解决方案:为什么新建网站需要做网站优化
优采云 发布时间: 2022-11-17 14:40解决方案:为什么新建网站需要做网站优化
网站优化分为两部分,一是网站结构的优化,二是页面关键词的优化。网站主页的布局在网站优化中起着至关重要的作用。只有好的网站结构才能吸引蜘蛛更好地抓取,从而促进网站的发展。今天木路seo就为大家解析:网站结构的SEO优化有哪些好处?
1. 提升用户体验
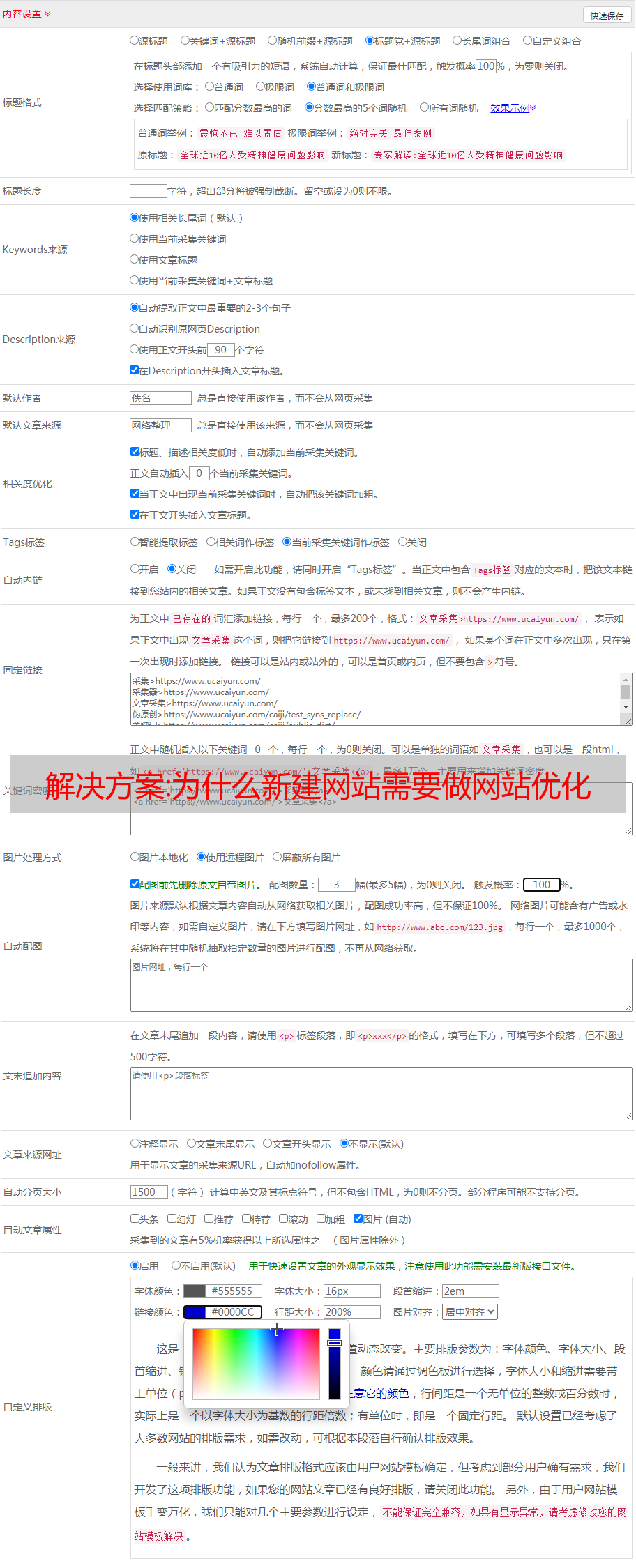
网站结构优化用户体验,多维度考虑用户需求,提升多品类用户体验,使搜索引擎更好地收录网站,从而提升网站排名。
2.提高回收率
优化 网站 结构。建议形成树状结构,保证每个页面至少可以通过一个文本链接访问,这样爬虫才能顺利爬取。高质量的 网站 结构可以显着提高 收录 率,同时保持内容 原创 和更新频率。
3、合理的重量分配
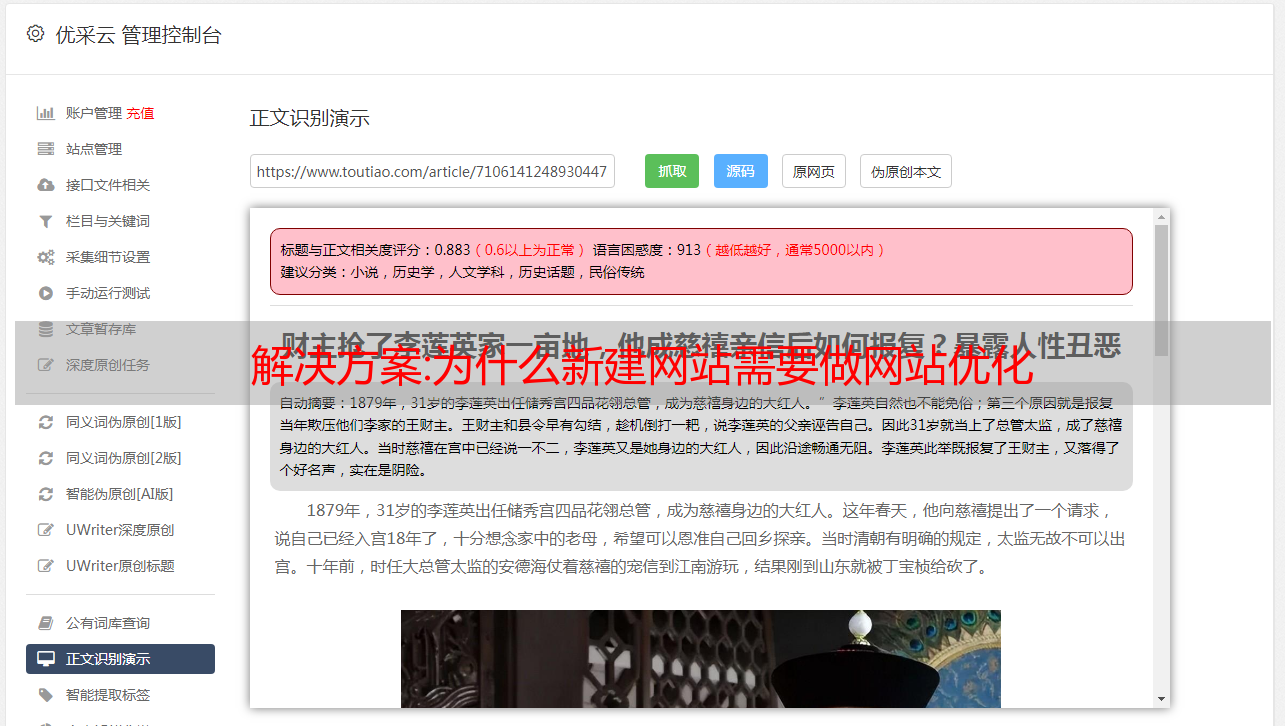
积极开展外链建设。外部链接的质量高于外部链接的数量。找一个高权重的平台,拿到外链,增加整个站点的权重。与高权重网站内页交换友情链接,交换后随时查看友情链接,有问题的友情链接直接删除。这个网站的其他搜索值并不重要。不重要页面的 URL 将被 nofollow 以避免浪费 网站 权限。高质量的 网站 结构可以让 网站 的整体权重适当地分布在每个内部页面上。
4.促进收录未收录的页面
锚文本用于内部链接。关键字出现在锚文本中,有助于提高关键字排名。网站首页权重占比最高。通过文章页面,引导爬虫爬取其他页面,完善其他未收录的页面。
为了更好的排名和流量,网站需要增加外链。为了提高质量,我们需要建立一个高质量的网站结构。从用户的角度来看,用户在浏览网站时很容易获取信息,这不仅让用户对网站产生了兴趣,也更容易被搜索引擎蜘蛛抓取。
解决方案:基于文本模型的通用Web信息采集系统设计与实现
第24届全国计算机信息管理学术研讨会论文集 250 基于文本模型的通用Web信息采集系统设计与实现6) lijiang200@1 摘要 随着Web信息的爆炸式增长,各种基于Web的服务也应运而生。逐渐繁荣。Web信息采集作为这些信息服务的基础和重要组成部分,正被应用到各种应用和研究中。本文主要通过建立网页资源库,结合Spider技术和内容分析技术,引入用户数据项,更换抽取指令编辑器等,分析介绍一种提供和定制可视化和通用性的Web信息采集 . 系统的设计与实现思路,系统可以自动跟踪相关的网站或网页,对其文本模型信息进行比对分析,定期提取和存储。关键词 Web Information Text Model Information 采集 1 引言 随着计算机网络的飞速发展和对信息化要求的不断提高,很多单位都有自己的网站。通常在网站上都会发布一些信息,而这些信息的来源不外乎两种,一种是原创,一种是“带来”。1 引言 随着计算机网络的飞速发展和信息化要求的不断提高,许多单位都有自己的网站。通常在网站上都会发布一些信息,而这些信息的来源不外乎两种,一种是原创,一种是“带来”。1 引言 随着计算机网络的飞速发展和信息化要求的不断提高,许多单位都有自己的网站。通常在网站上都会发布一些信息,而这些信息的来源不外乎两种,一种是原创,一种是“带来”。
