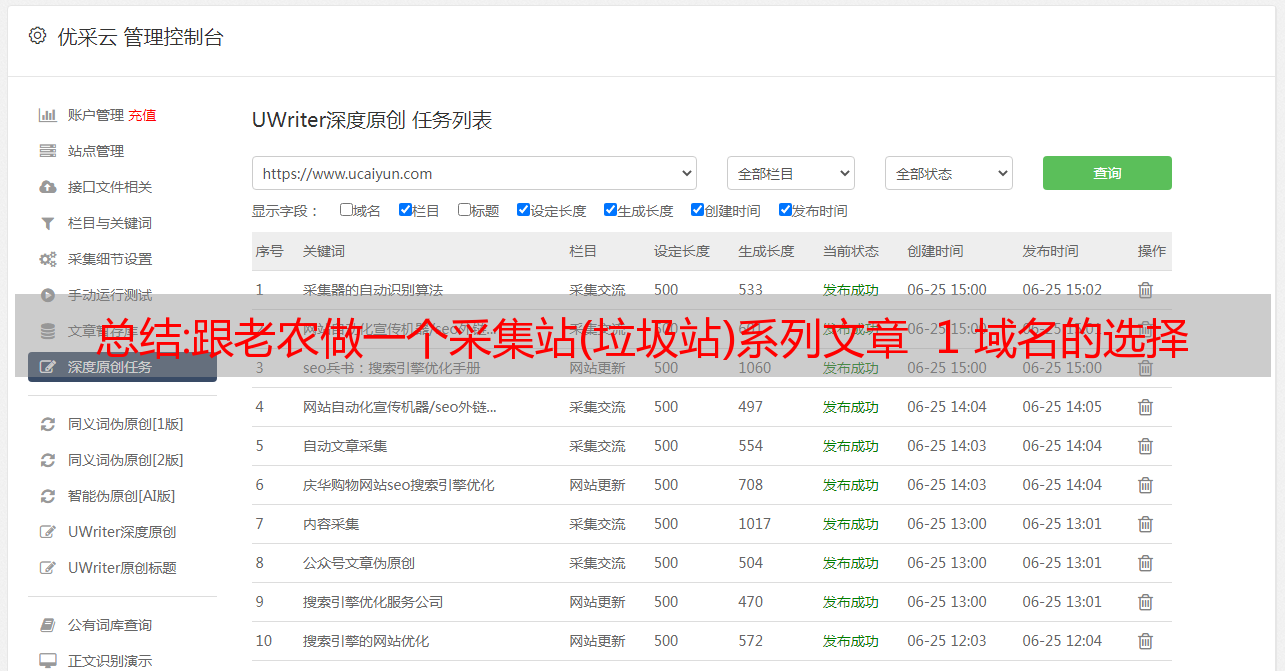
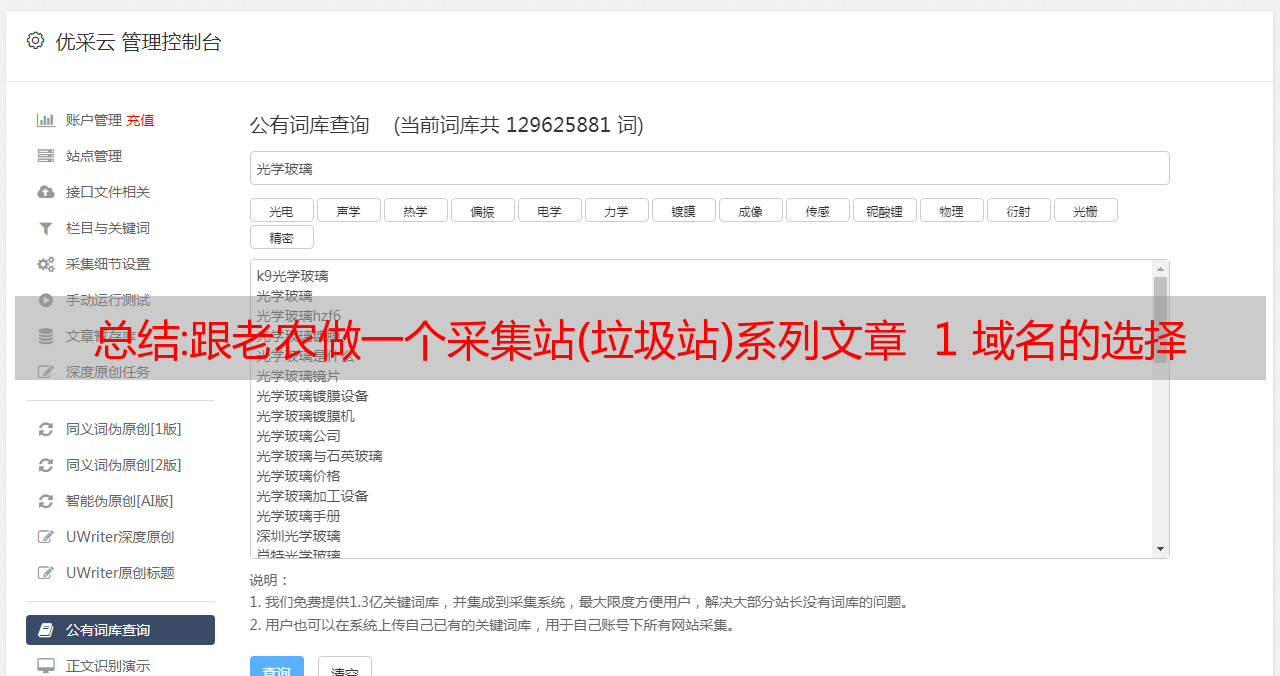
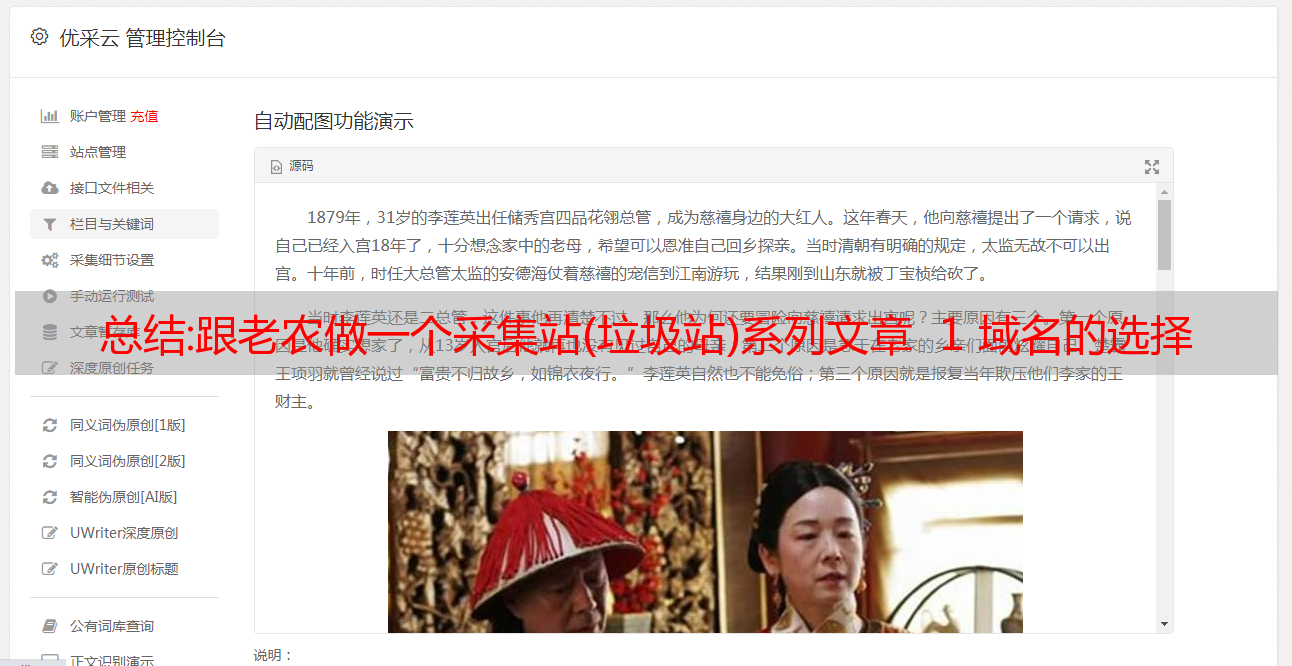
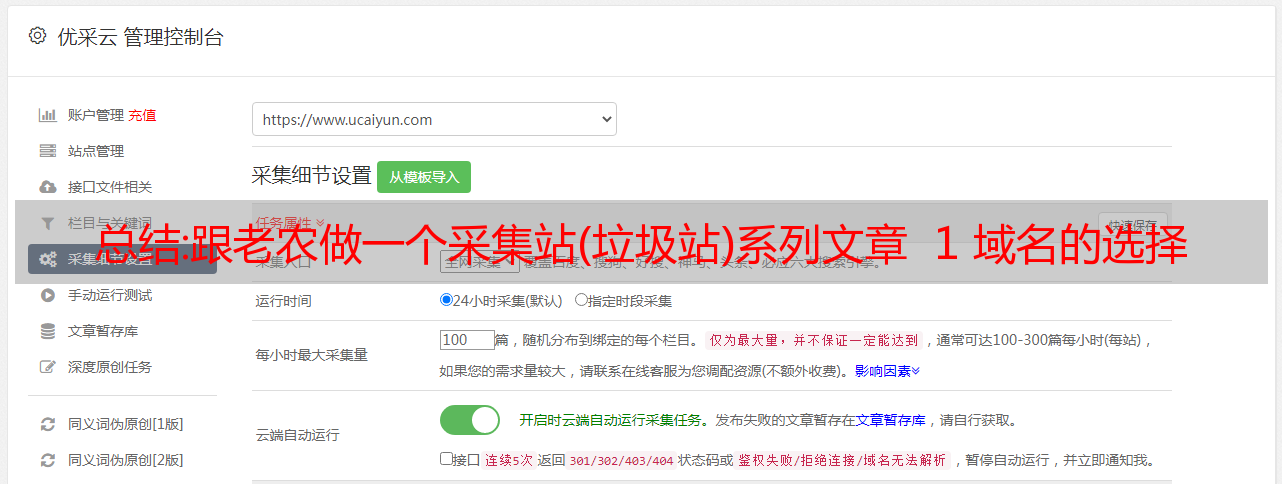
总结:跟老农做一个采集站(垃圾站)系列文章 1 域名的选择
优采云 发布时间: 2022-11-14 19:35总结:跟老农做一个采集站(垃圾站)系列文章 1 域名的选择
关于选择域名
事实上,这很简单。几字几字的长篇大论很难写出来。
这些都是非常基础的东西,很多互联网老手可能没有意识到选择一个域名有多么困难。
总而言之,只要选择一个你觉得赏心悦目的。
除了投资域名时要考虑的因素外,域名的选择主要包括以下几点
1 尝试使用 .com 的
com 代表公司,com 域名的比例在全球占有巨大的市场份额。选择com有利于访客的快速识别。
做一个简单的类比,
affadsense.coop 和
你觉得谁容易记住?
