解决方案:拼多多跨境电商平台Temu已上线,Temu一键铺货软件推荐
优采云 发布时间: 2022-11-13 13:54解决方案:拼多多跨境电商平台Temu已上线,Temu一键铺货软件推荐
2022年8月,晚邮报道称,拼多多的跨境电商平台模式将效仿中国最大的独立跨境电商站SheIn。“多多购物”的多名一级主管已调到该项目。拼多多跨境电商卖家只需发货到拼多多指定的国内仓库,由拼多多官方定价。
9月1日,拼多多跨境电商平台海外正式上线。平台取名为特木,App Store应用详情页显示“Team Up,Price Down”的意思,与国内名称拼多多类似,即买的人越多,价格越低,但目前还没有APP内“*敏*感*词*”下单的营销方式。
Temu PC版和App版均已上线,iOS版APP大小为43.2MB
那么特木卖家如何快速配货,开始掘金呢?
一、注册望京网ERP账号,点击注册>>>望京网ERP
产品采集
鼠标移动到产品导航栏,选择产品采集进入采集模块
采集分为多种采集方法,这个主要是大家自己研究采集配置来解释
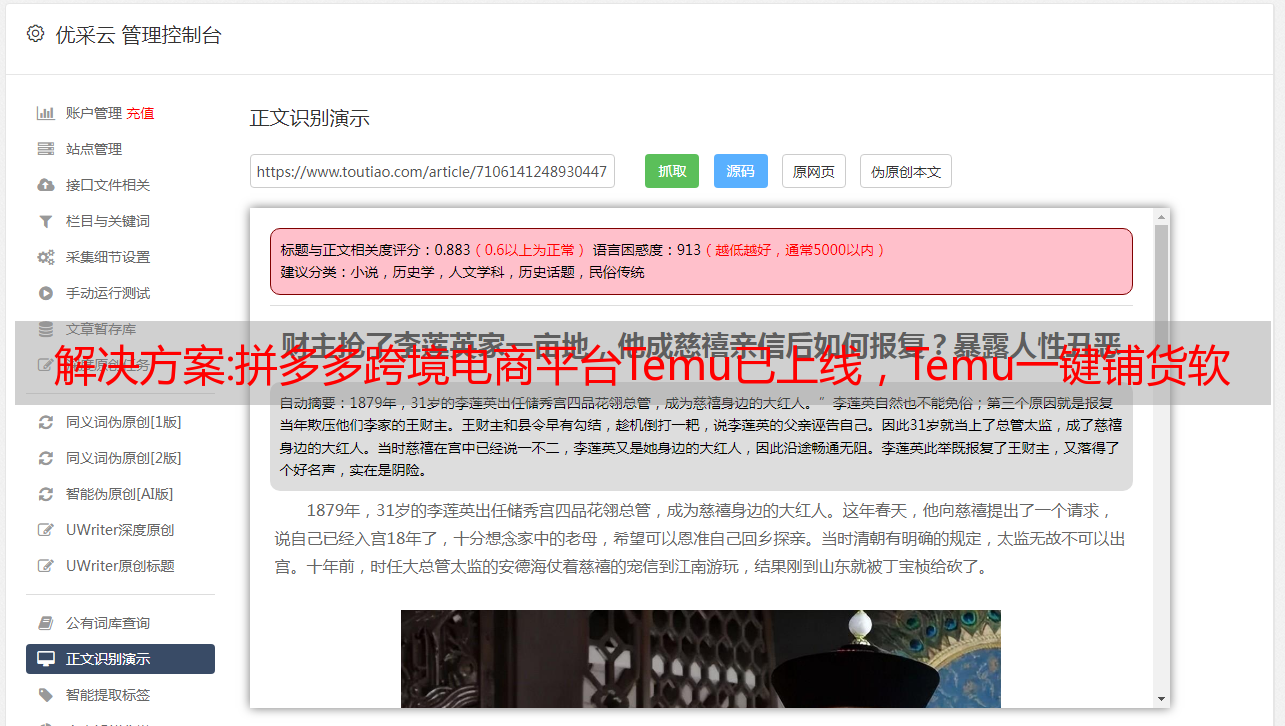
采集配置 - 单击 采集 右侧的设置图标按钮。配置采集
产品采集-声明配置
自称平台==“分发到对应店铺==分发===”发布
系统可实现从采集到发布的自动化操作
可以在任何步骤中断,如:向平台索赔==》分发到相应的商店
产品采集 - 编辑配置
编辑配置为批量编辑,执行采集时可以自动编辑
注意:前提是索赔配置必须选择平台
1.
