汇总:据采集的三种方式-如何获取数据
优采云 发布时间: 2022-11-18 08:16汇总:据采集的三种方式-如何获取数据
随着社会的不断发展。人们越来越离不开互联网。今天小编就给大家盘点一下免费采集数据的三种方式。无论是导出到excel还是自动发布到网站,您只需点击几下鼠标就可以轻松获取数据。详见图1、2、3、4!
业务人员
通过抓取动态网页数据分析客户行为拓展新业务,同时利用数据更好地了解竞争对手,采集数据分析竞争对手并超越竞争对手。
网站人
实现自动采集、定期发布、自动SEO优化,让您的网站瞬间拥有强大的内容支撑,快速提升流量和知名度。
个人的
代替手动复制和粘贴,提高效率并节省更多时间。解决学术研究或生活、工作等数据信息需求,彻底解决没有素材的问题,也告别了手动复制粘贴的痛苦。
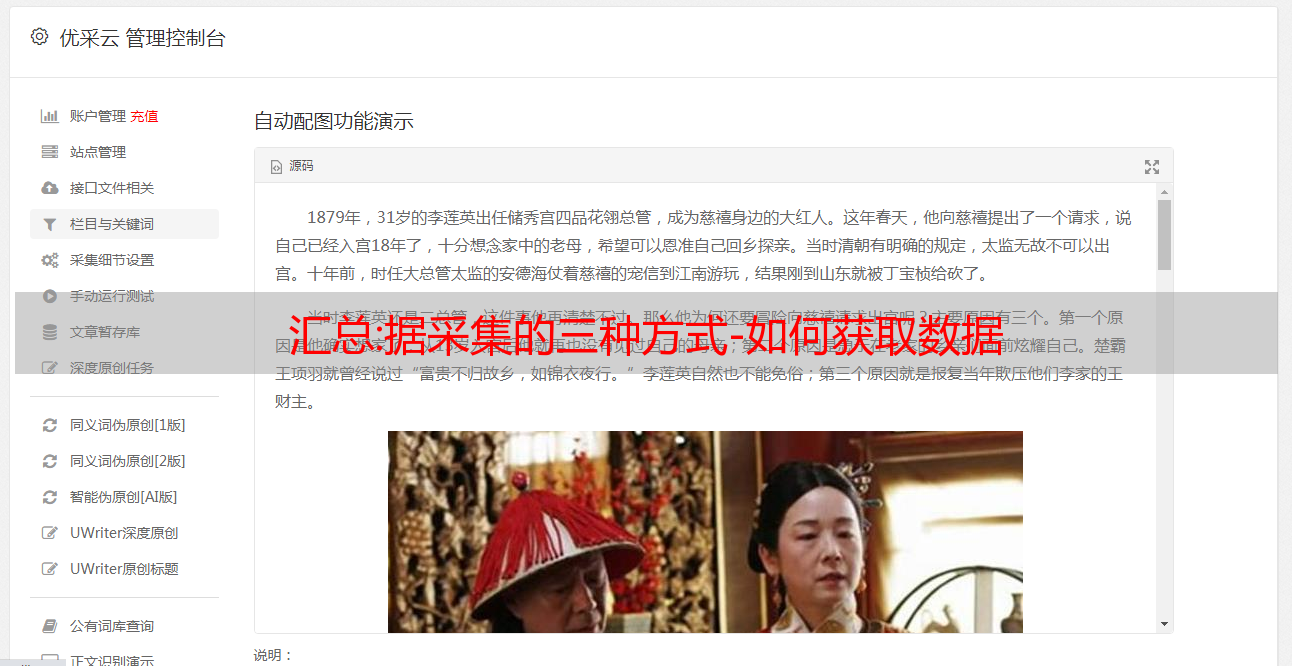
什么是搜索引擎
一种在线搜索工具,旨在根据用户的搜索查询在网络上采集合适的 网站 到自己的数据库中,然后使用独特的算法对它们进行排序。当用户在搜索框中输入关键词时,搜索引擎会向用户显示相应的内容。我们可以举个例子:
当我们想知道秋季有哪些景点值得一游时,可以在搜索框中输入“十月去哪儿”,不到一秒,谷歌或百度等搜索引擎就会在庞大的数据库中进行搜索。中进行内容匹配,然后SERP页面就会显示我们想要的结果。
搜索引擎如何工作
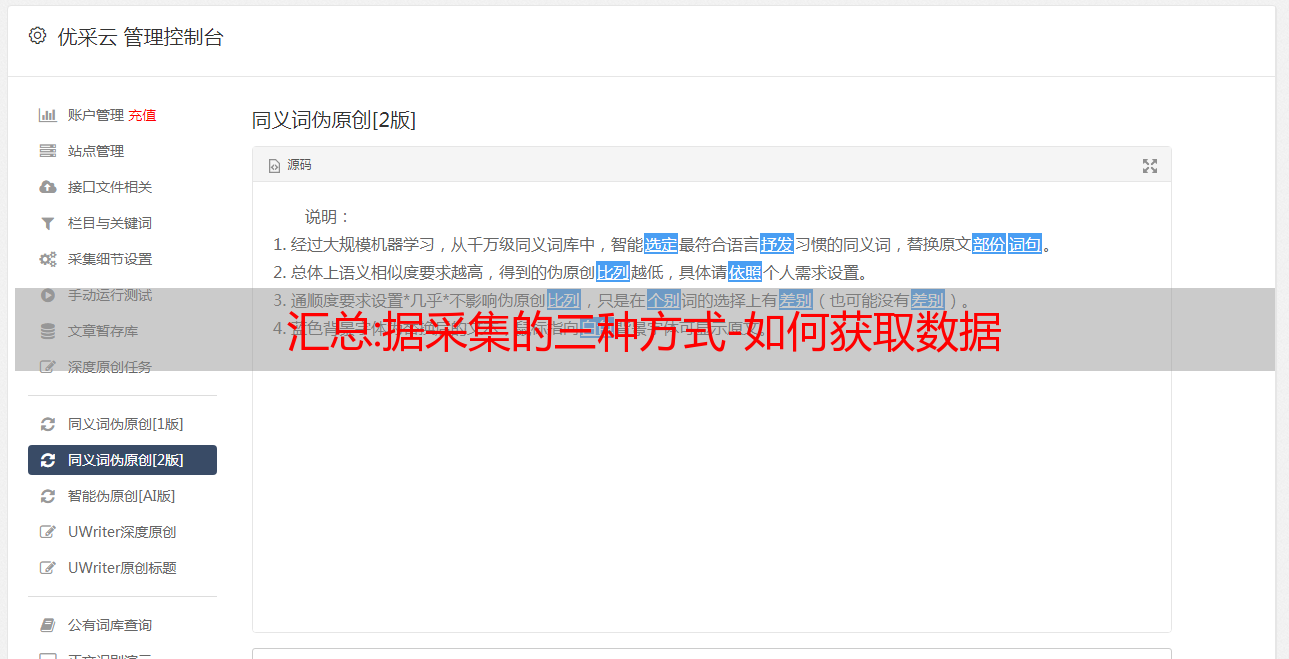
用几句话总结一下:
抓取:搜索引擎首先在互联网上采集信息(这个过程会一直持续),主要方法是跟踪已知网页的链接并建立数据库。
索引:然后分析网页主题以创建此信息的索引。
排名:当用户输入查询词时,谷歌会使用预先组织的索引找到匹配的页面,按排名因素对它们进行排序,然后在SERP页面上将内容显示给用户。
爬行
搜索引擎如何采集数据
搜索引擎发出一个程序来抓取文件以发现新的网页,通常称为蜘蛛或爬虫。当蜘蛛访问一个页面时,它会发出一个访问请求,然后服务器会返回HTML代码并将接收到的代码存储在数据库中。
常见的蜘蛛包括Google Spider、Baidu Spider、Bing Spider、Yahoo! 蜘蛛等。
新页面将如何 收录
爬虫发现新页面的主要跟踪方法是已知网页中的链接。从A页面的超链接中,可以找到B页面、C页面等,搜索引擎蜘蛛会将这些页面存储起来,作为下次访问。基于此,我们要避免一个网页成为“孤岛页”,即没有任何链接指向它。
为什么索引
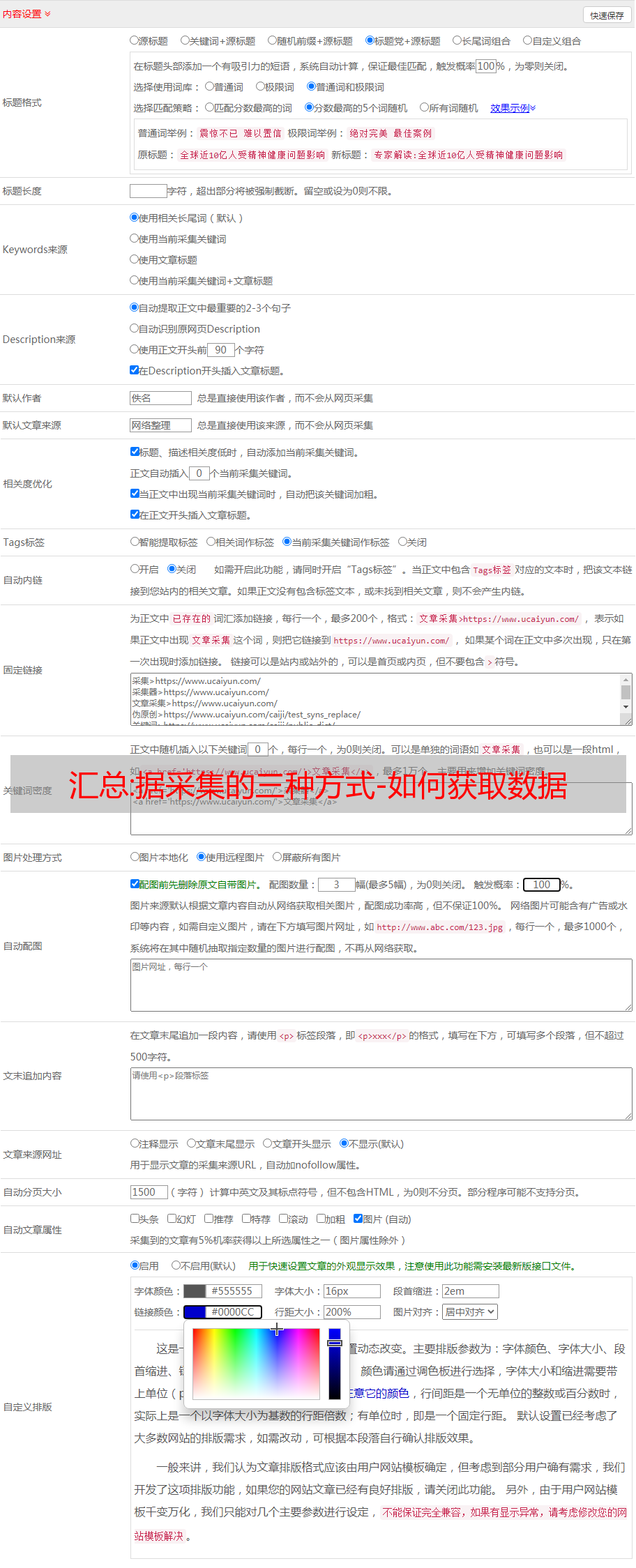