或和
请记住,我只需要记住 affadsense,而且我必须记住一个 .net 后缀。
2 为您的域名添加关键字
域名是否收录关键字在SEO优化中也起着不小的作用。这样,通过搜索关键词,其他人就会在搜索页面上显示你的域名,其他人也可以通过域名一目了然地知道你的网站是关于什么的。
3 保持简短
尽管关键字很重要,但请尽量简短。我的建议是域名的长度不要超过15个字符,否则访问者不会记住你的域名,你就会失去那些老访问者的流量。
4 域名应尽可能合乎逻辑
换句话说,它容易拼写和记忆,更容易类比理解。
affadsense是由aff和adsense组成的,这样理解,域名就很容易记住了。
还有 fafdasense,你怎么记得的?
5 避免 - 符号出现
例如,你的域名是这样的,除非你记得——否则访问者很容易跑到它。另外,如果你使用连字符,我会考虑去掉连字符,看看是什么网站,也就是说,总有一些游客好奇,所以如果你跑到竞争对手的网站,您将免费发送流量。
选择域名注册商
1 如果可能,请尽可能选择外国注册商
中国好像需要实名制。虽然可以换成别人的*敏*感*词*,但到头来还是比较麻烦的。如果还能出国,建议出国。
另外,如果域名遇到版权投诉等问题,国外域名注册商会提前几天联系您,让您有个处理流程。近年来,我对中国的情况并不了解。丢失了一些已经完成的 网站。
2 哪个域名最便宜?
正好小密圈里有人问我,怎么有人可以1块钱注册一个com域名。
总结:【Python实战】年底找工作,年后不用愁
前言
有温度有深度有广度,只等你关注~
所有文章完整资料+源码都在
嫖娼源码利益的粉丝,请移步CSDN社区或文末公众号。
你好!我是栗子同学,今天继续更新~说说找工作的那些事儿~
PS——短篇小说
“*敏*感*词*姐”目前在长沙一家物业公司做客服,月薪只有3-4千。
我抱怨她前段时间刚辞职,问我年底找工作难不难?
其实一年四季都在问类似的问题,“年初找工作容易吗?” “一月份找工作容易吗?” “二月份找工作容易吗?”
? “我一直在问“12月好找工作吗?” “年底好找工作吗?“……
今天小编就用代码给大家一个统一的答案——大招聘网站《某流程无忧》《了解大企业》
招聘人才需求~
文“乔优”(纳斯达克股票代码:JOBS)是在中国具有广泛影响力的人力资源服务商,在美国上市的中国人力资源服务企业。运用网络媒体和先进的移动终端信息技术,加上经验丰富的专业顾问团队,提供包括招聘猎头、培训评估、人才外包等全方位的专业人力资源服务,现已服务于全国25个城市。中国领先的专业人力资源服务机构。
一、运行环境 1)Python环境
环境:Python 3、Pycharm、请求。其他内置模块(无需安装re json csv),已安装
python环境很好。(win+R,输入cmd,输入安装命令pip install 模块名(如果觉得安全的话
安装速度比较慢,可以切换国内镜像源))
2)第三方库的安装:
pip install + 模块名称或 pip install -i + 带有镜像源的模块名称
2. 代码实现 1) 代码思路
1.数据源分析只有当我们知道,我们想要采集数据在哪里
分析数据来源: 1、使用浏览器自带工具-->开发者工具抓包分析-F12或右键勾选选择网络-刷新网页内容让本网页数据内容,重新加载再说一遍。
2.分析我们想要的数据内容在哪里?- 开发者工具:搜索功能可以搜索我们想要的数据内容,在哪个数据包中。
2.代码实现步骤
1.发送请求,模拟浏览器向url地址发送请求
2.获取数据,获取服务器显示的响应数据返回响应数据如开发者工具中所见
3.解析数据,提取我们想要的数据内容,以及招聘岗位的基本信息
4. 保存数据,将数据信息保存在表格中 2) 主程序
# 数据请求模块
import requests
# 导入正则表达式模块
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv
# 创建文件
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'职位',
'公司',
'城市',
<p>
'经验',
'*敏*感*词*',
'薪资',
'福利',
'公司领域',
'公司规模',
'公司性质',
'发布日期',
'公司详情页',
'职位详情页',
])
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- 需要模块
- 模拟浏览器, 是用什么伪装模拟的
请求头
- 批量替换方法:
1. 选择替换内容, ctrl + R
2. 点击 .*
3. 输入正则命令 进行替换
(.*?): (.*)
'
': '总结:跟老农做一个采集站(垃圾站)系列文章 1 域名的选择
优采云 发布时间: 2022-11-14 19:35总结:跟老农做一个采集站(垃圾站)系列文章 1 域名的选择
关于选择域名
事实上,这很简单。几字几字的长篇大论很难写出来。
这些都是非常基础的东西,很多互联网老手可能没有意识到选择一个域名有多么困难。
总而言之,只要选择一个你觉得赏心悦目的。
除了投资域名时要考虑的因素外,域名的选择主要包括以下几点
1 尝试使用 .com 的
com 代表公司,com 域名的比例在全球占有巨大的市场份额。选择com有利于访客的快速识别。
做一个简单的类比,
affadsense.coop 和
你觉得谁容易记住?
