终极:神策杯 2018高校算法大师赛(个人、top2、top6)方案总结
优采云 发布时间: 2022-11-15 16:29终极:神策杯 2018高校算法大师赛(个人、top2、top6)方案总结
神策数据推荐系统是基于神策分析平台的智能推荐系统。根据客户需求和业务特点,基于神策分析采集的用户行为数据,利用机器学习算法对咨询、视频、产品等进行个性化推荐,为客户提供智能化应用不同场景,比如优化产品体验,提升点击率等核心业务指标。
传感器推荐系统是一个完整的学习闭环。采集的基础数据是通过机器学习的算法模型来应用的。实时验证效果,引导数据源的添加,算法优化反馈形成全流程、实时、自动、快速迭代的推荐闭环。
本次比赛模拟业务场景,目的是提取新闻文本的核心词,最终结果达到提升推荐和用户画像的效果。
比赛链接:
Dataset数据地址:
密码:qa2u
02任务
个性化推荐系统是神策智能系统的一个重要方面。准确理解信息的主题是提高推荐系统效果的重要手段。基于真实的商业案例,神策数据提供了数千篇文章 文章 及其 关键词。参赛者需要训练一个“关键词抽取”模型来抽取10万条新闻文章的关键词。
03数据
备注:报名参赛或加入战队后,即可获得数据下载权限。
提供下载的数据集包括两部分:1.all_docs.txt,108295条信息文章数据,数据格式为:ID文章title文章text,以
终极:神策杯 2018高校算法大师赛(个人、top2、top6)方案总结
优采云 发布时间: 2022-11-15 16:29终极:神策杯 2018高校算法大师赛(个人、top2、top6)方案总结
神策数据推荐系统是基于神策分析平台的智能推荐系统。根据客户需求和业务特点,基于神策分析采集的用户行为数据,利用机器学习算法对咨询、视频、产品等进行个性化推荐,为客户提供智能化应用不同场景,比如优化产品体验,提升点击率等核心业务指标。
传感器推荐系统是一个完整的学习闭环。采集的基础数据是通过机器学习的算法模型来应用的。实时验证效果,引导数据源的添加,算法优化反馈形成全流程、实时、自动、快速迭代的推荐闭环。
本次比赛模拟业务场景,目的是提取新闻文本的核心词,最终结果达到提升推荐和用户画像的效果。
比赛链接:
Dataset数据地址:
密码:qa2u
02任务
个性化推荐系统是神策智能系统的一个重要方面。准确理解信息的主题是提高推荐系统效果的重要手段。基于真实的商业案例,神策数据提供了数千篇文章 文章 及其 关键词。参赛者需要训练一个“关键词抽取”模型来抽取10万条新闻文章的关键词。
03数据
备注:报名参赛或加入战队后,即可获得数据下载权限。
提供下载的数据集包括两部分:1.all_docs.txt,108295条信息文章数据,数据格式为:ID文章title文章text,以\001分隔在中间。2. train_docs_keywords.txt,1000篇文章文章的关键词标注结果,数据格式为:ID关键词列表,中间用\t分隔。
注意:标记数据中每个文章的关键词不超过5个。关键词 都出现在 文章 的标题或正文中。需要注意的是“the set of 关键词 of the training set 文章”和“the set of 关键词 of the test set 文章”,这两个集合可能会重叠,但收录与收录之间并不一定存在关系。
04个人预赛第十一名方案
基于NLP中的无监督学习方法提取关键词,这也是我第一次参加比赛。当时刚接触NLP,所以对这次比赛印象很深,在此分享给大家
神策杯“2018年高校算法大师赛B组排名(13/583)
4.1 计分
4.2 数据分析:
4.3 提高技能
词性标注
这就是tf-idf抽取关键词错误较大的原因
4.5 核心代码:
# -*- coding: utf-8 -*-<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># @Author : quincyqiang<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># @File : analysis_for_06.py<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># @Time : 2018/9/5 14:17<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import pickle<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import pandas as pd<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />from tqdm import tqdm<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />from jieba.analyse import extract_tags,textrank # tf-idf<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />from jieba import posseg<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import random<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import jieba<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />jieba.analyse.set_stop_words('data/stop_words.txt') # 去除停用词<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />jieba.load_userdict('data/custom_dict.txt') # 