原创信息基本是本单位的工作动态和公告等,一般多用户多点更新,即各级负责发布信息的人员在一个表中输入要发布的信息具体WEB页面进入窗口,然后在网站上提交到数据库等待审核发布,信息一一添加。“带”信息是指为满足本单位用户不同的学习、生活需求,从其他网站采集的信息。这些的种类很多,有文字的,有图片的,有音频的,图片的等等,如果这样的信息还是一一添加的话,就会出现很多问题。不仅手动复制粘贴文本到WEB页面的输入窗口容易出错,而且如果遇到有图表的信息,需要单独处理图片中的信息。效率低下、实时性差等问题无法避免。针对互联网上散布的杂乱无章、种类繁多、瞬息万变的信息“取”用的诸多问题,基于Web的信息采集技术应运而生。互联网信息采集系统对互联网上某类或某类站点的内容进行分析整理,从网页中提取有效数据,处理该领域所需的大部分信息,是新一代的网络应用不同于搜索引擎,单纯的智能技术无法满足需求,不同于基于代理互联网信息采集的WebClone系统和各种离线浏览器,它们下载的是页面,用户无法直接提取需要的数据项。不方便实时自动监控源网站的更新信息等。
目前,Web信息大致可以分为四种类型,或者说Web信息基于以下四种模型: (1)文本模型。主要存在单元是“文章”,比如一条新闻,信息属性可以简单分为标题和内容。(2) 图片模型。存在的主要单位是“集合”,比如图集,信息属性包括图集的标题和所属图片的标题和地址。(3)声音模型。主要存在单元为“专辑”,如某张音乐专辑,信息属性包括专辑名称及其所属音乐的名称和歌词。第24届全国计算机信息管理学术研讨会论文集251(4)图像模型.主要存在单元是“ 例如某部连续剧,信息属性包括剧名和分类地址。不同信息模型的具体采集方法不同。本文主要讨论基于文本模型的小型通用Web信息采集系统的设计与实现。2 实现原理 网页信息采集(Web Crawling)主要是指通过网页之间的链接关系,自动从Web上获取页面信息,并随着链接不断扩展到需要的网页的过程。这主要由 Web Information 采集器(Web Crawler) 完成。根据不同的应用习惯,Web Information采集器也被称为Web Spider、Web Robot、Web Worm。例如某部连续剧,信息属性包括剧名和分类地址。不同信息模型的具体采集方法不同。本文主要讨论基于文本模型的小型通用Web信息采集系统的设计与实现。2 实现原理 网页信息采集(Web Crawling)主要是指通过网页之间的链接关系,自动从Web上获取页面信息,并随着链接不断扩展到需要的网页的过程。这主要由 Web Information 采集器(Web Crawler) 完成。根据不同的应用习惯,Web Information采集器也被称为Web Spider、Web Robot、Web Worm。信息属性包括剧名和分类地址。不同信息模型的具体采集方法不同。本文主要讨论基于文本模型的小型通用Web信息采集系统的设计与实现。