2.
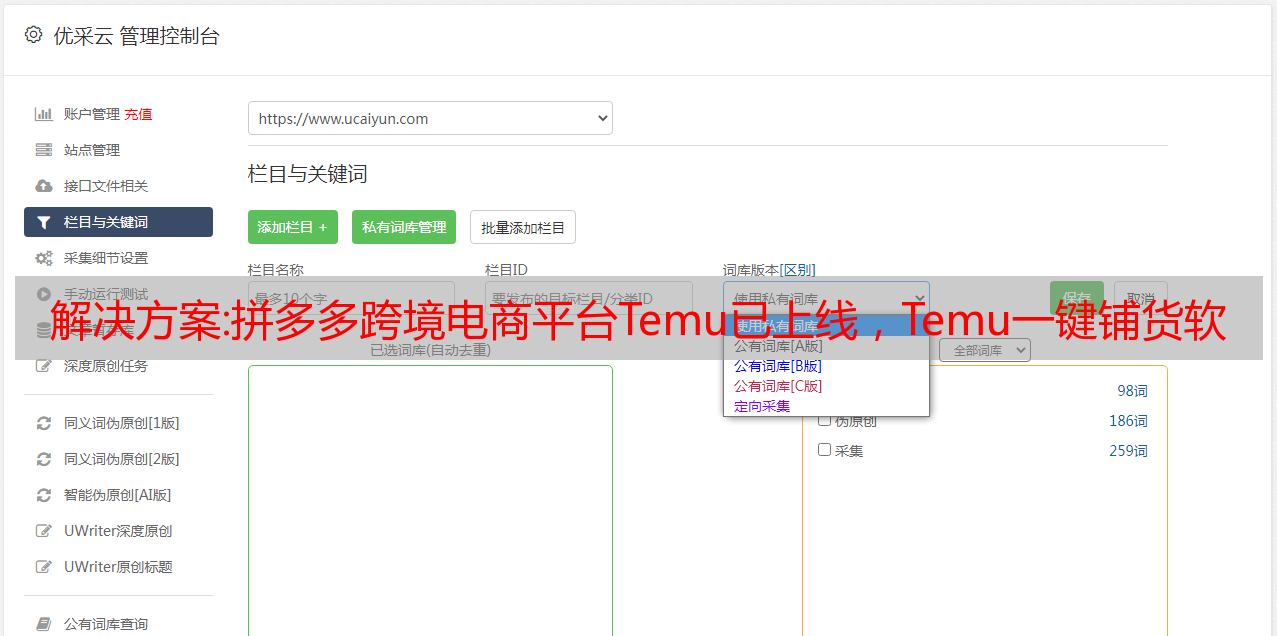
3.如果需要发布,需要选择对应的店铺
产品编辑
单品编辑
批量编辑参考采集配置,操作方法相同
产品发布
发布过程比较简单,主要讲讲重点
发布可以在立即发布和定时发布之间进行选择。定时发布将根据您设置的时间段进行。发布状态将更改为发布。您可以切换到在导航栏中查看产品。
感谢您的仔细观看——祝您是一个伟大的特木卖家,一路顺风顺水。
解决方案:浙江移动自主研发云爬虫平台成功上线 让互联网数据触手可及
一、背景及建设历史
随着一期企业级大数据平台的上线,浙江移动构建了大数据统一采集、存储和分析的基础能力,实现了O、B、企业内部的M个三域数据。模型,但外部数据,尤其是互联网数据的采集,并未包括在内。互联网上的海量信息对于丰富数据资产、支撑数据变现具有极大的互补作用。浙江移动一直在思考如何扩展大数据平台的数据采集能力,帮助租户快速高效地获取外部数据。和探索问题。
为此,在大数据平台项目二期,我们计划搭建云爬虫平台,获取外部数据,提供分词和自然语言解析能力。但是,集成商在实施过程中无法满足要求。为了不耽误平台的上线,项目组决定在开源软件的基础上自主开发和实现业务需求。完成云爬虫平台上线和试运行。
2、云爬虫平台的定位及核心需求
云爬虫平台在企业级大数据平台中的定位
核心需求
1、实现分布式互联网数据爬取,同时支持通用爬取和精准爬取;
2、实现多租户管理和资源隔离;
3、实现高可用和可视化的界面配置管理;
4、爬取的数据存储在ES、HDFS、HBASE中或者直接通过restful接口传递;
5、爬取数据存储在ES、HDFS、HBASE后,可以支持租户分词和自然语言解析;
6、履带性能要求:
a) 实现平均每天 1 亿个 URL 的 采集 量
b) 基于每天1亿个URL,每个URL按平均500KB计算,有效爬取数据存储容量大于500TB
三、云爬虫平台系统架构
1) 系统功能模块
云爬虫平台分为精细爬取和通用爬取两个功能模块,满足不同租户的数据采集需求。多租户的系统功能逻辑如下:
