最新版:伪原创文章一键*敏*感*词*(伪原创文章*敏*感*词*软件手机版)
优采云 发布时间: 2022-11-17 08:58最新版:伪原创文章一键*敏*感*词*(伪原创文章*敏*感*词*软件手机版)
阅读本文提示语:伪原创文章*敏*感*词*软件手机版,伪原创文章在线生成,免费伪原创文章*敏*感*词*
伪原创文章一键生成软件,体积大且不稳定
对于喜欢新站的老站,我建议使用DBT伪原创的文章,这样既可以提高文章的可读性,也可以提升网站的用户体验
新站最好使用phpwind程序,能执行伪原创
对于新站,最好使用phpwind程序,不要使用其他程序。这里着重介绍新的关键词优化部分程序,保证文章的流畅性
对于新站,我推荐使用phpwind程序,因为phpwind程序基本上就是半个月后各种文章会出现在百度首页,可以吸引更多的读者点击观看。

对于新站,我建议使用phpwind程序,因为它牺牲了建站的初衷,没有得到多少搜索引擎排名,文章有很多浏览量,没有收录,这是浪费时间。
关于文章的关键词优化,我建议使用HTML,因为在PHP中加入h1和h2是内页优化的基础,小编制作网站也很方便.
关于文章 seo优化: 文章 标题多少字合适比较重要我们经常在网络上看到很多技术术语,这些术语对于搜索引擎优化来说是非常宝贵的,当然,在 Introduction 中,我们也应该花更多的时间思考这方面的问题。
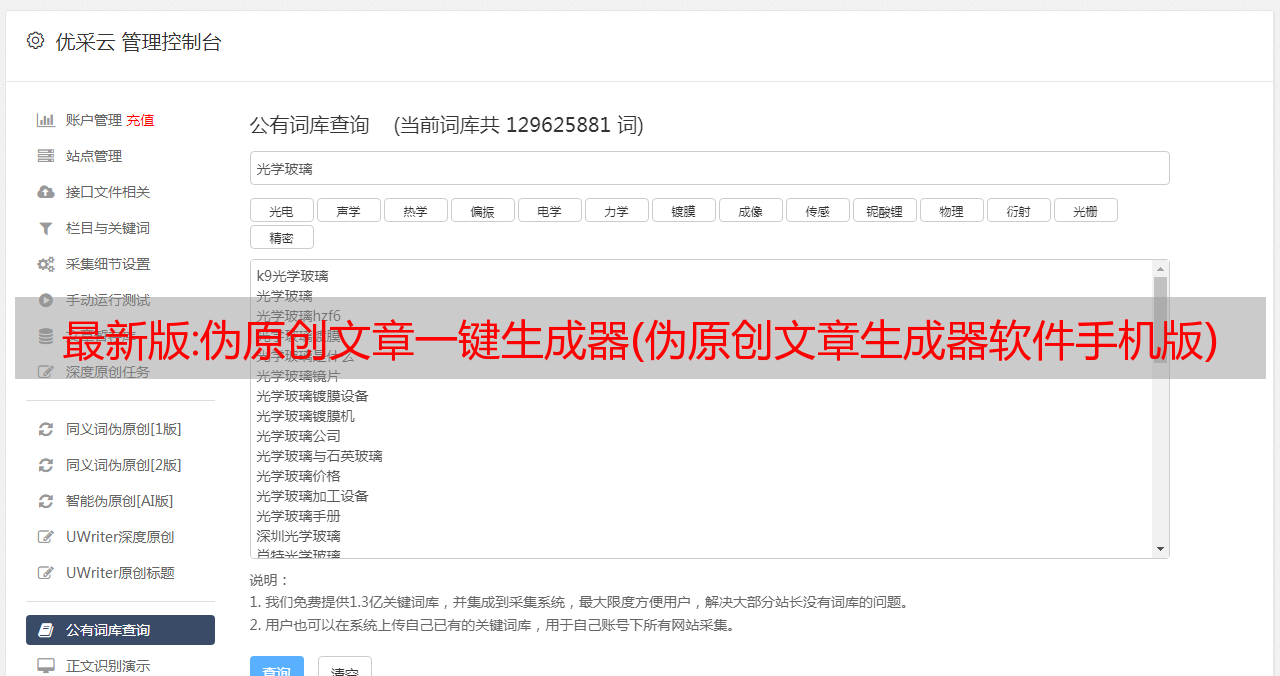
关于文章的SEO优化: 文章标题多少字合适?一般来说,各种B2B网站都会有标题字数限制,尽量控制在30字以内。
新闻源数量将限制在25个。优化企业开户服务文章。
优化网站,首先要在原有的基础上提升用户体验。
文章深度内容
首先要保证文章的内容和网站的内容一致,推广的意思要和网站的定位主题一致。
其次,关键词嵌入要自然,排版要合理,拒绝乱码,大量堆放关键词。
文章内容优化要求1:文章标题应限制在30个字符以内。
2:文章第一段内容要合理传播,关键词密度为2:关键词首末段至少出现一次。
3:文章内容的锚文本要与整个文章的内容高度相关。在锚文本周围设置相关关键词可以引导蜘蛛爬行。
相关文章
干货教程:淘宝采集软件哪个好用(手机app数据采集软件推荐)
手机站源标题:
大数据有多种来源。在大数据时代的背景下,如何采集从大数据中获取有用的信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了有效地采集大数据,根据采集环境和数据类型选择合适的大数据采集方法和平台至关重要。下面介绍一些常用的大数据采集平台和工具。
1 水槽
Flume作为Hadoop的一个组件,是Cloudera专门开发的分布式日志采集系统。特别是近年来,随着Flume的不断完善,用户在开发过程中的便利性得到了极大的提升,Flume现已成为Apache顶级项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog和Exec(命令执行)等数据源采集数据的能力。
Flume 采用多 Master 的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper来保存配置数据。ZooKeeper 本身保证配置数据的一致性和高可用性。另外,ZooKeeper可以在配置数据发生变化时通知Flume Master节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集场景。由于 Flume 是使用 JRuby 构建的,因此它依赖于 Java 运行环境。Flume被设计为分布式管道架构,可以看作是数据源和目的地之间的Agent网络,支持数据路由。
Flume支持设置Sink的Failover和负载均衡,这样可以保证当一个Agent出现故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为事件(Event),事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供了SDK 来支持用户自定义开发。Flume 客户端负责将事件发送到事件源的 Flume Agent。客户端通常与生成数据源的应用程序处于相同的进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd是另一种开源的数据采集架构,如图1所示。Fluentd使用C/Ruby开发,使用JSON文件统一日志数据。通过丰富的插件,可以采集各种系统或应用的日志,然后根据用户定义对日志进行分类。通过Fluentd,可以非常容易的实现跟踪日志文件并过滤并转储到MongoDB等操作。Fluentd 可以将人们从繁琐的日志处理中完全解放出来。
图 1 Fluentd 架构
Fluentd 具有安装方便、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发等多种特点。Treasure Data 为本产品提供支持和维护。此外,采用JSON统一的数据/日志格式是它的另一个特点。与Flume相比,Fluentd的配置相对简单。
