干货内容:关于搜索引擎优化网站文章内容的技巧
优采云 发布时间: 2022-11-12 07:46干货内容:关于搜索引擎优化网站文章内容的技巧
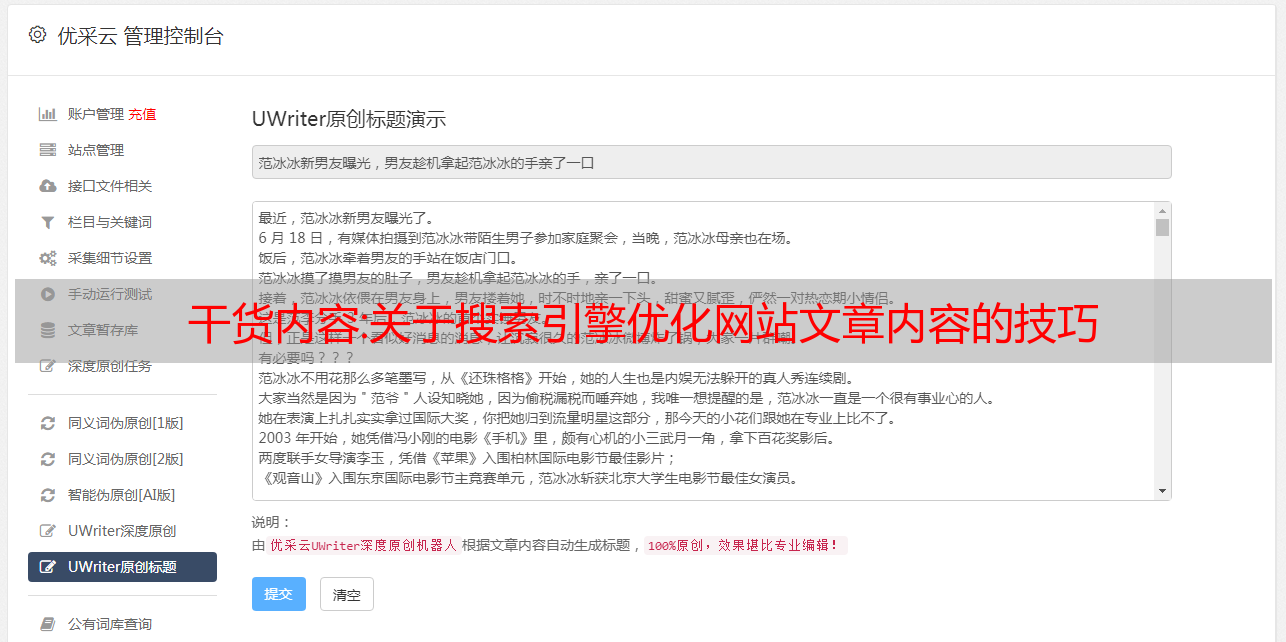
没有优质内容的SEO优化是没有用的,无论是首页内容,栏目页内容,还是内页内容,这些网站内容都是网站获取网站SEO排名和开展业务的基础知识。
首页和栏目是整个网站单页的聚合页面,每个行业都不一样,这里就不一一介绍了。下面主要介绍产品的优质内容策略和文章内容。了解SEO行业的人经常听到“内容为王,外链为王”这句话,可想而知SEO优化中“内容”部分的重要性。
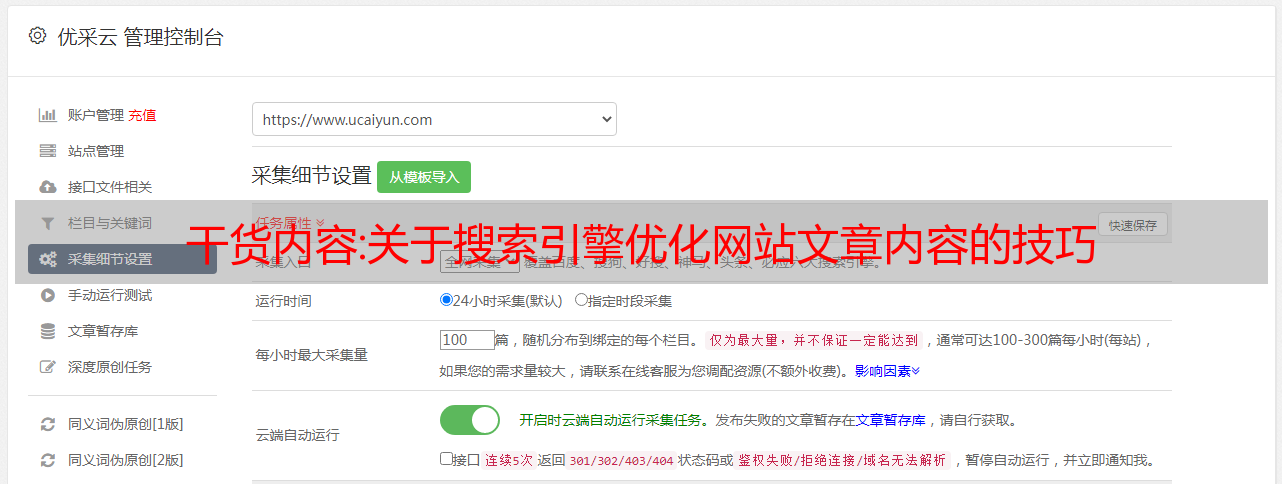
seo内容质量的优化主要来自三个方面:
1.内容量,对没有搜索结果的页面进行补充
2. 信息是否相关?