1. 攀爬
租户登录云爬虫管理平台,在线编辑爬虫脚本。云爬虫系统根据计划中编写的脚本规则,爬取对应页面的指定部分(如具体评论列表),并存储在大数据平台中,并建立全文索引。
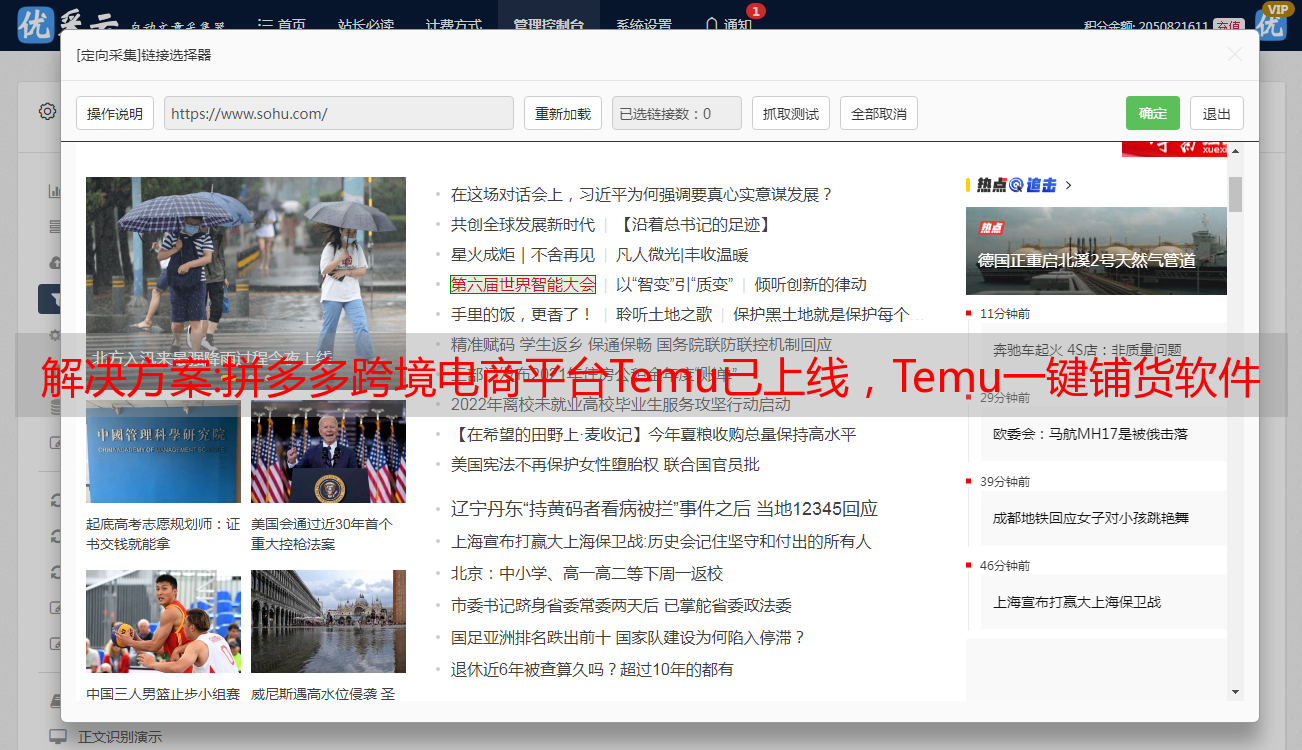
2. 攀爬
调用方调用云爬虫系统提供的通用爬取接口,云爬虫系统根据策略(代理IP等)将爬取结果实时返回给调用方,并存储在Hadoop平台中并建立全文索引。
2)系统物理架构
云爬虫平台的物理架构如下,分层,主要分为接入层、采集层和持久层,如下图所示:
1.接入层
接入层包括Web和接口。Web 主机负责负载平衡任务和显示任务列表。在网页上,租户可以根据需要创建新的爬取任务。对于成功的爬取任务,您可以通过网页查看其基本信息。REST API 负责对外提供爬虫能力接口。
2. 采集 层
采集 层收录爬虫主机和消息队列主机。爬虫主机负责接收web主机分配的任务,包括爬取网页和返回内容,对爬取的内容进行解析和结构化,以及对结构化结果进行持久化。Redis 作为消息队列,负责任务分发。
3.持久层
通常,网络爬虫抓取的数据量非常大,需要很大的存储空间来存储大量数据。因此,持久层采用中国移动苏州研发中心开发的Hadoop平台产品。
3) 应用部署架构
云爬虫平台的应用部署架构如下,主要分为Web服务域和采集服务域。
1.Web服务域
提供给租户编写和调试爬虫脚本,安装WebUI、Scheduler等组件。
2. 采集服务域
对于数据采集和结果返回,每个Spider节点都安装了Fetcher、Processor、Result_Worker、Rest API、Selenium、PhantomJS等组件。
4、云爬虫平台核心功能及自主研发范围
云爬虫平台基于开源的Python爬虫框架pyspider,根据我们的需求在本地开发。爬取的数据存储在Hadoop平台中,通过二次开发,实现多租户以及爬虫与ES、HBASE、HDFS等接口的封装。以提高开发效率。主要新功能如下:
