解决方案:如何解决网站文章采集有两种方式?普通网站抓取服务
优采云 发布时间: 2022-11-13 22:39解决方案:如何解决网站文章采集有两种方式?普通网站抓取服务
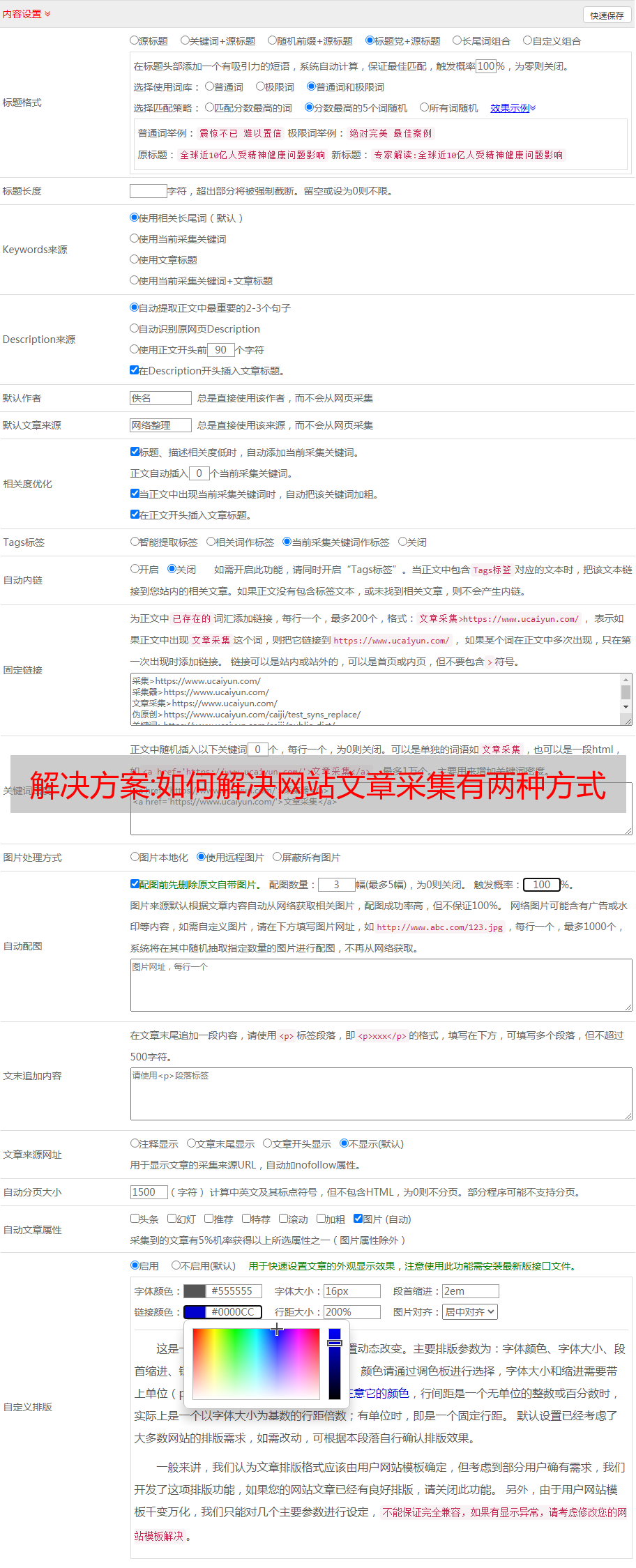
网站文章采集有两种方式:1、网站自动爬虫抓取,但是太依赖网站本身的爬虫算法;2、通过搜索引擎爬虫抓取,但是面临审核问题;解决方案:采集网站文章有三种方式,网站自动抓取,woosextra发布网站爬虫,借助solr/tomcat/h5store通过请求api返回文章数据;(国内的可能做不到,国外可以尝试)。
接过一些cms平台的站群,再自己做了一个效果。其中有一个关键点是高权重网站的内容排名会高一些,排名前列的内容,好的内容一般在很早之前就被网站抓取到了,类似日志,然后会通过xpath找到对应部分网站的数据,填充到站群里。
首先:用的还是千万级网站的内容(尤其是知名网站,有各种频道、专题)第二:每个网站是每日可能有大量文章更新,并且全都是精心挑选过,量级上的差距已经不算什么了第三:该网站有自己的用户关系系统,可以通过对用户的活跃程度、点击信息等信息做对网站内容的推送第四:站长对于网站内容的选择和维护有一定的经验,可以快速发现合适的内容第五:站长对该网站的用户行为信息(如注册、登录、浏览、上传图片、点赞等)也有经验第六:站长与站群的平台运营方、技术相关。