(1)布尔模型判断
(2) 主题模型判断
3.是否原创
和我之前看过和听过的几位大神的看法一样,内容量仍然是最重要的,网站内容对关键词的覆盖率代表了你的流量来源的广度。
内容相关不用多说,优秀的内容一定是相关的。他提供了两个判断标准,一个是布尔模型判断,即“是”和“否”,内容是否收录关键词?第二个是主题模型判断,这个网页的内容虽然不能完全匹配关键词的搜索关键词,但是主题是一样的,解决了我最近扩展的一个问题关键词。比如《平安车险怎么样?》这两个关键词。“平安车险好不好?” 实际上等价于 网站。搜索“平安车险如何?” 飘红。这不仅可以帮助我们扩展关键词,还可以指导我们以后如何编写文章。
最后,关于是否原创,他指的不是字面的原创,他的观点是采集的内容不一定比原来文章的排名好,重要的是比原文更有价值的是你。那么它怎么可能比原文有更高的价值呢?除了更丰富的展示形式(如图片、文字等),更重要的是满足用户的二次需求。
所谓的努力有回报。更新 文章 也是如此。做SEO优化文章不仅要定期更新,还要质量。好的 文章 是当今互联网上最缺乏的东西。想要好的SEO优化,一定不要文章采集,自己创造的排名更有机会获得好排名。
满足用户的二次需求,不仅可以帮助我们制作出优质的内容,也可以为我们提供拓展关键词的思路。有时困难不是我们投入不够,而是我们的思想没有开放。
网站而且各大搜索引擎现在也在试图弄清楚谁是内容的原作者,因为这是他们如何确定什么是高质量的内容,适合博客内容,同时也处理网站 垃圾邮件的方法,搜索引擎会重视那些可信来源的内容并给予他们更好的排名,以减少互联网上的抄袭。
我们建议SEO优化中的优质内容制作需要从提升内容度原创、专业度、图文、文字、视频、图文等方面入手,打造独特的、具有历史意义的优质内容对于 网站 。
相信看完小编的分享,大家应该知道自己的网站问题出在哪里了。其实不只是我身边的这些朋友,相信很多站长在内容方面,大多都是把别人的问题经过一系列的处理,变成自己的内容,然后扔到网站 自行管理。这样做一两次,如果你经常这样做,网站你迟早要完成它。
核心方法:.NET Core实践爬虫系统:解析网页内容
//
/
公共长视图 { get; set; }//
/
详//
/
公共字符串 Detail { get; set; }//
/
作者//
/
公共字符串作者 { get; set; }//
/
作者链接//
/
公共字符串 AuthorUrl { get; set; }
}
然后根据网页结构,查看 XPath 路径并采集内容//
/
解析//
///
/
public list ParseCnBlogs()
{
var url = “”;HtmlWeb
Web = new HtmlWeb();
1. 支持从网页或本地路径加载HTML
var htmlDoc = web.加载(网址);
var post_listnode = htmlDoc.DocumentNode.SelectSingleNode(“//div[@id='post_list']”);
Console.WriteLine(“节点名称: ” + post_listnode.名称 + “\n” + post_listnode。外显);
var postitemsNodes = post_listnode.SelectNodes(“//div[@class='post_item']”);
var 文章 = 新列表();
var digitRegex = @“[^0-9]+”;
foreach (postitemsNodes中的var item)
{
var 文章 = 新文章();
var diggnumnode = item.SelectSingleNode(“//span[@class='diggnum']”);
//身体
var post_item_bodynode = 项目。SelectSingleNode(“//div[@class='post_item_body']”);
var titlenode = post_item_bodynode。SelectSingleNode(“//a[@class='titlelnk']”);
var summarynode post_item_bodynode.SelectSingleNode(“//p[@class='post_item_summary']”);
//脚
var footnode = item。SelectSingleNode(“//div[@class='post_item_foot']”);
var authornode = footnode。子节点[1];
var 注释节点 = 项。SelectSingleNode(“//span[@class='article_comment']”);
var viewnode = item。SelectSingleNode(“//span[@class='article_view']”);
品。Diggit = int. Parse(diggnumnode.内部文本);
品。标题 = 标题节点。内部文本;
品。网址 = 标题节点。属性[“href”]。价值;
品。摘要 = 标题节点。内部网页;
品。作者 = 作者节点。内部文本;
品。AuthorUrl = authornode。属性[“href”]。价值;
