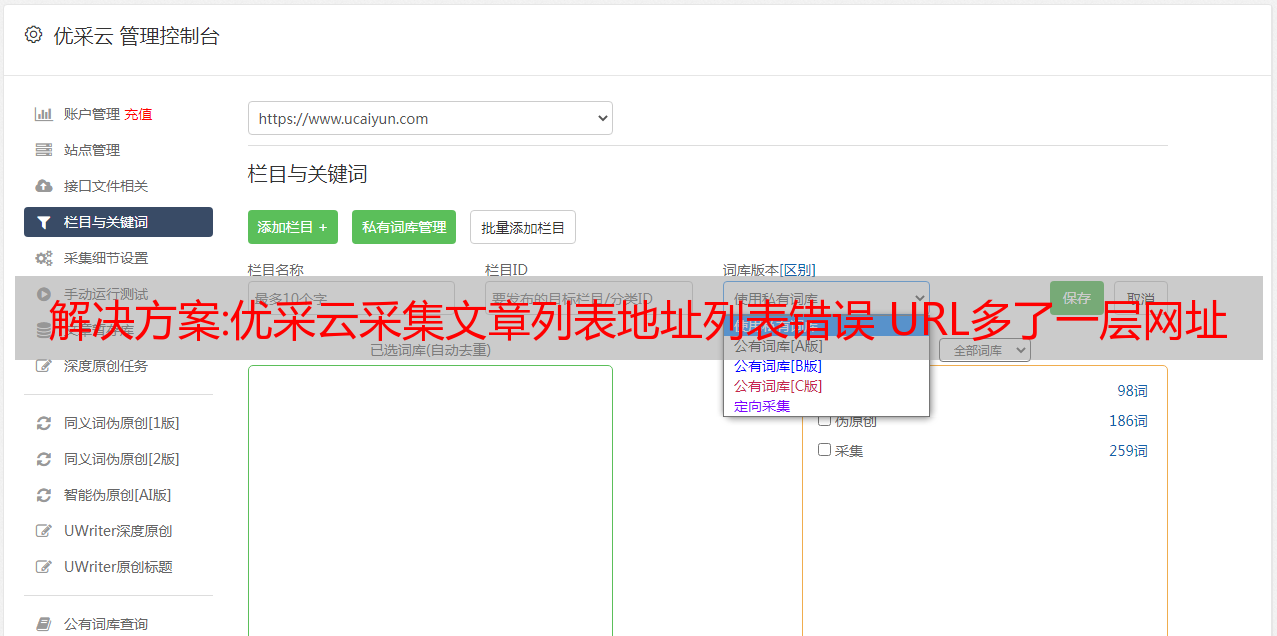
在网址获取选项中,点击“手动填写链接地址规则”
这
右侧的脚本规则填写 [a href=“[参数]” class=“title” target=“_blank”] 此处的参数是没有协议标头的原创 URL。
解决方案:如何用 ELK 搭建 TB 级的日志监控系统?
点击上方的“芋头源代码”,然后选择“””
叫她前波,还是后波?
能挥的波浪就是好浪!
每天8:55更新文章,每天损失1亿发点....
源代码精品栏目
来源: /登邦邦/
p/12961593.html
本文主要介绍如何使用 ELK Stack 帮助我们构建支持 Nissan TB 的日志监控系统。在企业级微服务环境中,运行数百或数千个服务被认为是相对较小的。在生产环境中,日志起着重要作用,例如异常排查、性能优化和服务。
但是,生产环境中运行着数百个服务,每个服务只会简单地存储在本地,并且当日志需要帮助解决问题时,很难找到日志所在的节点。业务日志的数据价值也很难挖掘。
然后将日志统一输出到一个地方进行集中管理,然后对日志进行处理,将结果输出到运维中,以及
开发可用数据是解决日志管理、辅助运维的可行解决方案,也是企业解决日志的迫切需求。
通过以上
要求,我们推出了日志监控系统,如上图所示
功能过程概述如上图所示
(1)我们在日志文件的采集端使用 FileBeat,通过我们的后台管理界面配置运维,每台机器对应一个 FileBeat,每个 FileBeat 日志对应的主题可以是*敏*感*词*、多对一,根据每日日志量配置不同的策略。
除了采集业务服务日志外,我们还采集MySQL慢查询日志和错误日志,以及其他第三方服务日志,如Nginx。
最后,结合我们的自动发布平台,每个 FileBeat 进程都会自动发布并启动。
(2)调用栈、链路、进程监控指标 我们使用代理方式:Elastic APM,这样就不需要改变业务端程序。
对于已经在运行的业务系统,需要更改代码以添加监视是不可取和不可接受的。
Elastic APM 可以帮助我们采集 HTTP 接口的调用链路、内部方法调用栈、使用的 SQL、进程的 CPU、内存使用指标等。
可能有人会疑惑,有了弹性APM,其他日志基本可以采集。为什么使用 FileBeat?