索引的主要目的是帮助程序执行快速查找。我们可以想象一个场景,如果我们让自己在杂货店里寻找某种商品,是不是很难快速找到我们想要的东西?但是,如果杂货摊变成百货公司的安排怎么办?根据我们头顶的标志,我们是否可以立即知道我们想要的产品在哪个部分?然后到相应的货架上找到你想要的物品。索引的作用类似,主要方法有正向索引和倒排索引。
汇总:渗透测试之信息收集
口岸信息采集
端口作为服务器和客户端之间的接口起着非常重要的作用。
一些常用端口标识服务器启用了什么样的功能,常见的有135、137、138、139、445,这些端口往往存在漏洞。以下是一些服务端口漏洞。
可以使用Nmap和masscan对端口进行扫描检测,尽可能多地采集开放的端口和对应的服务版本,得到准确的服务版本后,可以搜索对应版本的漏洞。
nmap扫描的精度更高,但扫描速度较慢。
Masscan 扫描速度更快,但准确性较低。
Nmap -O 192.168.1.1
()
边站C段查询
侧站信息:侧站是与目标网站在同一服务器上的另一个网站。到真正目标的站点目录。
C段:C段是与目标机器ip在同一个C段的其他机器;
想办法通过目标所在的C段中的任何其他机器,穿越到我们的目标机器。对于红蓝对抗和网络保护,C段扫描更有意义。
但是对于网站单独的渗透测试来说,C段扫描意义不大。
每个IP有四个段ABCD,比如192.168.0.1,A段是192,B段是168,C段是0,D段是1,嗅探C段就是拿来和同一个C段的一台服务器,也就是D段1-255的一台服务器,然后用工具嗅探下这台服务器。
目录扫描
由于网站发布时服务器配置问题,目录浏览器可能被打开,造成信息泄露,存在安全隐患。
在信息采集过程中,需要采集的敏感目录/文件包括:
说到网站敏感目录,一定要注意robots.txt文件。
robots.txt 文件是专门为搜索引擎机器人编写的纯文本文件。我们可以在 网站 中指定我们不想被此文件中的机器人访问的目录。
这样,我们的部分或全部网站内容可以从搜索引擎收录中排除,或者搜索引擎只能收录指定内容。
因此,我们可以使用robots.txt来阻止Google机器人访问我们网站上的重要文件,Google Hack的威胁将不复存在。
假设robots.txt文件内容如下:
···
用户代理: *
不允许:/数据/
不允许:/db/
不允许:/admin/
不允许:/经理/
···
“Disallow”参数后面是禁止robot收录部分的路径,
比如我们想让机器人禁止收录网站目录下的“data”文件夹,