2 实现原理 网页信息采集(Web Crawling)主要是指通过网页之间的链接关系,自动从Web上获取页面信息,并随着链接不断扩展到需要的网页的过程。这主要由 Web Information 采集器(Web Crawler) 完成。根据不同的应用习惯,Web Information采集器也被称为Web Spider、Web Robot、Web Worm。信息属性包括剧名和分类地址。不同信息模型的具体采集方法不同。本文主要讨论基于文本模型的小型通用Web信息采集系统的设计与实现。2 实现原理 网页信息采集(Web Crawling)主要是指通过网页之间的链接关系,自动从Web上获取页面信息,并随着链接不断扩展到需要的网页的过程。这主要由 Web Information 采集器(Web Crawler) 完成。根据不同的应用习惯,Web Information采集器也被称为Web Spider、Web Robot、Web Worm。
粗略地说,主要是指这样一种程序:从一组初始的URL开始,将所有这些URL放入一个有序的采集队列中。而采集器从这个队列中依次取出URL,通过Web上的协议获取URL指向的页面,然后从这些获取到的页面中提取新的URL,放入等待列表采集在队列中,然后根据自己的策略重复上述过程,直到采集器停止采集。在此基础上,本文还探讨了基于采集文本模型对页面数据进行存储和索引,并在此基础上对内容进行语义分析的技术和实现方法。目前互联网上的所有网页都是采用动态发布技术或基于cms 系统。虽然显示的信息很复杂,但是对于特定的网站和网页来说,是有结构和有效的。具体来说,WEB网站通常可以分为首页、频道、栏目和内容。首页是网站的整体展示,频道是栏目的集合,栏目是相同主题的内容的集合,内容页是用来展示一个具体的内容。同一栏目下的内容页面通常是基于特定模板或基于同一后台程序动态生成,最终以基本统一的HTML或XHTML格式显示在用户浏览器上。这些内容页面的HTML源代码在结构上基本相同,例如,
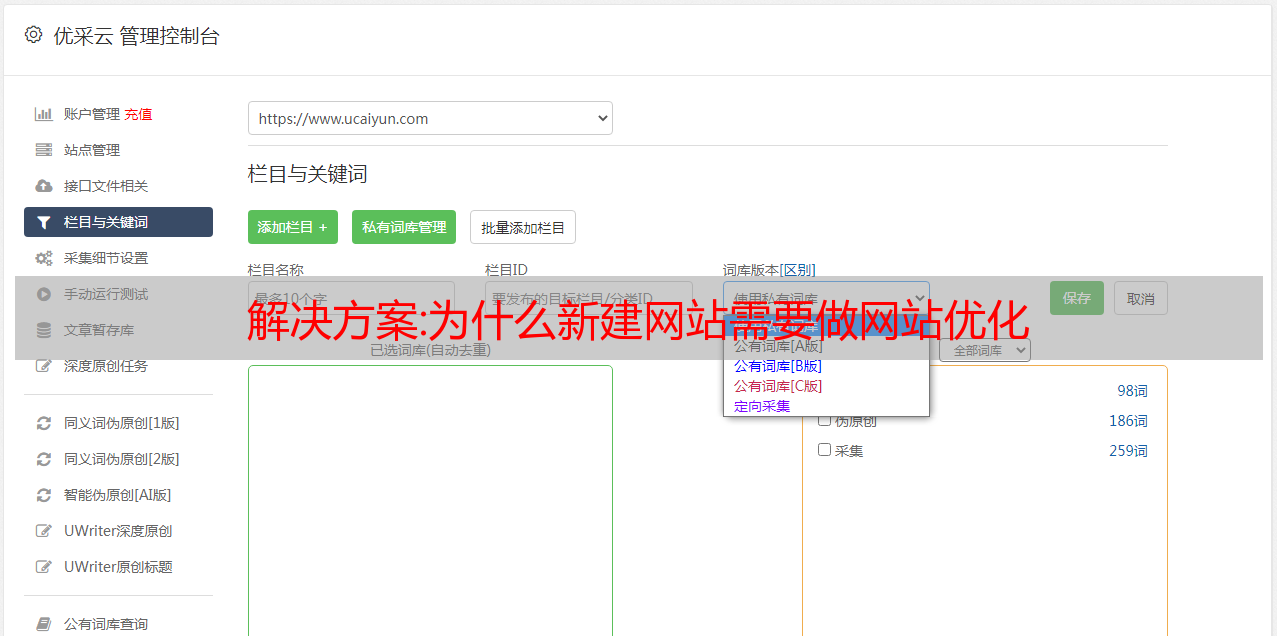
正是因为这些源码有规律可循,页面数据采集才可以方便的自动实现。通过分析指定网站栏目下的栏目页与内容页的链接关系、内容页的源代码以及内容页中的HTML标签,可以找到页面之间的规则和映射关系元素和后台需要的数据项,这些元素可以通过映射关系转化为用户需要的数据。然而,无论采集程序多么聪明,网站页面与后台需要的数据项之间的映射关系是采集系统程序无法自动感知的,所以系统程序的实现方法是 提供一个渠道让用户告诉采集需求的系统程序,以及后台采集设置,告诉采集系统在什么地方选择content 采集哪些元素满足哪些条件,以及将元素放在数据库的哪些部分等等,这样我们就可以结合后台设置和程序代码,设计开发一个通用的互联网信息采集系统从数据挖掘和排序的角度。系统基本*敏*感*词*如图1: 第24届全国计算机信息管理学术研讨会论文集252 3 系统设计系统运行平台采用ASP.NET3.5,数据库采用SQLSERVER 2005,服务器采用IIS , 开发语言采用C#进行编程,开发环境为Visual Studio 2008。3.1 总体设计本系统基于B/S架构实现。服务器端为用户提供数据信息采集定制功能和异步数据传输服务。客户可以使用信息采集定制功能定制自己的关注点。数据和采集任务可以手动或计划启动。自定义功能,自定义自己关心的问题。数据和采集任务可以手动或计划启动。自定义功能,自定义自己关心的问题。数据和采集任务可以手动或计划启动。