或和
请记住,我只需要记住 affadsense,而且我必须记住一个 .net 后缀。
2 为您的域名添加关键字
域名是否收录关键字在SEO优化中也起着不小的作用。这样,通过搜索关键词,其他人就会在搜索页面上显示你的域名,其他人也可以通过域名一目了然地知道你的网站是关于什么的。
3 保持简短
尽管关键字很重要,但请尽量简短。我的建议是域名的长度不要超过15个字符,否则访问者不会记住你的域名,你就会失去那些老访问者的流量。
4 域名应尽可能合乎逻辑
换句话说,它容易拼写和记忆,更容易类比理解。
affadsense是由aff和adsense组成的,这样理解,域名就很容易记住了。
还有 fafdasense,你怎么记得的?
5 避免 - 符号出现
例如,你的域名是这样的,除非你记得——否则访问者很容易跑到它。另外,如果你使用连字符,我会考虑去掉连字符,看看是什么网站,也就是说,总有一些游客好奇,所以如果你跑到竞争对手的网站,您将免费发送流量。
选择域名注册商
1 如果可能,请尽可能选择外国注册商
中国好像需要实名制。虽然可以换成别人的*敏*感*词*,但到头来还是比较麻烦的。如果还能出国,建议出国。
另外,如果域名遇到版权投诉等问题,国外域名注册商会提前几天联系您,让您有个处理流程。近年来,我对中国的情况并不了解。丢失了一些已经完成的 网站。
2 哪个域名最便宜?
正好小密圈里有人问我,怎么有人可以1块钱注册一个com域名。
总结:【Python实战】年底找工作,年后不用愁
前言
有温度有深度有广度,只等你关注~
所有文章完整资料+源码都在
嫖娼源码利益的粉丝,请移步CSDN社区或文末公众号。
你好!我是栗子同学,今天继续更新~说说找工作的那些事儿~
PS——短篇小说
“*敏*感*词*姐”目前在长沙一家物业公司做客服,月薪只有3-4千。
我抱怨她前段时间刚辞职,问我年底找工作难不难?
其实一年四季都在问类似的问题,“年初找工作容易吗?” “一月份找工作容易吗?” “二月份找工作容易吗?”