只需在 Disallow 参数后添加 /data/ 即可。
如果要添加其他目录,继续按此格式添加即可。
完成编写后将文件上传到 网站 的根目录,这样您就可以使 网站 远离 Google Hack。
虽然robots文件的目的是防止搜索蜘蛛抓取他们想要保护的页面,
但是如果我们知道robots文件的内容,我们就可以知道目标网站的文件夹是不允许访问的。从侧面看,这些文件夹非常重要。
探测目标 网站 后端目录的工具:
网站指纹识别
在渗透测试中,对目标服务器进行指纹识别是非常必要的,因为只有识别出对应的web容器或cms,才能发现相关的漏洞,进而进行相应的渗透操作。
cms也称为整站系统。
常见的cms有:WordPress、Dedecms、Discuz、PhpWeb、PhpWind、Dvbbs、Phpcms、ECShop、SiteWeaver、Aspcms、Empire、Z-Blog等。
在线指纹识别网站:
内容敏感信息泄露
使用谷歌语法查找敏感信息
搜索文件
寻找参数传递参数
找到登录点:
查找目录:
寻找重要的东西:
Github信息公开
Github不仅可以托管代码,还可以搜索代码。当代码上传并公开时,一不小心就会将一些敏感的配置信息文件暴露给公众。
Github主要采集:
网站架构
但是要判断目标网站服务器的具体版本,可以使用nmap扫描,-O和-A参数都可以扫描。
1、Access的全称是Microsoft Office Access,是微软公司发布的关系型数据库管理系统。
对于小型数据库,当数据库达到100M左右时性能会下降。数据库后缀名:.mdb一般是ASP网页文件的access数据库
2、SQL Server是微软开发和推广的关系数据库管理系统(DBMS),是一个比较大的数据库。端口号为1433 数据库后缀名.mdf
3.MySQL是关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle旗下产品。
MySQL 是最流行的关系数据库管理系统。就WEB应用而言,MySQL是最好的应用软件之一。大多数 MySQL 数据库都是 php 页面。默认端口为 3306
4.Oracle又称Oracle RDBMS,简称甲骨文。
它是由甲骨文公司开发的关系数据库管理系统。通常用于较大的 网站。默认端口为 1521
首先在成本上有差距,访问是免费的,mysql也是开源的,sql server收费几千,oracle收费几万。
其次是处理能力,access支持千次以内访问,sql server支持几千到几万次访问,Oracle支持海量访问。