3.2 数据库设计通过对系统结构和基于文本模型的Web信息结构的分析,系统需要构建三个基本数据表,(1)列表:用于存放采集数据存储列和采集数据源;(2) 采集规则表:用于存储用户设置的采集规则,以及页面元素与数据项的映射关系;(3)内容表:用于存放文本模型信息的内容。数据表的详细设计结构如下: 表1: 频道(Channels)字段名 字段类型描述 ID int,主键,标识列号 ChannelName nvarchar(20) 列名 SourceURL nvarchar(255) 源地址... www栏目页地址采集设置采集
因此,对应的数据表(TextContent)也应该收录存储上述信息的相应字段,采集规则表(GatherRule)也应该收录这些常用属性字段开始和结束的标识字段,以及其他一些特殊设置(比如是否将内容页中的第一张图片作为标题图片等特殊字段)。然而,我们经常需要在不同的环境和特殊情况下扩展文本模型。穷尽这些模型并列出所有字段显然是不可能的,过多的预置字段往往会造成数据表的较大冗余。遵守数据表设计原则。因此,为了解决上述问题,我们可以在content数据表中预留一个Extend字段,采集 规则数据表。当用户需要扩展文本模型时,可以根据设置将需要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。规则数据表。当用户需要扩展文本模型时,可以根据设置将需要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。规则数据表。当用户需要扩展文本模型时,可以根据设置将需要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。当用户需要扩展文本模型时,可以根据设置将需要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。当用户需要扩展文本模型时,可以根据设置将需要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。他们可以根据设置将要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。他们可以根据设置将要扩展的属性转换为数据表字段。并按以下顺序存储在内容表的Extend字段中[字段名]&[字段类型]&[字段长度]&[是否允许空值]=[字段名1]&[字段类型1]& [Field Length 1] &[是否允许空值1]...并将对应关系以XML格式放入采集规则数据表中的Extend字段,如图2:计算机信息管理论文集 254 图2:采集rule XML格式图 这样既保证了常用属性的检索速度,又解决了文本模型扩展的灵活性,在实际使用中非常有效。
