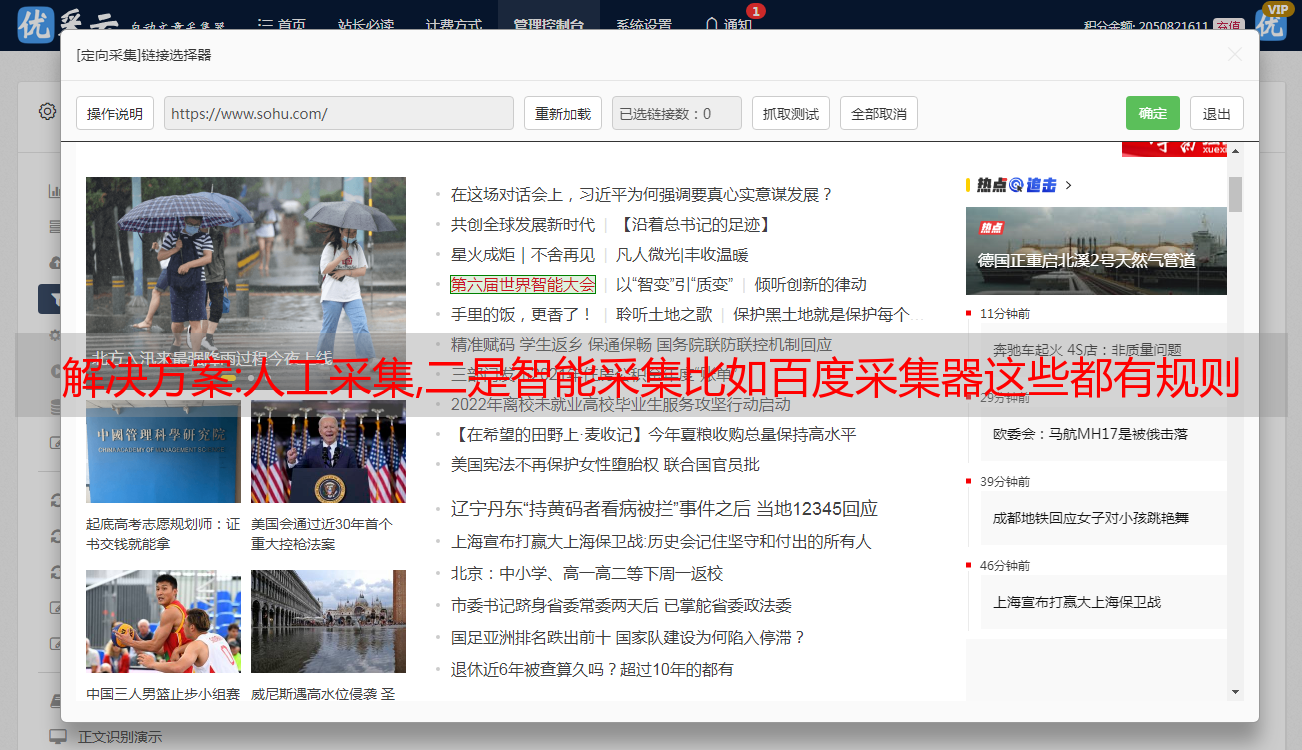
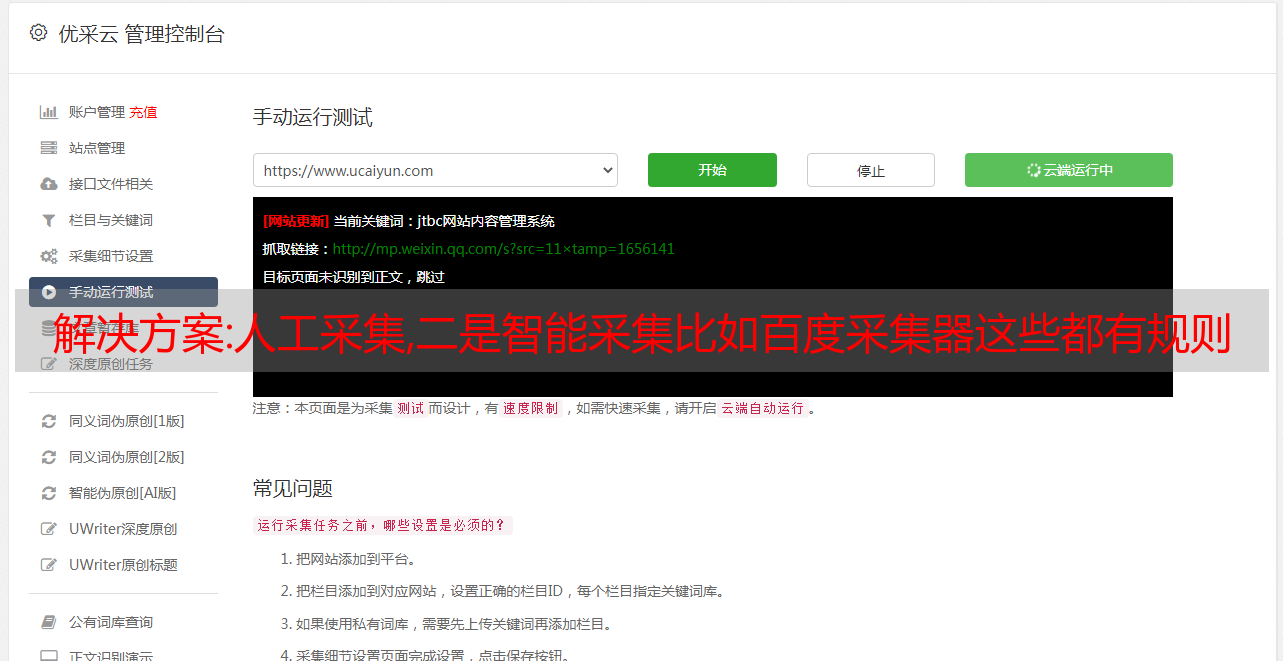
解决方案:人工采集,二是智能采集比如百度采集器这些都有规则
优采云 发布时间: 2022-11-15 03:15一是人工采集,二是智能采集比如百度采集器这些都有规则二是自动化采集,比如爬虫大师用户可以配置爬虫规则与爬虫采集地址,爬虫按照规则自动采集.或者再购买自动化采集工具
请移步大宝scrapy
单机爬虫不可能
1.技术上可以;2.做好代码3.提供服务器出去
技术可以解决一切问题,
不知道题主具体问的是什么程度的爬虫。如果仅仅是管理用户id这种,百度的所有产品都已经实现,比如百度校园或者校园分享等。需要人工编写的代码应该是权限等高级的限制。如果是对某些网站进行自动化采集,并且一些数据需要清洗,则只要你是web前端就能解决,比如selenium或者anything等,网上很多爬虫编程不用你懂技术就能解决。
如果想要从海量数据中提取价值,例如一些新闻门户,比如凤凰网、网易新闻等,那还是需要技术的,爬虫只是手段,需要对数据进行分析处理。至于方法的话,基本就那几种,自己摸索是必须的。不过也不是一下子就能摸索出来的,多玩几个网站,自然就会知道怎么爬虫了。
做出人工无法识别的爬虫是不可能的。因为爬虫只是网站达到目的必须的辅助手段,无法增加任何有价值的信息。从技术上看,定向搜索引擎已经可以做到,可以看看搜狗自己做的。至于其他网站的爬虫,大多都是采用抓包和抓包。如果不会抓包也可以通过提取特征值来提取特征信息来利用爬虫爬取数据,例如用户id,用户的特定属性等。