? “我一直在问“12月好找工作吗?” “年底好找工作吗?“……
今天小编就用代码给大家一个统一的答案——大招聘网站《某流程无忧》《了解大企业》
招聘人才需求~
文“乔优”(纳斯达克股票代码:JOBS)是在中国具有广泛影响力的人力资源服务商,在美国上市的中国人力资源服务企业。运用网络媒体和先进的移动终端信息技术,加上经验丰富的专业顾问团队,提供包括招聘猎头、培训评估、人才外包等全方位的专业人力资源服务,现已服务于全国25个城市。中国领先的专业人力资源服务机构。
一、运行环境 1)Python环境
环境:Python 3、Pycharm、请求。其他内置模块(无需安装re json csv),已安装
python环境很好。(win+R,输入cmd,输入安装命令pip install 模块名(如果觉得安全的话
安装速度比较慢,可以切换国内镜像源))
2)第三方库的安装:
pip install + 模块名称或 pip install -i + 带有镜像源的模块名称
2. 代码实现 1) 代码思路
1.数据源分析只有当我们知道,我们想要采集数据在哪里
分析数据来源: 1、使用浏览器自带工具-->开发者工具抓包分析-F12或右键勾选选择网络-刷新网页内容让本网页数据内容,重新加载再说一遍。
2.分析我们想要的数据内容在哪里?- 开发者工具:搜索功能可以搜索我们想要的数据内容,在哪个数据包中。
2.代码实现步骤
1.发送请求,模拟浏览器向url地址发送请求
2.获取数据,获取服务器显示的响应数据返回响应数据如开发者工具中所见
3.解析数据,提取我们想要的数据内容,以及招聘岗位的基本信息
4. 保存数据,将数据信息保存在表格中 2) 主程序
# 数据请求模块
import requests
# 导入正则表达式模块
import re
# 导入json
import json
# 导入格式化输出模块
from pprint import pprint
# 导入csv模块
import csv
# 创建文件
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'职位',
'公司',
'城市',
<p>
'经验',
'*敏*感*词*',
'薪资',
'福利',
'公司领域',
'公司规模',
'公司性质',
'发布日期',
'公司详情页',
'职位详情页',
])
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
- 需要模块
- 模拟浏览器, 是用什么伪装模拟的
请求头
- 批量替换方法:
1. 选择替换内容, ctrl + R
2. 点击 .*
3. 输入正则命令 进行替换
(.*?): (.*)
'$1': '$2',
"""
# 确定请求url地址
url = 'https://search.51job.com/list/010000%252C020000%252C030200%252C040000%252C090200,000000,0000,00,9,99,python,2,1.html?u_atoken=0ebd3b84-8a7e-4598-8442-28333687bb0e&u_asession=01LE1DKlBRig-pCserJvEKtcD8FRdkDmxSC9vHIlu9RgicRu619dwho-tcQMpJEh-ZX0KNBwm7Lovlpxjd_P_q4JsKWYrT3W_NKPr8w6oU7K8losFOpWBCXw72NVjjGbeyUe3R9QHfzEvknA4dzJmVTGBkFo3NEHBv0PZUm6pbxQU&u_asig=0509LTGV1DvXMS_d8cXU0jv3xyAuxRHtUv_3iTMcaock6sXe4lMoRzoeNU0-4WRPy8d9VLjYwSYoqZRfrHRzYjSRtEXt_gJnMbngMyKwkcQvy_U3ZscBbWiqZINhCZ6eYI4iBYZ8_0uvXSgelx2P_AmiQIPqS5RvD76Ykjv1qCZTv9JS7q8ZD7Xtz2Ly-b0kmuyAKRFSVJkkdwVUnyHAIJzQlgrzuxIWQIo0fiMVZCpCacmYM5qL-ed1eR5R0F9DTnH_8T8uYGNepqxdb-gLe1IO3h9VXwMyh6PgyDIVSG1W_B5D3kdbrqcgu5uUHKicA6yeddtsgrM7GqljNTK8OvHqzgiKs0HrpHBlhQgs6dylHgSSI0vZrxvglZJr9CZiMwmWspDxyAEEo4kbsryBKb9Q&u_aref=T%2BGBzeflb1FpnfpkX4KDw6w05pw%3D'