品。Comment = int. Parse(Regex.Replace(commentnode.子节点[0]。InnerText, digitRegex, “”));
品。View = int. Parse(Regex.Replace(viewnode.子节点[0]。InnerText, digitRegex, “”));
文章。添加(文章);
}
退货物品;
}
查看采集结果
看到结果我很震惊,这都是重复的。可能是 Xpath 语法没有被正确理解吗?采集结果
查看 XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点。沿路径或步骤选择节点
XPath 通配符可用于选取未知的 XML 元素
我测试了几种语法,例如:
示例 1 返回 20
var titlenodes = post_item_bodynode。SelectNodes(“//a[@class='titlelnk']”);
将报告错误,因为此 A 不是在主体节点的正下方,而是子 h3 元素的子元素。
var titlenodes = post_item_bodynode。SelectNodes(“a[@class='titlelnk']”);
然后是另一个实验:
宾果游戏,这个很好,但从属 h3 被强烈指定,这有点麻烦。
var titlenodes = post_item_bodynode。SelectNodes(“h3//a[@class='titlelnk']”);
这就引出了一个小问题:如何找到孩子的孩子?可以使用通配符 * 吗?
返回 1。
var titlenodes= post_item_bodynode。SelectNodes(“*//a[@class='titlelnk']”)
如果可以正确返回 1,应该是可以的,让我们更改代码以查看效果。
然后与博客花园首页的数据对比,结果匹配。因此,我们可以得出结论:
更改后的代码如下:
public list ParseCnBlogs()
{
var url = “”;HtmlWeb
Web = new HtmlWeb();
1. 支持从网页或本地路径加载HTML
var htmlDoc = web.加载(网址);
var post_listnode = htmlDoc.DocumentNode.SelectSingleNode(“//div[@id='post_list']”);/
/Console.WriteLine(“节点名称: ” + post_listnode.名称 + “\n” + post_listnode。外显);
var postitemsNodes = post_listnode.SelectNodes(“div[@class='post_item']”);
var 文章 = 新列表();
var digitRegex = @“[^0-9]+”;
foreach (postitemsNodes中的var item)
{
var 文章 = 新文章();
var diggnumnode = item.SelectSingleNode(“*//span[@class='diggnum']”);
//身体
var post_item_bodynode = 项目。SelectSingleNode(“div[@class='post_item_body']”);
var titlenode = post_item_bodynode。SelectSingleNode(“*//a[@class='titlelnk']”);
var 摘要节点 = post_item_bodynode。SelectSingleNode(“p[@class='post_item_summary']”);
//脚
var 脚节点 = post_item_bodynode。SelectSingleNode(“div[@class='post_item_foot']”);
var authornode = footnode。子节点[1];
var 注释节点 = footnode。SelectSingleNode(“span[@class='article_comment']”);
var viewnode = footnode。SelectSingleNode(“span[@class='article_view']”);
品。Diggit = int. Parse(diggnumnode.内部文本);
品。标题 = 标题节点。内部文本;
品。网址 = 标题节点。属性[“href”]。价值;
品。摘要 = 标题节点。内部网页;
品。作者 = 作者节点。内部文本;
品。AuthorUrl = authornode。属性[“href”]。价值;
品。Comment = int. Parse(Regex.Replace(commentnode.子节点[0]。InnerText, digitRegex, “”));
品。View = int. Parse(Regex.Replace(viewnode.子节点[0]。InnerText, digitRegex, “”));
文章。添加(文章);
}
退货物品;
}
源代码
代码已上传到 GitHub:
总结
演示到此结束,下一部分继续思考如何构建自定义规则,以便用户可以在页面上自行填写规则进行识别。
你从阅读这篇文章中得到了收获吗?请转发并分享给更多人
关注“点网”并改进。网络技能