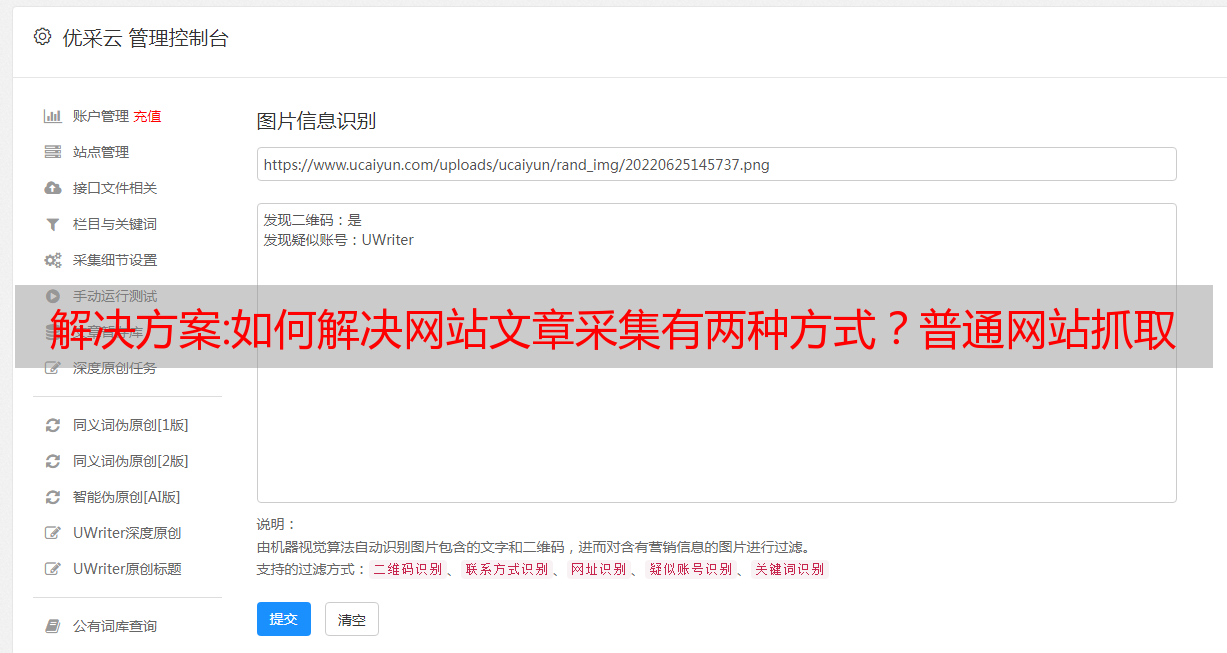
对于网站来说,最核心的价值是在于推荐内容,内容推荐从内容出发。如何让站点内容推荐得到最优化,需要站长把网站更新的内容统一存储在网站中。关于如何解决这个问题呢?普通网站抓取服务肯定不能满足需求。首先需要的就是数据分析服务。比如网站用户信息分析,对应用户的浏览习惯,点击习惯,上传图片信息分析等等。根据这些信息更新网站内容。
再然后根据网站内容的不同来做差异化竞争,比如音乐平台,肯定不能出现视频的信息,因为音乐的歌曲信息太丰富了。博客平台肯定不能出现技术流的内容。长尾的内容肯定比没有用户需求的内容被抓取得到更多。最后才是站点推荐的技术。数据库+xml+关系型数据库已经不能满足推荐的需求了。oracle,mysql都很多年没有更新了。
可以考虑联合的方式来进行。一个网站技术、设计比较复杂。可以给网站引入一些第三方数据库技术厂商,比如informix。通过把网站中的内容用json数据进行压缩导入数据库。避免网站的更新频率受网站自身算法的影响。除此之外,关键点还是网站本身内容的质量。