Success){MatchVale = m .Value;}return MatchVale;} 在程序处理过程中,处理内容和摘要等富文本项需要注意其中收录的图像文件和指向其他页面的超链接。图片处理需要通过正则表达式@"
并能适应各种表结构。采集 用于分析和设计的系统。参考文献 [1] 罗傲生.基于ASP实现在线数据自动抓取[J]. 江苏广播电视大学学报, 2004, 6: 60-61. [2] 刘树华,陈国奎.基于PowerBuilder的网页数据抓取[J]. 计算机系统应用, 2009, 2: 171-175. [3] 马志强,赵曦,贾鹏.基于网页的网站信息采集技术研究及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计 系统进行分析和设计。参考文献 [1] 罗傲生.基于ASP实现在线数据自动抓取[J]. 江苏广播电视大学学报, 2004, 6: 60-61. [2] 刘树华,陈国奎.基于PowerBuilder的网页数据抓取[J]. 计算机系统应用, 2009, 2: 171-175. [3] 马志强,赵曦,贾鹏.基于网页的网站信息采集技术研究及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计 系统进行分析和设计。参考文献 [1] 罗傲生.基于ASP实现在线数据自动抓取[J]. 江苏广播电视大学学报, 2004, 6: 60-61. [2] 刘树华,陈国奎.基于PowerBuilder的网页数据抓取[J]. 计算机系统应用, 2009, 2: 171-175. [3] 马志强,赵曦,贾鹏.基于网页的网站信息采集技术研究及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计 江苏广播电视大学学报, 2004, 6: 60-61. [2] 刘树华,陈国奎.基于PowerBuilder的网页数据抓取[J]. 计算机系统应用, 2009, 2: 171-175. [3] 马志强,赵曦,贾鹏.基于网页的网站信息采集技术研究及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计 江苏广播电视大学学报, 2004, 6: 60-61. [2] 刘树华,陈国奎.基于PowerBuilder的网页数据抓取[J]. 计算机系统应用, 2009, 2: 171-175. [3] 马志强,赵曦,贾鹏.基于网页的网站信息采集技术研究及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计 基于网页的技术及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计 基于网页的技术及实现[J]. 内蒙古大学学报(自然科学版), 2009, 3: 203-207. [4] 白占生,许德志,彭家红,陈光义.基于主题本体的信息采集模型研究[J].计算机技术与发展, 2009, 19: 102-105. 图 4:系统界面设计