# 伪装模拟 headers 字典数据类型
headers = {
# User-Agent 用户代理 浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
}
# 发送请求
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量名response接收返回数据
response = requests.get(url=url, headers=headers)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具里面所看到 response 显示内容
3. 解析数据, 提取我们想要的数据内容
招聘岗位基本信息
response.text 获取响应文本数据 获取html数据
re 会 1 不会 0
- 调用re模块里面findall方法 找到所有我们想要数据
- re.findall('匹配什么数据', '什么地方')
- 从什么地方去匹配找寻什么样的数据内容
- 从 response.text 去找寻 window.__SEARCH_RESULT__ = (.*?) 其中 (.*?) 这段是我们要的数据
- 正则表达式提取出来数据返回 ---> 列表数据类型
print(json_data) 打印字典数据, 显示一行
pprint(json_data) 打印字典数据, 显示多行, 展开效果
type() 内置函数, 查看数据类型
"""
html_data = re.findall('window.__SEARCH_RESULT__ = (.*?)', response.text)[0]
# 转一下数据类型 转成字典数据类型
# 通过字典键值对取值, 提取我们想要的内容 根据冒号左边的内容[键], 提取冒号右边的内容[值]
json_data = json.loads(html_data)
# for循环遍历, 把列表里面的元素一个一个提取出来
for index in json_data['engine_jds']:
dit = {
'职位': index['job_name'],
'公司': index['company_name'],
'城市': index['workarea_text'],
'经验': index['attribute_text'][1],
'*敏*感*词*': index['attribute_text'][-1],
'薪资': index['providesalary_text'],
'福利': index['jobwelf'],
'公司领域': index['companyind_text'],
'公司规模': index['companysize_text'],
'公司性质': index['companytype_text'],
'发布日期': index['issuedate'],
'公司详情页': index['company_href'],
'职位详情页': index['job_href'],
}
csv_writer.writerow(dit)
print(dit)</p>
三、效果展示 1)效果图
2) 效果图
总结
嘿嘿,看完这个效果,是不是真的那么多公司都在招人呢,是不是又自信了呢~
每个月找工作就是这么简单!
欢迎大家点赞、评论、采集,转发这篇文章给需要的朋友,尤其是找工作的朋友,甚至是无助的亲人
朋友。好了,今天的案例到此结束,老规矩源码库搭建完毕。
✨完整的源材料等:你可以给我滴吖!或者文末点hao免费领取~推荐过去文章——
项目0.2【Python实战】WIFI密码小工具,扔掉*敏*感*词*十条街,WIFI随意连接~(附源码)
项目0.3【Python实战】我再分享一个秒杀商品的小工具。我已经把盒子底部的宝物拿出来了~
项目0.1【Python抢票神器】优采云抢票*敏*感*词*票软件靠谱吗?测试 - 终极指南。
项目0.6【Python爬虫实战】使用Selenium爬取一首音乐歌曲和评论信息~
项目0.7【Python爬虫实战】不制作小说,只为网站做搬运工,太牛逼了~(附源码)
文章总结——
Python文章 集合| (进入实战、游戏、海龟、案例等)
(文章总结中还有更多案例供大家学习~可以免费找到源代码!)