是的,
采集的信息 Elastic APM 确实帮助我们定位了 80% 以上的问题,但并非所有语言(如 C)都支持它。
其次,它无法帮助您采集您想要的非错误日志和所谓的关键日志,例如:调用接口时发生错误,并且您希望查看错误发生时的前后日志;还有与印刷业务相关的日志,可以轻松分析进行分析。
第三,自定义服务例外,属于非系统异常,
属于业务类别,APM会将此类异常上报为系统异常。
如果您稍后对系统异常进行告警,这些异常会干扰告警的准确性,并且您无法过滤业务异常,因为自定义服务异常的类型很多。
(3)同时,我们双开代理。采集更详细的 GC、堆栈、内存、线程信息。
(4)服务器采集我们使用普罗米修斯。
(5)因为我们是SaaS服务化,服务很多,很多服务日志不能统一规范,这也和历史问题有关,一个与业务系统无关的系统间接或直接对接现有的业务系统,为了适应自身,让它改变代码,那是不可推的。
设计是使自己与他人兼容,并将他们视为攻击对象。许多日志是没有意义的,例如:为了便于在开发过程中对跟踪问题进行故障排除,在 if else 中只打印标志性日志,表示 if 代码块或 else 代码块是否消失了。
某些服务甚至打印调试级别日志。在成本和资源有限的条件下,所有的日志都是不切实际的,即使资源允许,一年内也是一笔不小的开支。
因此,我们使用过滤、清理、动态调整日志优先级采集等解决方案。首先,将所有日志采集到 Kafka 集群,并设置较短的有效期。
我们目前设置的是一个小时,一个小时的数据,我们的资源暂时是可以接受的。
(6) 日志流是我们用于日志过滤和清理的流处理服务。为什么选择ETL过滤器?
因为我们的日志服务资源有限,但又不对,原来的日志分散在每个服务的本地存储介质上。
现在我们只是一个集合,采集之后,每个服务上的资源可以释放一些日志占用的资源。
没错,这确实是每个服务对日志服务资源的原创资源分配,并没有增加资源。
但是,这只是理论上的,在线服务,资源扩展容易,缩水就没那么容易,实施难度极大。
因此,将短时间内无法在各项服务上使用的日志资源分配给日志服务。在这种情况下,日志服务的资源是所有服务日志当前使用的资源量。
存储周期越长,资源消耗越大。如果解决一个非商业或不可避免的问题需要在短时间内进行比解决当前问题的好处更大的投资,我认为没有领导者或公司愿意在有限的资金下采用解决方案。
因此,从成本
从这个角度来看,我们在日志流服务中引入了过滤器来过滤有价值的日志数据,从而降低日志服务使用的资源成本。
我们使用 Kafka Streams 作为 ETL 流处理。通过接口配置实现动态过滤和清理规则。
大致规则如下:
(7)可视化界面 我们主要使用Grafana,它支持很多数据源,包括Prometheus和Elasticsearch,与Prometheus无缝对接。另一方面,Kibana 主要使用 APM 的可视化分析。
我们的日志可视化如下所示
欢迎来到我的知识星球,讨论架构和交换源代码。要加入,请长按下面的二维码:
知识星球上的源代码已经更新,分析如下:
最近更新的“Taro SpringBoot 2.X Primer”系列,已经有20多篇文章,涵盖MyBatis,Redis,MongoDB,ES,分片和分表,读写分离,SpringMVC,Webflux,权限,WebSockets,Dubbo,RabbitMQ,RocketMQ,Kafka,性能测试等等。
提供一个收录近 3W 行代码的 SpringBoot 示例,以及一个收录超过 4W 行代码的电子商务微服务项目。