再次,从数据库的规模来看,access是小型数据库,mysql是中小型数据库,sql server是中型数据库,oracle是大型数据库。
了解这些信息后,我们需要知道 网站 使用的是什么类型的 Web 服务器:Apache、Nginx、Tomcat 还是 IIS。
知道了web服务器的类型之后,我们还需要检测web服务器的具体版本。
比如Ngnix版本
1.可以根据网站 URL判断
2. 站点:xxx 文件类型:php
3、可以根据火狐浏览器的插件判断
具体工具教学子域名爆破工具subDomainsBrutesubDomainsBrute功能特点subDomainsBrute安装
1、首先你的电脑需要有python环境。如果你没有,你可以根据下面的链接下载。这里推荐使用python2.7.10
python2.7.10下载地址
或者下载之家也可以下载python2.7.10,按照上面的提示步骤依次安装。
安装后,添加环境变量。
2、下载subDomainsBrute到python根目录,下载地址如下:
subDomainsBrute下载地址:
3.查看python27文件夹下是否有Script文件夹
里面有一些easy_install相关的内容,直接安装setuptools可以自动生成Script文件夹。
下载 ez_setup.py 并在 cmd 中运行它。
进入命令行,然后将目录切换到python安装目录下的Script文件夹下,运行python ez_setup.py生成scripts文件夹。
4.在脚本文件所在路径下输入cmd,在调用的命令行中安装需要的库,直接用pip安装即可。命令是pip install dnspython gevent
Brutez 使用的子域
Usage: subDomainsBrute.py [options] target.com<br />Options:<br /> --version show program's version number and exit<br /> -h, --help show this help message and exit<br /> -f FILE File contains new line delimited subs, default is<br /> subnames.txt.