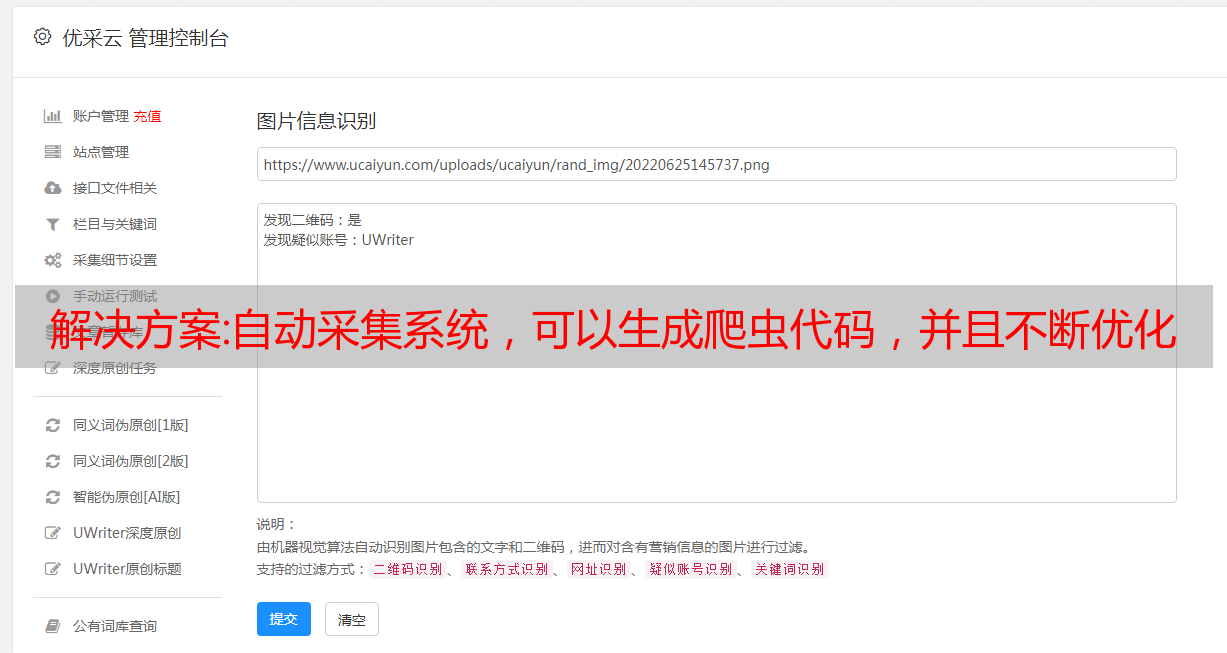
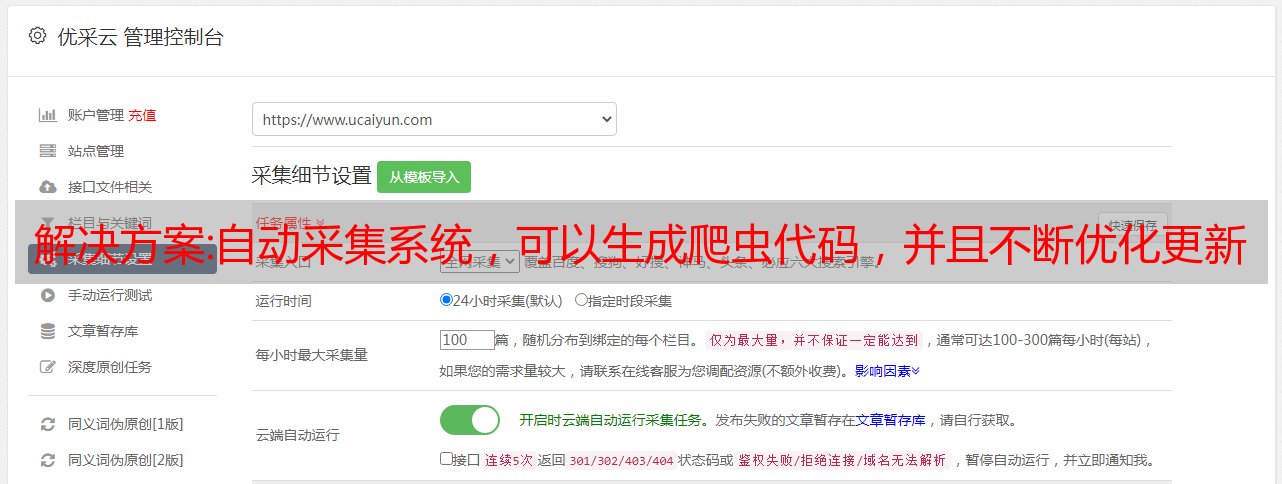
解决方案:自动采集系统,可以生成爬虫代码,并且不断优化更新
优采云 发布时间: 2022-11-17 07:22解决方案:自动采集系统,可以生成爬虫代码,并且不断优化更新
自动采集系统,可以生成爬虫代码,并且不断优化更新。
1、要购买一个mac的操作系统,服务端java是自己的,本质是要编译整个java程序。
2、爬虫一定要有一个快捷键设置方式,这个看你自己对爬虫的个人习惯。
3、爬虫的后台程序要完善,例如要有权限管理,数据备份与恢复功能。
4、要有一个云存储方式存储数据,你的系统和仓库是分离的,要不然生成的程序也许做不到强大。
5、定期对你的程序进行压力测试,保证采集的过程不出差错。推荐用guessio去用。
scrapy+sina+bittiger爬虫套餐,你值得拥有。至于爬虫的优缺点,你可以参考我关于这个问题的回答:如何从400+sina以及其他爬虫中,
自荐一下自己的开源爬虫:selenium有免费版
公众号爬虫,crawl007,提供scrapy框架。
python毕竟好学,新手好上手,自动采集网站不好玩。
multijs-自动采集数据
自动采集网站很简单,开源爬虫也很多,缺点就是前端要设计出一套比较优雅的,但是适合刚刚接触爬虫的同学。另外对象数据库解析。
可以看看我开源的scrapy爬虫
除了http外,还可以用ror。除此之外,采集函数会比scrapy慢,个人觉得应该是scrapy先找数据规律再遍历,有些处理复杂的操作得用linux更快点。

