核心方法:soup关键词文章采集源码:method.py
优采云 发布时间: 2022-11-16 23:19
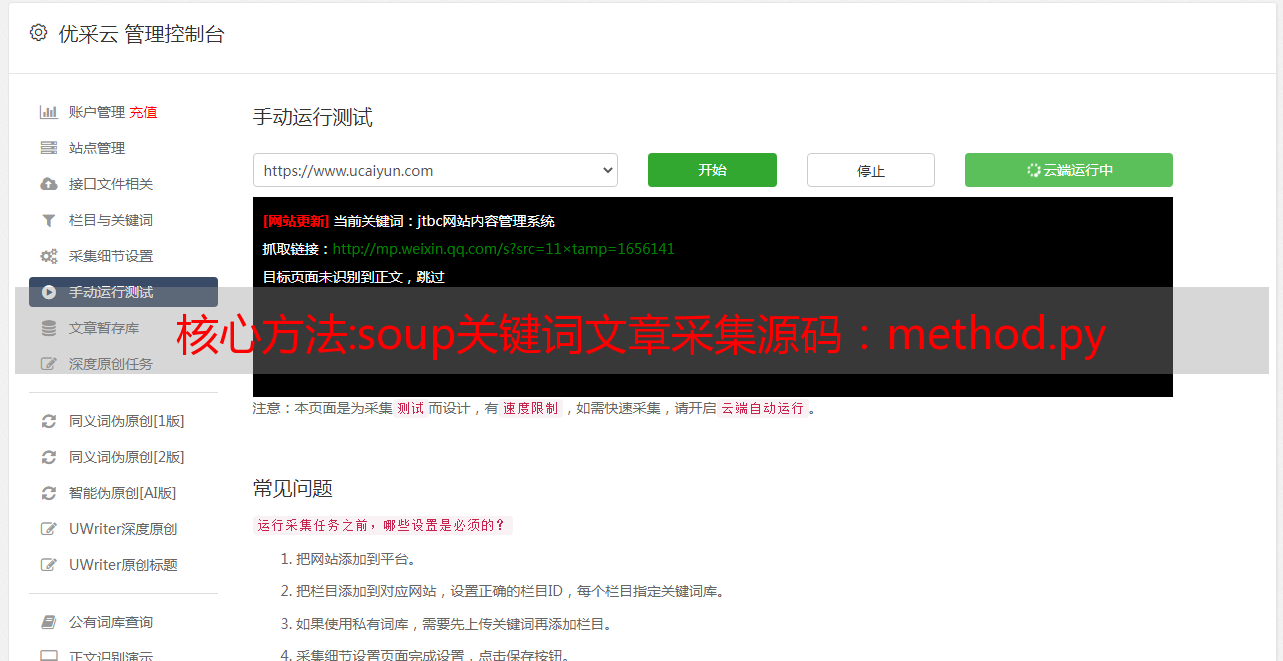
关键词文章采集源码:method.py模块很棒,重写一份可以快速一键生成采集表,接下来我们要做的就是不断训练我们的采集模块至于优化表,我个人推荐是让url增加计数,这样得到的会显得比较乱,后面我要训练这个采集表。我们先用我写的python代码训练一个采集表我们第一步要创建enquerypath变量用来存放我们要爬取的网页的包名,注意变量名和我们之前创建的包名不一样,这个是计数,有利于后面定位我们采集的网站。
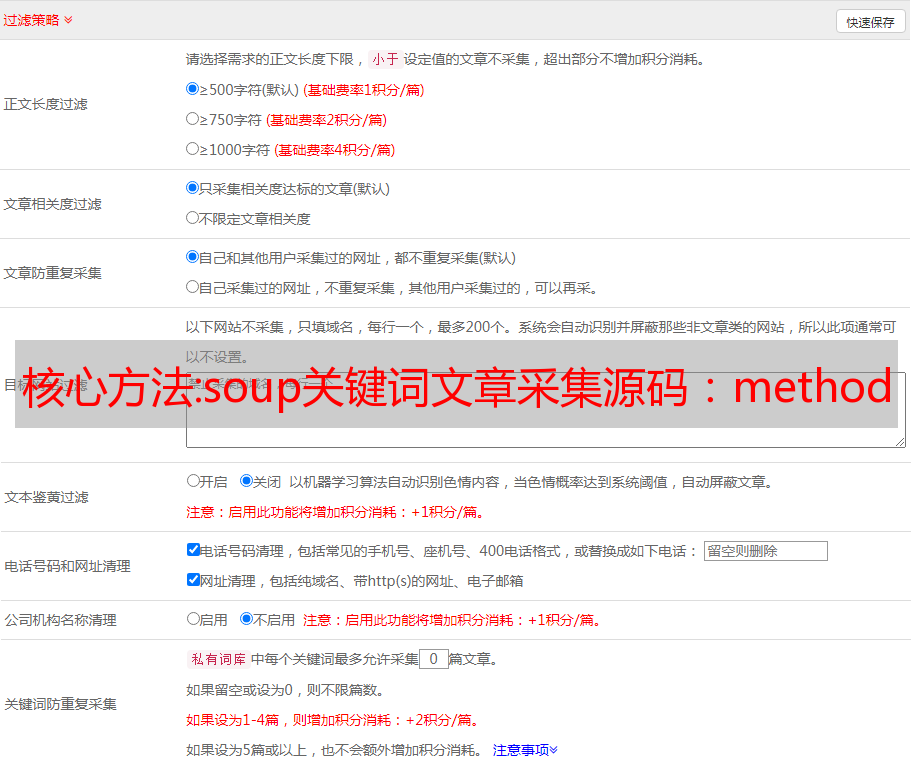
然后我们定义一个request函数用来接收采集表,采集表中的信息,这个函数,我们定义成内部函数,方便后面训练我们训练然后我们先用最简单的实例训练下这个抓取表我们主要有三个步骤,分别对应三个函数分别是:pages,page_encode,url_code(或page_code),我们首先训练pages那我们训练第一个page_encode那就要从网页中的一个body开始,soup中的body对应一个body对应一个表中的一个body,我们可以将表的原有的一些字段,作为匹配,然后传递给body中,然后对应表进行匹配,然后采集。
分别放在page_encode函数中importurllib2fromrequestsimportbuild_encoderequest=build_encode(urllib2.urlopen(''))cookies={'key':'value'}page_encode_all=urllib2.urlopen('')page_encode_all.read()page_encode_bytes=build_encode(urllib2.urlopen(''))page_encode_all.read()最后我们的一个最简单的采集表就完成了,我们再来训练url_code那这个时候一个简单的采集表就可以开始训练,首先是安装urllib2importurllib2fromrequestsimportbuild_encoderequest=build_encode(urllib2.urlopen(''))cookies={'key':'value'}page_encode_all=urllib2.urlopen('')page_encode_all.read()page_encode_all.read()最后我们的一个最简单的采集表就可以开始训练,我们把爬取表的代码定义在这里authors={'username':'_zhangyu0218','password':'_zhangyu0218'}page_encode_all=urllib2.urlopen('')page_encode_all.read()enquery_explain='='+urllib2.urlopen(urllib2.urlopen(''))+'&ctx=submit&submit=true'enquery_explain=urllib2.urlopen(urllib2.urlopen(''))+'&submit=false'#urllib2网络采集库会以post请求方式从服务器拿取u。