1) 多租户管理
云爬虫和互联网数据存储分析平台都是通过二次开发基于PaaS,实现多租户和租户之间的资源隔离。
2) 丰富的数据接口
在原有框架的基础上,扩展了各种数据接口的读写能力,如关系型数据库Oracle、非关系型HBase、HDFS文件、ES、流式消息接口Kafka等,以支持不同类型的精细爬取、过关爬取等数据。业务需求。
3)平台高可用
云爬虫平台的所有爬取节点和数据存储分析节点均匀分布在多个物理节点上,单机宕机不会导致整个爬取过程中断。这种分布式架构提高了系统性的整体健壮性。
4) 抓效率
单机模式下的网络爬虫效率不高,无法满足*敏*感*词*爬取任务的需求。云爬虫平台为爬虫租户分配多个爬取节点,通过读取共享任务池共同执行爬取任务。节点可以看作是一个独立的网络爬虫,可以大大提高页面的爬取效率。
5) 高扩展性
支持静态爬取和动态渲染的主流网站数据爬取,如天猫、京东、大众点评、豆瓣等,可以根据当前爬虫任务量动态调整爬虫节点数,比传统的爬虫方法更强。同时,租户在编写脚本时具有高度的自定义性,允许租户根据不同的爬取需求自定义爬取范围。
6)可视化爬虫界面
云爬虫平台为爬虫租户提供了一个可视化的页面来编辑和调试爬虫脚本。平台支持静态和动态渲染的主流网站爬取,可以根据业务的紧迫性动态调整各个爬虫任务的优先级,并提供爬取数据结果的页面导出功能,方便用于查看样本数据。系统页面如下图所示:
五、云爬虫平台运营
1) 平台操作
云爬虫平台上线以来,集群运行总体稳定,保存了应用数据XXT。
2) 应用操作
目前承载的服务包括DPI爬虫接口和数据挖掘中的行业应用,如客流平台POI信息和大数据选址、西从天降平台商品信息、咪咕喜欢看的用户视频行为信息等。请求2000万+,日均爬取数据量4T+。
通过搭建云爬虫平台实现互联网数据获取,可以更全面地获取用户的关系、状态、位置、轨迹、使用行为和习惯特征数据,更全面准确地描述用户画像;数据的丰富性和准确性有助于改进业务发展战略,提升业务价值。返回搜狐,查看更多