设置词库<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />'''<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> nr 人名 nz 其他专名 ns 地名 nt 机构团体 n 名词 l 习用语 i 成语 a 形容词 <br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> nrt <br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> v 动词 t 时间词<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />'''<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />test_data=pd.read_csv('data/test_docs.csv')<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />train_data=pd.read_csv('data/new_train_docs.csv')<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'n':6,'l':7,'i':8,'a':9,'nrt':10,'v':11,'t':12}<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'nrt':10}<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />tf_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt','v','a']<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />def generate_name(word_tags):<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> name_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt']<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> for word_tag in word_tags:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if word_tag[0] == '·' or word_tag=='!':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> index = word_tags.index(word_tag)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if (index+1) 1]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> title_keywords = sorted(title_keywords, reverse=False, key=lambda x: (allow_pos[x[1]], -len(x[0])))<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if '·' in title :<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if len(title_keywords) >= 2:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_1 = title_keywords[0][0]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_2 = title_keywords[1][0]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> else:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # print(keywords,title,word_tags)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_1 = title_keywords[0][0]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_2 = ''<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_1.append(key_1)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_2.append(key_2)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> else:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # 使用tf-idf<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> use_idf += 1<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # ---------重要文本-----<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words = []<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> for keyword in title_keywords:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if keyword[1] == 'n':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.append(keyword[0])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if keyword[1] in ['nr', 'nz', 'nt', 'ns']:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.extend([keyword[0]] * len(keyword[0]))<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> abstract_text = "".join(doc.split(' ')[:15])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> for word, tag in jieba.posseg.cut(abstract_text):<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if tag == 'n':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.append(word)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if tag in ['nr', 'nz', 'ns']:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.extend([word] * len(word))<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_text = "".join(primary_words)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # 拼接成最后的文本<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> text = primary_text * 2 + title * 6 + " ".join(doc.split(' ')[:15] * 2) + doc<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # ---------重要文本-----<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> temp_keywords = [keyword for keyword in extract_tags(text, topK=2)]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if len(temp_keywords)>=2:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_1.append(temp_keywords[0])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_2.append(temp_keywords[1])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> else:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_1.append(temp_keywords[0])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_2.append(' ')<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> data = {'id': ids,<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> 'label1': labels_1,<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> 'label2': labels_2}<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> df_data = pd.DataFrame(data, columns=['id', 'label1', 'label2'])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> df_data.to_csv('result/06_jieba_ensemble.csv', index=False)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> print("使用tf-idf提取的次数:",use_idf)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />if __name__ == '__main__':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # evaluate()<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> extract_keyword_ensemble(test_data)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />© 2021 GitHub, Inc.<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />
以下是来自国内大佬的无私风向
