推荐文章:自动秒收录外链的网站
优采云 发布时间: 2022-11-17 14:50推荐文章:自动秒收录外链的网站
网站网址:
更新时间: 2022-11-15
网站关键词(28 个字符):
自动秒收录,
第二收录,收录网络,网站快速审核,站长工具,网站推广,
网站描述符(81 个字符):达
达网站导航()提供免费网站目录分类搜索,采集正式中文网站,用户独立网站提交,采集各行业分类目录,努力打造互动新颖的网站收录平台。
关于描述:网
友自愿提交整理收录,本站仅提供基本信息并免费向公众展示,是IP地址:110.40.169.149 地址:上海腾讯云数据中心,百度权重为n,百度手机权重为-文章,百度手机重量为-文章,收录360收录为-文章,搜狗收录为文章, 谷歌收录是——文章,百度访客流量是关于——,百度手机访客流量大约在-之间,记录号是闽ICP备11014391号-223,备案人叫厦门凡库网络科技*敏*感*词*,由百度关键词 收录——和手机关键词——,创建至今11月4日至今。下载
地址:txt下载,docx下载,pdf下载,RAR下载,zip下载
干货教程:小课堂:如何用Excel抓取网页数据
今天的目标:
学习用Excel爬取网页数据
昨天,一位女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2- 感觉Python是大势所趋,不学就会落后
3- 想学习 Python,我从哪里开始?
很明显,朋友圈里python的广告看多了。
想学数据爬取,为什么要用python?只需使用 Excel。
2016年以来的Excel内置了强大的数据处理神器Power Query,可以直接在Excel中实现数据爬取。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?太好了,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用了table标签,那么可以直接导入到网页中。
比如我们经常在豆瓣上看即将上映的电影榜单。这是一个带有表格标签的网页。
网页地址为:
使用Excel抓取数据的步骤如下。
操作步骤1-Excel导入网页数据
在数据选项卡上,单击来自 网站 的其他来源。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击确定
3-加载表数据
这时,你会看到的是Power Query界面。
在窗口左侧的列表中,选择table0,右侧可以看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表中。
使用Power Query的好处是,如果网页中的数据有更新,可以在导入的结果上右击“刷新”来同步数据。
注意
这里说的是网页中收录table标签的数据。
这意味着什么?就是网页里面的数据,本来就是一个表结构。这个方法和直接复制网页数据粘贴到表格中一样。
对于那些不是表格标签的网页数据,这种方法效果不佳。
如何识别网页是否是表格标签?很简单,选择任意数据,然后在网页上右击,选择“Inspect”。
然后你会看到网页的源代码。你不需要理解它。只要在当前高亮代码中看到以下任何一个标签,就说明该网页使用了表格标签。你可以使用这个方法。
<br /><br />
如果没有,则继续方法 2。
方法二
使用表格标签保存数据已经是很古老的网络技术了。目前的网页大多使用div、span等格式更丰富、更灵活的标签来呈现数据。
这种网页不容易直接导入。
例如,我经常阅读的“知乎”,在他们的网页上没有一个单独的表格。
使用方法 1 将其导入 Power 查询。如果左边没有表格数据,就很难抓取。
那我们该怎么办呢?
