解决方案:实时文章采集软件的过程特征选择过程及注意事项介绍
优采云 发布时间: 2022-11-13 18:30解决方案:实时文章采集软件的过程特征选择过程及注意事项介绍
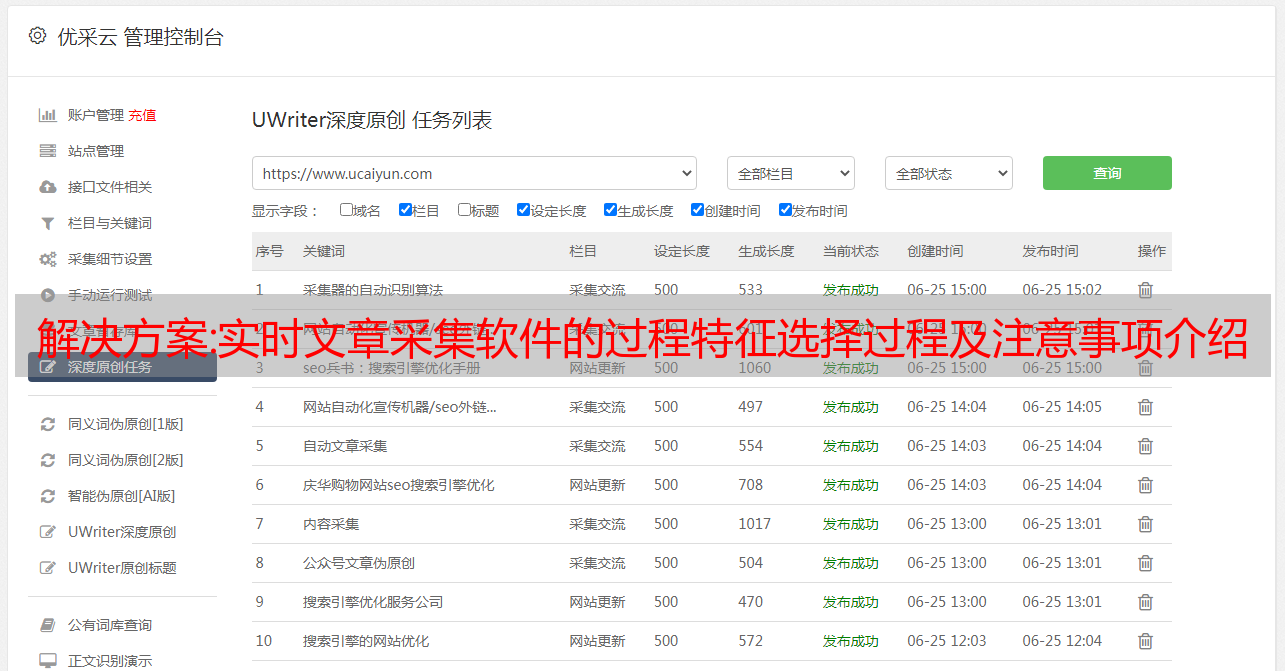
实时文章采集软件也就是在淘宝server端每秒钟抓取任意格式文章的所有字段,比如url标题/地址/文章描述/标签/摘要/评分。然后将所有的字段整合到一个文件中,然后在server端封装成html或者xml的形式来进行搜索。所以对于外层的爬虫的要求就是,每秒钟执行一定数量的get。有代码可供修改。其他的所有页面都是整合,比如输入一个ip,输入一个标签,返回一个dom文件,这个字段含有dom元素。
这个dom文件返回一个xml文件,xml文件里面可以是ajax格式的数据,你可以自己设置一个外层url。所以实时文章采集本质是伪代码。
实时采集嘛,restful架构。爬虫本身一般也是restful架构。你需要一个代理服务器,来保证合法性,速度和安全性。url匹配,这就是一个正则表达式匹配的过程,特征选择过程。一般用beautifulsoup或者xpath之类的restfulapi。具体内容自己看githubapi。当然,你如果是用chrome的代理extension和fiddler之类的,通过各种手段firebug也能模拟。
好像,需要一个集群性质的dns请求服务器可以帮助你实现抓取。
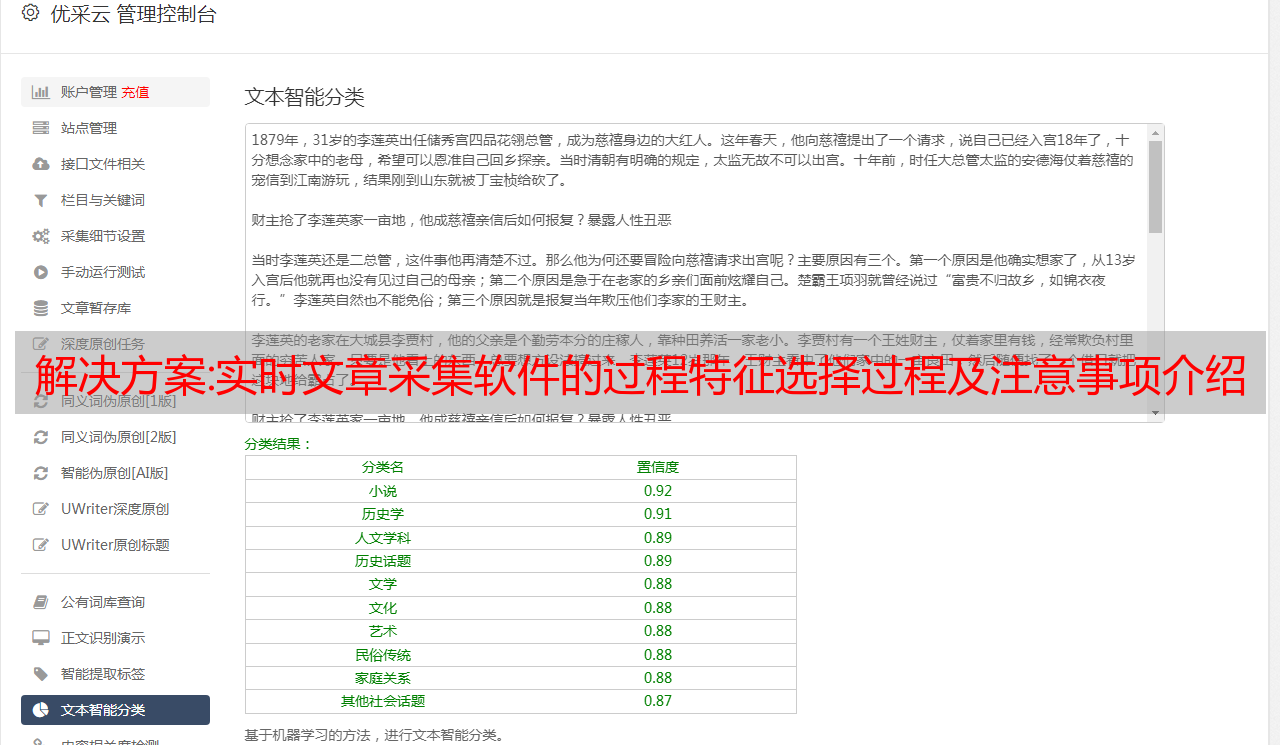
没研究过,我的网站,需要的是一个node.js+express的web服务器,
网页要有各种元素
正好我们也在做搜索引擎,做下api+搜索然后拼接字段的效果。用api可以实现非常好的兼容性。直接生成html格式的字段数据。网页抓取也可以利用api直接生成content-type正则表达式。