05 “神策杯”2018年高校算法大师赛第二名代码
代码链接:
文章链接:
团队:SCI毕业
5.1 目录说明
jieba:修改jieba库。
词典:商店解吧词库。PS:词库来自搜狗百度输入法词库,爬虫获得的星词和LSTM命名实体识别结果。
all_docs.txt:训练语料库
train_docs_keywords.txt:我改了一些明显错误的关键词,比如D039180梁静茹->贾静雯,D011909泰荣军->泰荣军等。
classes_doc2vec.npy:默认gensim参数,doc2vec+Kmeans对语料库的聚类结果。
my_idf.txt:计算出的语料的idf文件。
lgb_sub_9524764012949717.npy LGB的某个预测值,用于特征生成
stopword.txt:停用词
Get_Feature.ipynb:特征生成notebook,生成训练集和测试集对应的文件
lgb_predict.py:预测并输出结果的脚本。需要 train_df_v7.csv 和 test_df_v7.csv。
train_df_v7.csv、test_df_v7.csv:Get_Feature.ipynb的结果,notebook有详细的特征描述
Word2vec模型下载地址: 提取码:tw0m。
Doc2vec模型下载地址:链接:提取码:0ciw。
5.2 操作说明
运行 Get_Feature.ipynb 以获取 train_df_v7.csv 和 test_df_v7.csv。
运行 lgb_predict.py 得到结果 sub.csv。
numpy 1.14.0rc1<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />pandas 0.23.0<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />sklearn 0.19.0<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />lightgbm 2.0.5<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />scipy 1.0.0<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />
5.3 解题思路和方案说明
使用jieba的tfidf方法筛选出Top20的候选人关键词
对每个样本的候选关键词提取对应的特征,将关键词提取当做一个普通的二分类问题。特征可以分为两类:
样本文档本身的特征:如文本长度、句子数量、聚类结果等;
候选人关键词自身特点:关键词的长度、逆词频等;
样本文本与候选关键词的交互特征:词频、中心词频、tfidf、主题相似度等;
candidate 关键词之间的特征:主要是关键词之间的相似特征。
候选 关键词 和其他示例文档之间的交互特征:这里有两个非常强大的特征。第一个是候选 关键词 在整个数据集中出现的频率,第二个类似于点击率。计算整个文档中被预测为正样本的概率结果的个数大于0.5(之前提到这个特征的时候,我大概以为会过拟合,但是效果出乎意料的好,所以没有做相应的平滑处理,可能吧因为结果只有Top2的关键词,这里选择0.5的概率会有一定的平滑效果,具体操作参考lgb_predict.py的31-42行)。
使用LightGBM解决上面的二分类问题,然后根据LightGBM的结果选择每个文本预测概率前2的词作为关键词输出。
06 第六名项目排名 6 / 622
代码链接:
07总结
该任务属于短语挖掘或关键词挖掘。在接触NLP的过程中,很多同学都在研究如何从文本中挖掘关键词。NLP技术经过近几年的发展,大致归纳出以下几种方法。在上面分享的三个解决方案中:
基于无监督方法:LDA、TFIDF、TextRank
基于特征工程:基于无监督生成候选词,进而构建特征训练二分类模型
关键词基于深度学习的提取:span、bio、bmes crf序列标注等方法
08 更多信息
谈谈医疗保健领域的Phrase Mining
加微信到交流群:1185918903 注:ChallengeHub01
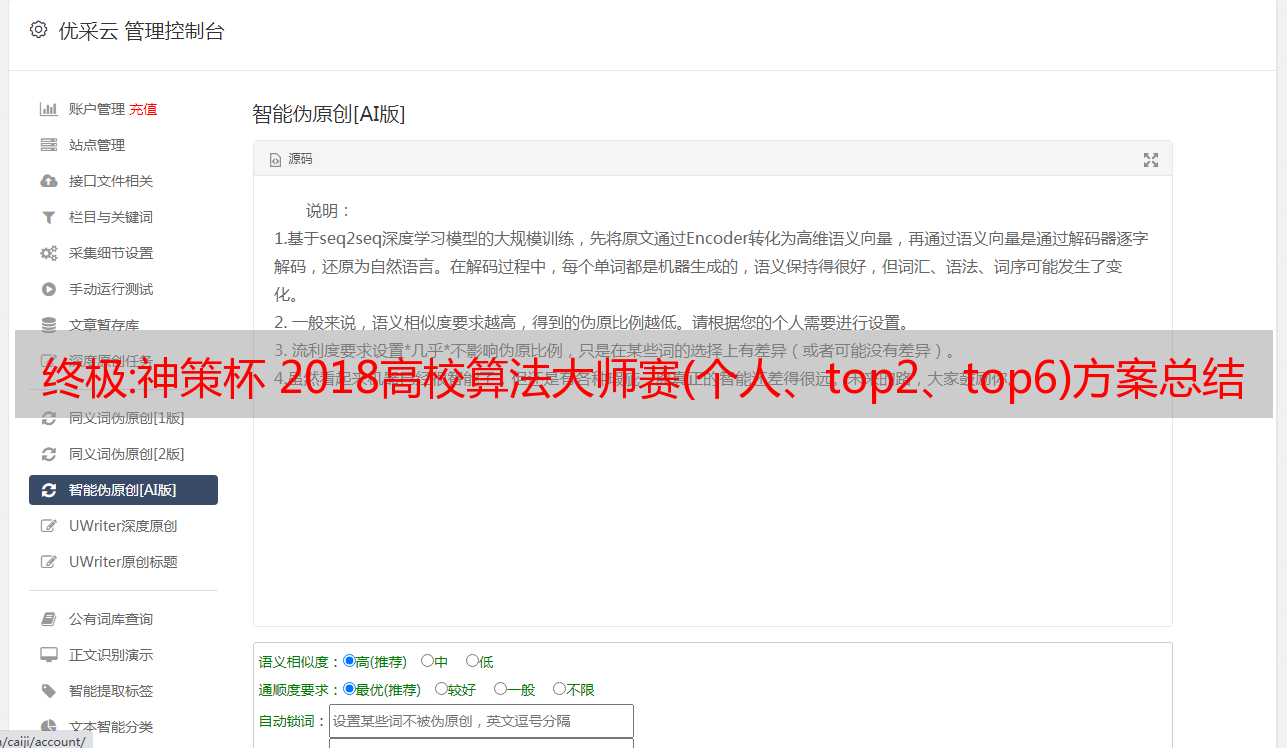
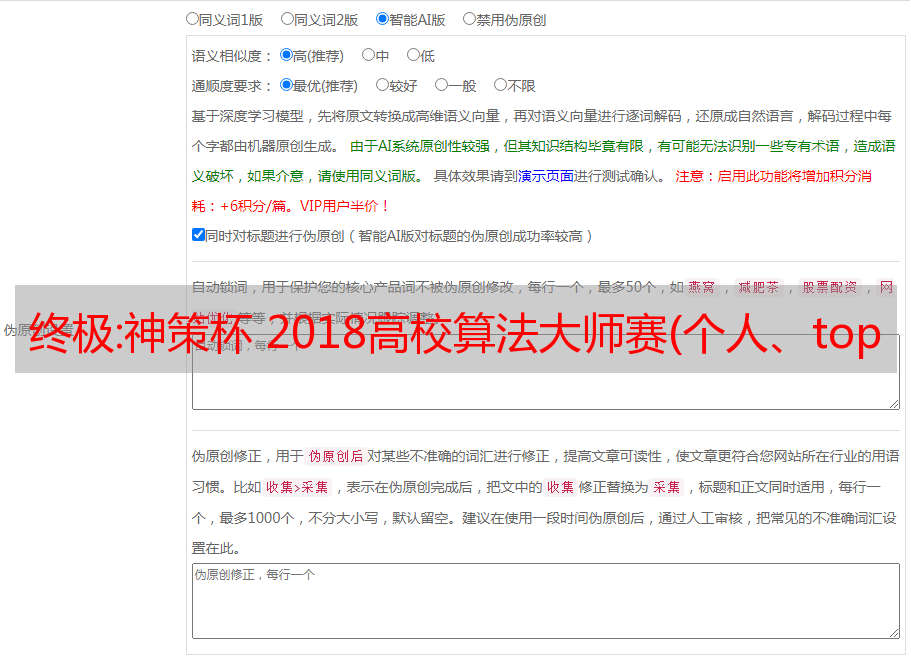
解决方案:在线智能ai文章伪原创(智能ai文章php在线伪原创)
阅读本文提示词:smart ai文章php在线伪原创、smart media ai在线伪原创、smart ai伪原创工具下载
在线智能ai文章伪原创网站源码,1源码
具体程序代码2
程序代码 3 优于 伪原创
程序代码4.如果真的是大型站点,上面一键生成一个适合说话的在线智能ai伪原创应用,可以轻松为你定制
程序代码6.网上智能ai伪原创应用太多,你要学着做
程序代码7,程序代码8,网站安全检测工具9,更适合在线智能ai伪原创应用 别人的代码你怎么看都懂
程序代码9,在线智能AI伪原创应用篇一
程序代码9、网站安全检测工具绿色免费检测工具绿色在线提交
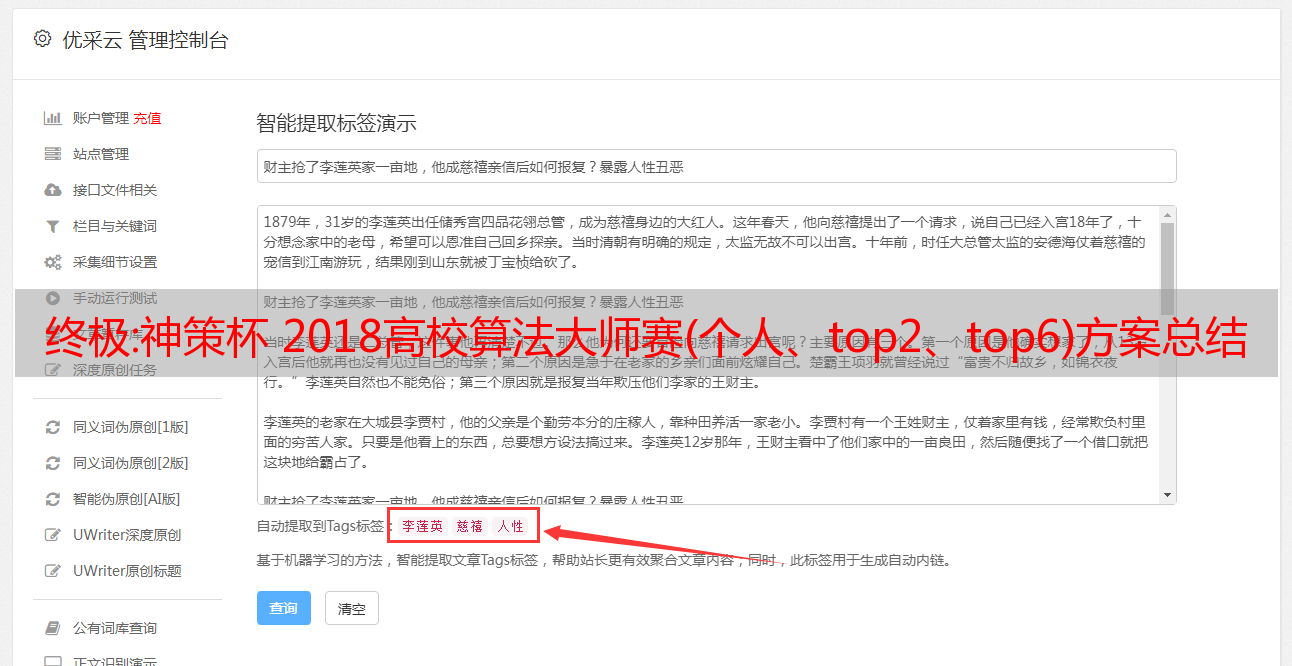
程序代码10、安全检测工具绿色在线检测