这时候就需要直接抓包了。
本质上,网页中的数据会被打包成一个数据包,发送网页后,网页会读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只要抓取JSON数据包也可以抓取网页数据。
不管他,都结束了。
“下方高能预警”,不懂的可以跳过看方法三。
脚步
让我们以 知乎 搜索 Excel 问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后右边会出现一个网页调试窗口,然后点击“网络”和“xhr”,在这里可以看到所有的数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后在这个数据包上右击,选择“复制链接地址”,复制这个数据包的链接。
3-导入json数据
接下来进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
点击确定后,将进入Power Query界面。
数据包的结构就像我们的“文件夹”,数据按照类别存放在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深化”。
在数据上依次点击“深化”,可以找到我们的数据。
4-批量读取数据
最后写几个简单的函数,批量读取“子文件”数据。
在“首页”选项卡中,点击“高级编辑器”,打开函数编辑窗口。
写几个简单的函数,我们就完成了数据的抓取。
最终抓取的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面添加参数,可以根据表格中的“search term”实时搜索知乎文章,以及一键刷新统计结果。
方法三
专业的东西交给专业的工具。
Power Query是专业的数据整理插件,不是数据爬取软件,所以方法2你看起来可能有点吃力。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需单击几下按钮即可轻松完成数据抓取。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索网址,如:
然后点击“智能采集”,优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始抓取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
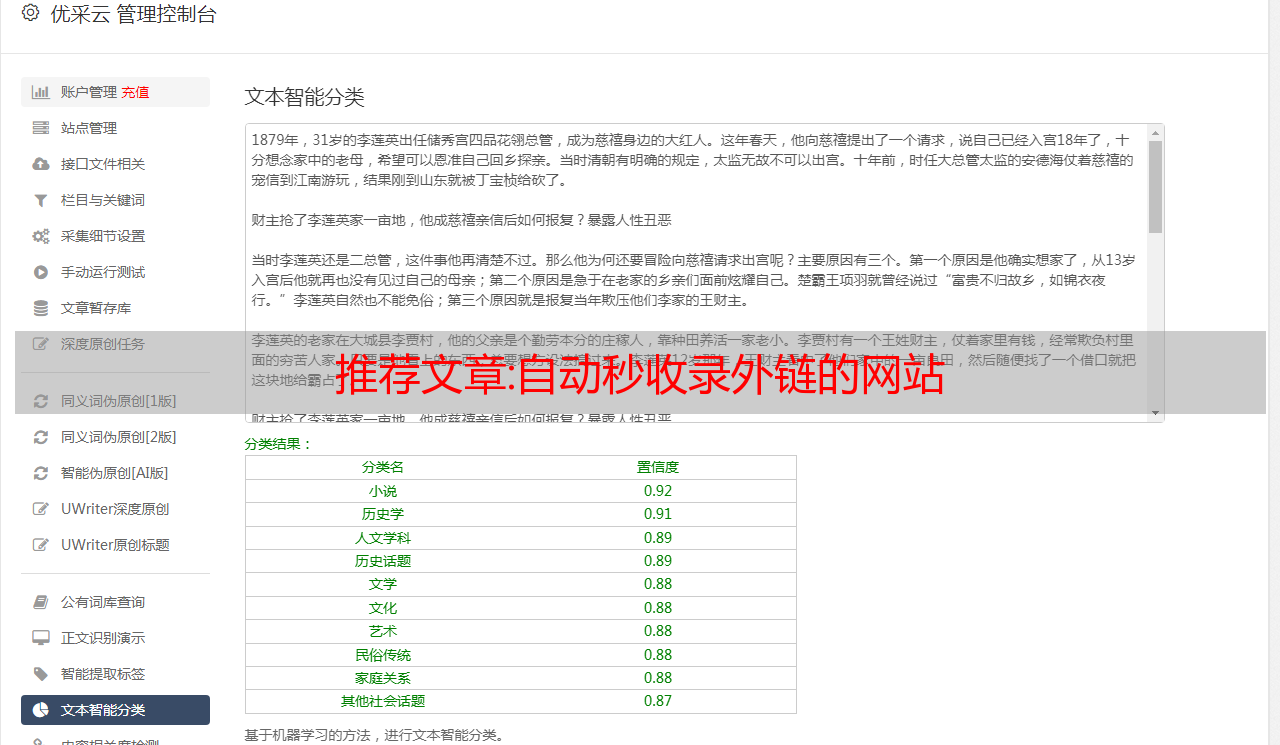
总结
专业的事要用专业的工具来做。
1- 简单的表格网页,使用 Power Query 轻松抓取。
2- 对于复杂的网页,使用爬虫软件也是点击按钮的事情。