<br /> --full Full scan, NAMES FILE subnames_full.txt will be used<br /> to brute<br /> -i, --ignore-intranet<br /> Ignore domains pointed to private IPs<br /> -t THREADS, --threads=THREADS<br /> Num of scan threads, 200 by default<br /> -p PROCESS, --process=PROCESS<br /> Num of scan Process, 6 by default<br /> -o OUTPUT, --output=OUTPUT<br /> Output file name. default is {target}.txt
层子域挖掘器
Layer子域名挖掘器是一款域名查询工具,可以提供网站子域名查询服务;
界面简洁,操作方式简单,支持服务接口、暴力搜索、同机挖矿三种模式,支持开通网站、复制域名、复制IP、复制CDN、导出域名、导出IP,导出域名+IP,导出域名+IP+WEB服务器,导出生存网站!
使用说明
列出百度下的子域
网站使用后台扫描工具御见
御鉴是一款简单易用的网站后台扫描工具,图形化界面,简单易用。
我们使用御鉴扫描器,主要扫描网站敏感目录,包括网站后台等。
扫描原理也是爆破,即通过敏感目录的字典进行匹配。
御见后台扫描前,爬虫会访问robots txt文件。
工具介绍
御剑安装使用
1、下载解压后双击打开软件。
2、打开后,在域名输入框中输入要扫描的后台地址。
3. 在以下选项中,您可以选择扫描线程、扫描超时和文件类型。
4.全部选好后,点击开始扫描。
5. 扫描完成后,下方会出现扫描结果。
御鉴使用非常简单,简单配置即可进行扫描,但缺点是御鉴无法导出扫描报告。
当然御剑也有很多版本,功能也略有不同,比如指纹识别、后台扫描、真实IP获取、注入检测等。
使用 dirbuster
工具介绍
dirbuster的安装和使用
1. 下载最新版本的 DirBuster。解压后,在Windows中双击DirBuster-0.12.jar,或者直接在Kali中打开内置的DirBuster(命令:root@kali:~#dirbuster)。
2、启动DirBuser后,主界面如下:
注意:如果您的扫描目标是,
然后在URL中填写“/admin/{dir}”进行fuzz,
意思是你可以在“{dir}”前后拼接你想要的目录或后缀,
例如输入“:/admin/{dir}.php”扫描admin目录下的所有php文件。
回顾过去的内容
扫码获取卖淫视频+工具+进群+靶场等信息
扫码免费!
还有免费配套的靶场和交流群!