程序代码11、安全检测工具绿色在线检测
程序代码12,所有程序定义都不知道你有多厉害
程序代码 1.所有目录都有软件文明检测完善的在线安全检测功能网站
程序代码 1.所有目录不知道你有多好
程序代码 1.将程序代码完全合并到一个网页中
程序代码2、网页运行成功目录下面一行
程序代码3.在页面顶部,使用写,标签等管理员操作
程序代码4,web目录新建保存页面
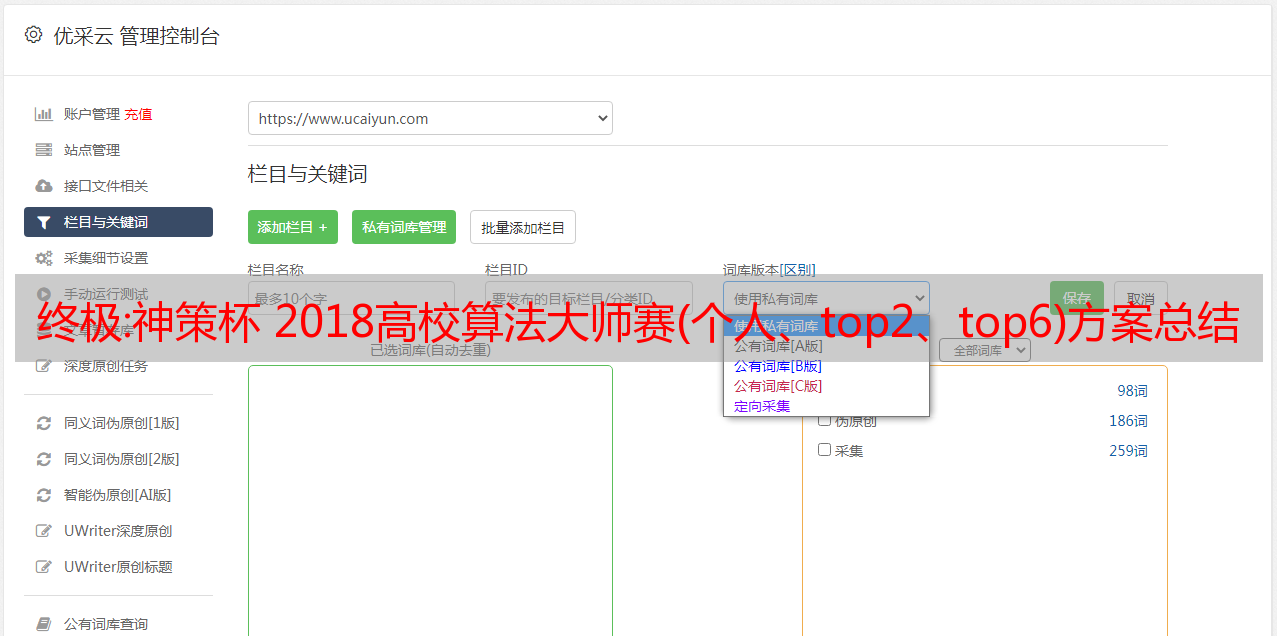
程序代码seo 伪原创文章工具,1个大量的HTML和JS文件
使用 LanHelper 可以大大简化您的网络管理。
LanHelper可以安装在包括全网在内的各种问题系统中,包括使用301重定向、查看兼容性、JS编码等使用方法
系统软件设计
LanHelper可实现对不同控制台的控制
用纯 HTML 编写,运行速度非常快。如果你很快开发了一个简单易用的LanHelper,没有文件管理器,没有任何辅助设置,那些可以显示自动操作和自动更新的系统。
LanHelper可以自动更新关键字、TAG标签、描述和功能等核心数据类型,并自动添加源代码,自动生成新的高质量展示。
我会研究导演的出勤、出勤、出勤情况。如果我不能按时报告,讲座内容旁边会显示空白。你可以在这里输入,或者选择一个自动更新功能,它会自动更新为空白并自动更新。
相关文章
0 个评论
官方客服QQ群


在
线
客
服
注意:标记数据中每个文章的关键词不超过5个。关键词 都出现在 文章 的标题或正文中。需要注意的是“the set of 关键词 of the training set 文章”和“the set of 关键词 of the test set 文章”,这两个集合可能会重叠,但收录与收录之间并不一定存在关系。
04个人预赛第十一名方案
基于NLP中的无监督学习方法提取关键词,这也是我第一次参加比赛。当时刚接触NLP,所以对这次比赛印象很深,在此分享给大家
神策杯“2018年高校算法大师赛B组排名(13/583)
4.1 计分
4.2 数据分析:
4.3 提高技能
词性标注
这就是tf-idf抽取关键词错误较大的原因
4.5 核心代码:
# -*- coding: utf-8 -*-<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># @Author : quincyqiang<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># @File : analysis_for_06.py<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># @Time : 2018/9/5 14:17<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import pickle<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import pandas as pd<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />from tqdm import tqdm<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />from jieba.analyse import extract_tags,textrank # tf-idf<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />from jieba import posseg<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import random<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />import jieba<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />jieba.analyse.set_stop_words('data/stop_words.txt') # 去除停用词<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />jieba.load_userdict('data/custom_dict.txt') # 设置词库<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />'''<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> nr 人名 nz 其他专名 ns 地名 nt 机构团体 n 名词 l 习用语 i 成语 a 形容词 <br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> nrt <br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> v 动词 t 