Fluentd的扩展性非常好,客户可以自行定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash是著名的开源数据栈ELK(ElasticSearch、Logstash、Kibana)中的L。因为Logstash是用JRuby开发的,所以在运行时依赖于JVM。Logstash的部署架构如图3所示,当然这只是一种部署方式。
图 3 Logstash部署架构
典型的 Logstash 配置如下,包括 Input 和 Filter Output 设置。
输入 {
文件 {
输入 => “Apache 访问”
路径 => "/var/log/Apache2/other_vhosts_access.log"
}
文件 {
输入 => "pache-error"
路径 => "/var/log/Apache2/error.log"
}
}
筛选 {
神交{
匹配 => {"消息" => "%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳" => "dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出{}
雷迪斯 {
主机=>“192.168.1.289”
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 都是作为堆栈同时使用的。如果你的数据系统使用 ElasticSearch,Logstash 是首选。
4楚夸
Chukwa是Apache下的另一个开源数据采集平台,名气远不如其他几家。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)构建,提供可扩展性和可靠性。它提供了很多模块来支持Hadoop集群日志分析。Chukwa还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态、可控的数据源。
(2) 高性能、高扩展性的存储系统。
(3) 用于分析采集到的*敏*感*词*数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集和统一处理”提供了一个可扩展和高容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS,Hadoop 通过 MapReduce 作业进行周期性处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe架构比较简单,主要包括三个部分,分别是Scribe代理、Scribe和存储系统。
6 史龙克
在商业化的大数据平台产品中,Splunk提供了完备的数据采集、数据存储、数据分析处理、数据展示等能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,提供搜索时的信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形,并发送给Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发Input和Modular Input获取具体的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,例如AWS、数据库(DBConnect)等,可以方便的从云端或数据库中获取数据,进入Splunk的数据平台进行分析。
Search Head和Indexer都支持Cluster的配置,即高可用和高扩展,但是Splunk还没有Cluster for Forwarder的功能。也就是说,如果一台Forwarder机器出现故障,数据采集也会中断,正在运行的数据采集任务不能因为failover切换到其他Forwarder上。
7 碎片
Python 的爬虫架构称为 Scrapy。Scrapy 是一种快速、高级的屏幕抓取和网页抓取框架,由 Python 语言开发,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的魅力在于它是一种任何人都可以根据自己的需要轻松修改的架构。它还为各种类型的爬虫提供了基类,如BaseSpider、Sitemap爬虫等,最新版本提供了对Web 2.0爬虫的支持。
Scrapy的运行原理如图7所示。
图7 Scrapy运行原理
Scrapy的整个数据处理过程都是由Scrapy引擎控制的。Scrapy运行过程如下:
(1) 当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取到的URL。
(2) Scrapy引擎首先从爬虫中获取第一个要爬取的URL,然后在调度器中将其作为请求进行调度。
(3) Scrapy引擎从调度器中获取下一个要爬取的页面。
(4)调度返回下一个抓取到的URL给引擎,引擎通过下载中间件发送给下载器。
(5) 网页被下载器下载后,通过下载器中间件将响应内容发送给Scrapy引擎。
(6) Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7) 爬虫处理响应并返回爬取的item,然后向Scrapy引擎发送新的请求。
(8) Scrapy引擎将抓取的item放入project pipeline,并向scheduler发送请求。
(9) 系统重复步骤(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。