0 个评论
官方客服QQ群


在
线
客
服
"""
# 确定请求url地址
url = 'https://search.51job.com/list/010000%252C020000%252C030200%252C040000%252C090200,000000,0000,00,9,99,python,2,1.html?u_atoken=0ebd3b84-8a7e-4598-8442-28333687bb0e&u_asession=01LE1DKlBRig-pCserJvEKtcD8FRdkDmxSC9vHIlu9RgicRu619dwho-tcQMpJEh-ZX0KNBwm7Lovlpxjd_P_q4JsKWYrT3W_NKPr8w6oU7K8losFOpWBCXw72NVjjGbeyUe3R9QHfzEvknA4dzJmVTGBkFo3NEHBv0PZUm6pbxQU&u_asig=0509LTGV1DvXMS_d8cXU0jv3xyAuxRHtUv_3iTMcaock6sXe4lMoRzoeNU0-4WRPy8d9VLjYwSYoqZRfrHRzYjSRtEXt_gJnMbngMyKwkcQvy_U3ZscBbWiqZINhCZ6eYI4iBYZ8_0uvXSgelx2P_AmiQIPqS5RvD76Ykjv1qCZTv9JS7q8ZD7Xtz2Ly-b0kmuyAKRFSVJkkdwVUnyHAIJzQlgrzuxIWQIo0fiMVZCpCacmYM5qL-ed1eR5R0F9DTnH_8T8uYGNepqxdb-gLe1IO3h9VXwMyh6PgyDIVSG1W_B5D3kdbrqcgu5uUHKicA6yeddtsgrM7GqljNTK8OvHqzgiKs0HrpHBlhQgs6dylHgSSI0vZrxvglZJr9CZiMwmWspDxyAEEo4kbsryBKb9Q&u_aref=T%2BGBzeflb1FpnfpkX4KDw6w05pw%3D'
# 伪装模拟 headers 字典数据类型
headers = {
# User-Agent 用户代理 浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
}
# 发送请求
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量名response接收返回数据
response = requests.get(url=url, headers=headers)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具里面所看到 response 显示内容
3. 解析数据, 提取我们想要的数据内容
招聘岗位基本信息
response.text 获取响应文本数据 获取html数据
re 会 1 不会 0
- 调用re模块里面findall方法 找到所有我们想要数据
- re.findall('匹配什么数据', '什么地方')
- 从什么地方去匹配找寻什么样的数据内容
- 从 response.text 去找寻 window.__SEARCH_RESULT__ = (.*?) 其中 (.*?) 这段是我们要的数据
- 正则表达式提取出来数据返回 ---> 列表数据类型
print(json_data) 打印字典数据, 显示一行
pprint(json_data) 打印字典数据, 显示多行, 展开效果
type() 内置函数, 查看数据类型
"""
html_data = re.findall('window.__SEARCH_RESULT__ = (.*?)', response.text)[0]
# 转一下数据类型 转成字典数据类型
# 通过字典键值对取值, 提取我们想要的内容 根据冒号左边的内容[键], 提取冒号右边的内容[值]
json_data = json.loads(html_data)
# for循环遍历, 把列表里面的元素一个一个提取出来
for index in json_data['engine_jds']:
dit = {
'职位': index['job_name'],
'公司': index['company_name'],
'城市': index['workarea_text'],
'经验': index['attribute_text'][1],
'*敏*感*词*': index['attribute_text'][-1],
'薪资': index['providesalary_text'],
'福利': index['jobwelf'],
'公司领域': index['companyind_text'],
'公司规模': index['companysize_text'],
'公司性质': index['companytype_text'],
'发布日期': index['issuedate'],
'公司详情页': index['company_href'],
'职位详情页': index['job_href'],
}
csv_writer.writerow(dit)
print(dit)</p>
三、效果展示 1)效果图
2) 效果图
总结
嘿嘿,看完这个效果,是不是真的那么多公司都在招人呢,是不是又自信了呢~
每个月找工作就是这么简单!
欢迎大家点赞、评论、采集,转发这篇文章给需要的朋友,尤其是找工作的朋友,甚至是无助的亲人
朋友。好了,今天的案例到此结束,老规矩源码库搭建完毕。
✨完整的源材料等:你可以给我滴吖!或者文末点hao免费领取~推荐过去文章——
项目0.2【Python实战】WIFI密码小工具,扔掉*敏*感*词*十条街,WIFI随意连接~(附源码)
项目0.3【Python实战】我再分享一个秒杀商品的小工具。我已经把盒子底部的宝物拿出来了~
项目0.1【Python抢票神器】优采云抢票*敏*感*词*票软件靠谱吗?测试 - 终极指南。
项目0.6【Python爬虫实战】使用Selenium爬取一首音乐歌曲和评论信息~
项目0.7【Python爬虫实战】不制作小说,只为网站做搬运工,太牛逼了~(附源码)
文章总结——
Python文章 集合| (进入实战、游戏、海龟、案例等)
(文章总结中还有更多案例供大家学习~可以免费找到源代码!)