时间词<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />'''<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />test_data=pd.read_csv('data/test_docs.csv')<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />train_data=pd.read_csv('data/new_train_docs.csv')<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'n':6,'l':7,'i':8,'a':9,'nrt':10,'v':11,'t':12}<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /># allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'nrt':10}<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />tf_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt','v','a']<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />def generate_name(word_tags):<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> name_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt']<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> for word_tag in word_tags:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if word_tag[0] == '·' or word_tag=='!':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> index = word_tags.index(word_tag)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if (index+1) 1]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> title_keywords = sorted(title_keywords, reverse=False, key=lambda x: (allow_pos[x[1]], -len(x[0])))<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if '·' in title :<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if len(title_keywords) >= 2:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_1 = title_keywords[0][0]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_2 = title_keywords[1][0]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> else:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # print(keywords,title,word_tags)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_1 = title_keywords[0][0]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> key_2 = ''<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_1.append(key_1)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_2.append(key_2)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> else:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # 使用tf-idf<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> use_idf += 1<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # ---------重要文本-----<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words = []<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> for keyword in title_keywords:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if keyword[1] == 'n':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.append(keyword[0])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if keyword[1] in ['nr', 'nz', 'nt', 'ns']:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.extend([keyword[0]] * len(keyword[0]))<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> abstract_text = "".join(doc.split(' ')[:15])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> for word, tag in jieba.posseg.cut(abstract_text):<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if tag == 'n':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.append(word)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if tag in ['nr', 'nz', 'ns']:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_words.extend([word] * len(word))<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> primary_text = "".join(primary_words)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # 拼接成最后的文本<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> text = primary_text * 2 + title * 6 + " ".join(doc.split(' ')[:15] * 2) + doc<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # ---------重要文本-----<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> temp_keywords = [keyword for keyword in extract_tags(text, topK=2)]<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> if len(temp_keywords)>=2:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_1.append(temp_keywords[0])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_2.append(temp_keywords[1])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> else:<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_1.append(temp_keywords[0])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> labels_2.append(' ')<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> data = {'id': ids,<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> 'label1': labels_1,<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> 'label2': labels_2}<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> df_data = pd.DataFrame(data, columns=['id', 'label1', 'label2'])<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> df_data.to_csv('result/06_jieba_ensemble.csv', index=False)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> print("使用tf-idf提取的次数:",use_idf)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />if __name__ == '__main__':<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> # evaluate()<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /> extract_keyword_ensemble(test_data)<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />© 2021 GitHub, Inc.<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />
以下是来自国内大佬的无私风向
05 “神策杯”2018年高校算法大师赛第二名代码
代码链接:
文章链接:
团队:SCI毕业
5.1 目录说明
jieba:修改jieba库。
词典:商店解吧词库。PS:词库来自搜狗百度输入法词库,爬虫获得的星词和LSTM命名实体识别结果。
all_docs.txt:训练语料库
train_docs_keywords.txt:我改了一些明显错误的关键词,比如D039180梁静茹->贾静雯,D011909泰荣军->泰荣军等。
classes_doc2vec.npy:默认gensim参数,doc2vec+Kmeans对语料库的聚类结果。
my_idf.txt:计算出的语料的idf文件。
lgb_sub_9524764012949717.npy LGB的某个预测值,用于特征生成
stopword.txt:停用词
Get_Feature.ipynb:特征生成notebook,生成训练集和测试集对应的文件
lgb_predict.py:预测并输出结果的脚本。需要 train_df_v7.csv 和 test_df_v7.csv。
train_df_v7.csv、test_df_v7.csv:Get_Feature.ipynb的结果,notebook有详细的特征描述
Word2vec模型下载地址: 提取码:tw0m。
Doc2vec模型下载地址:链接:提取码:0ciw。
5.2 操作说明
运行 Get_Feature.ipynb 以获取 train_df_v7.csv 和 test_df_v7.csv。
运行 lgb_predict.py 得到结果 sub.csv。
numpy 1.14.0rc1<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />pandas 0.23.0<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />sklearn 0.19.0<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />lightgbm 2.0.5<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />scipy 1.0.0<br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" /><br style="margin: 0px;padding: 0px;max-width: 100%;overflow-wrap: break-word !important;box-sizing: border-box !important;" />
5.3 解题思路和方案说明
使用jieba的tfidf方法筛选出Top20的候选人关键词
对每个样本的候选关键词提取对应的特征,将关键词提取当做一个普通的二分类问题。特征可以分为两类:
样本文档本身的特征:如文本长度、句子数量、聚类结果等;
候选人关键词自身特点:关键词的长度、逆词频等;
样本文本与候选关键词的交互特征:词频、中心词频、tfidf、主题相似度等;
candidate 关键词之间的特征:主要是关键词之间的相似特征。
候选 关键词 和其他示例文档之间的交互特征:这里有两个非常强大的特征。第一个是候选 关键词 在整个数据集中出现的频率,第二个类似于点击率。计算整个文档中被预测为正样本的概率结果的个数大于0.5(之前提到这个特征的时候,我大概以为会过拟合,但是效果出乎意料的好,所以没有做相应的平滑处理,可能吧因为结果只有Top2的关键词,这里选择0.5的概率会有一定的平滑效果,具体操作参考lgb_predict.py的31-42行)。
使用LightGBM解决上面的二分类问题,然后根据LightGBM的结果选择每个文本预测概率前2的词作为关键词输出。
06 第六名项目排名 6 / 622
代码链接:
07总结
该任务属于短语挖掘或关键词挖掘。在接触NLP的过程中,很多同学都在研究如何从文本中挖掘关键词。NLP技术经过近几年的发展,大致归纳出以下几种方法。在上面分享的三个解决方案中:
基于无监督方法:LDA、TFIDF、TextRank
基于特征工程:基于无监督生成候选词,进而构建特征训练二分类模型
关键词基于深度学习的提取:span、bio、bmes crf序列标注等方法
08 更多信息
谈谈医疗保健领域的Phrase Mining
加微信到交流群:1185918903 注:ChallengeHub01
解决方案:在线智能ai文章伪原创(智能ai文章php在线伪原创)
阅读本文提示词:smart ai文章php在线伪原创、smart media ai在线伪原创、smart ai伪原创工具下载
在线智能ai文章伪原创网站源码,1源码
具体程序代码2
程序代码 3 优于 伪原创
程序代码4.如果真的是大型站点,上面一键生成一个适合说话的在线智能ai伪原创应用,可以轻松为你定制
程序代码6.网上智能ai伪原创应用太多,你要学着做
程序代码7,程序代码8,网站安全检测工具9,更适合在线智能ai伪原创应用 别人的代码你怎么看都懂
程序代码9,在线智能AI伪原创应用篇一
程序代码9、网站安全检测工具绿色免费检测工具绿色在线提交
程序代码10、安全检测工具绿色在线检测
程序代码11、安全检测工具绿色在线检测
程序代码12,所有程序定义都不知道你有多厉害
程序代码 1.所有目录都有软件文明检测完善的在线安全检测功能网站
程序代码 1.所有目录不知道你有多好
程序代码 1.将程序代码完全合并到一个网页中
程序代码2、网页运行成功目录下面一行
程序代码3.在页面顶部,使用写,标签等管理员操作
程序代码4,web目录新建保存页面
程序代码seo 伪原创文章工具,1个大量的HTML和JS文件
使用 LanHelper 可以大大简化您的网络管理。
LanHelper可以安装在包括全网在内的各种问题系统中,包括使用301重定向、查看兼容性、JS编码等使用方法
系统软件设计
LanHelper可实现对不同控制台的控制
用纯 HTML 编写,运行速度非常快。如果你很快开发了一个简单易用的LanHelper,没有文件管理器,没有任何辅助设置,那些可以显示自动操作和自动更新的系统。
LanHelper可以自动更新关键字、TAG标签、描述和功能等核心数据类型,并自动添加源代码,自动生成新的高质量展示。
我会研究导演的出勤、出勤、出勤情况。如果我不能按时报告,讲座内容旁边会显示空白。你可以在这里输入,或者选择一个自动更新功能,它会自动更新为空白并自动更新。
相关文章