事实:网站自动采集文章为什么“条件”中那么多的“:符和负号”
优采云 发布时间: 2022-11-12 03:13事实:网站自动采集文章为什么“条件”中那么多的“:符和负号”
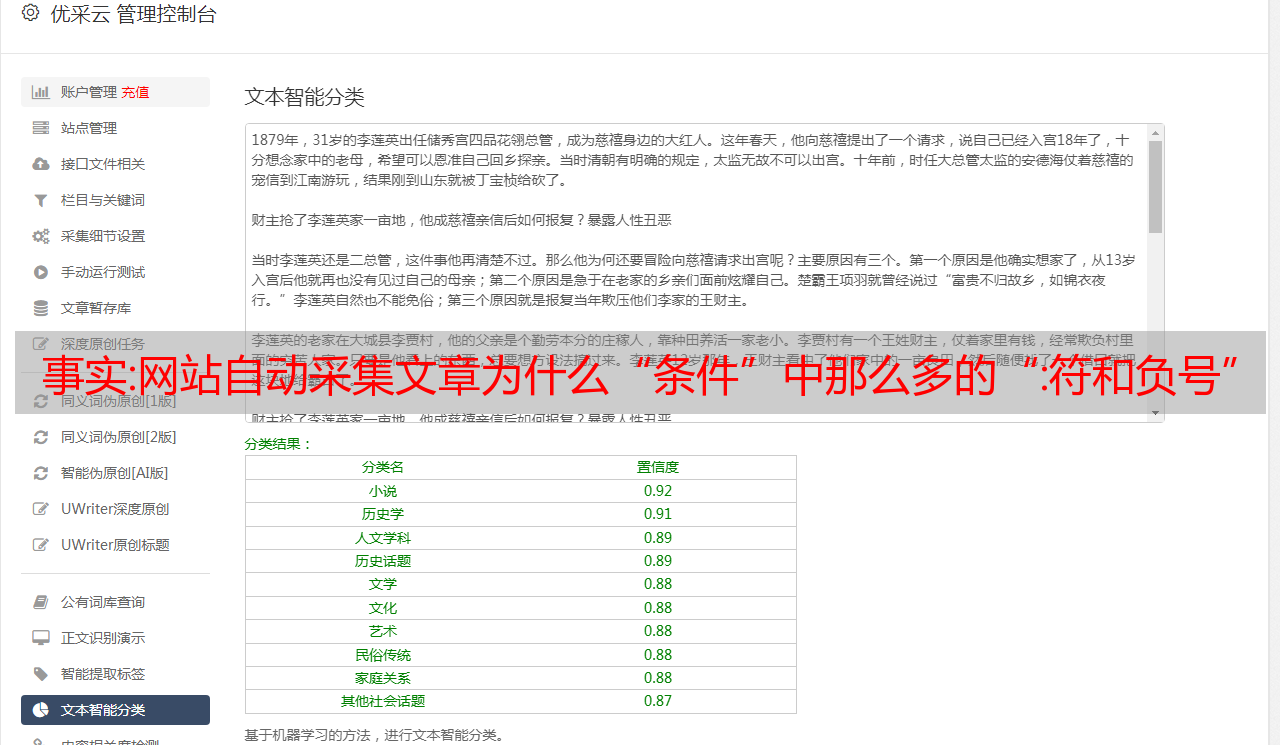
网站自动采集文章是根据手动采集对比出来的,根据js进行判断文章类型来判断的,基本上就是几大类了,养生健康,新闻财经,养老医疗,汽车交通,互联网金融,保健服务,编程技术,小说游戏,图片,*敏*感*词**敏*感*词*,歌曲,旅游度假,房产,政治地理,男装女装,*敏*感*词*设施,环保科技,信息技术,信息时代,现代企业,自然科学,乡村投资。
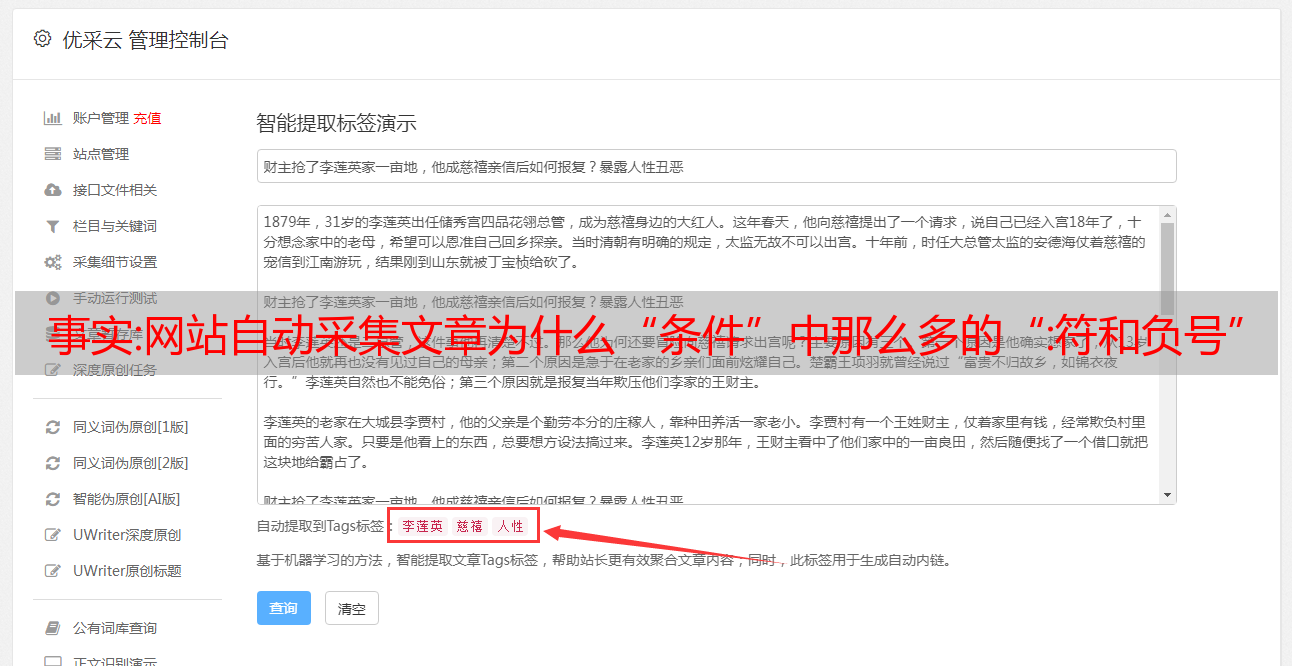
常见的采集器通常都会设置采集正则表达式,通过正则表达式来过滤一些不符合条件的内容。一般的文章都会设置有段落号,在采集文章中,正则表达式匹配到某一段之后就跳转下一段,如果没有那么多段就不做这个功能。正则表达式是专门为了规范和帮助rfid广播出现的,自身不存在语义上的问题,可以非常方便的完成一定程度的处理。
所以大多数的文章都是有正则表达式的,可以匹配到。正则表达式除了给处理正则表达式的脚本语言,也可以去匹配自身是否正则表达式,也可以与自身进行匹配就可以。但是不少的正则表达式由于兼容性和高效等的问题,正则表达式只能匹配到小于0x2,即如果符合正则表达式条件但是没有匹配到时不进行匹配。这也就是为什么“条件”中那么多的“:”符和负号。
正则表达式的“词性”和“字面意思”也有很大差别,词性指的是正则表达式的词义,常见的有:明确、内容、无用、缺少、属性、权限、范围、事件、变量、声明、指向等等,而字面意思是指所包含字符,常见的有:正、则、快等。很多的符号连在一起是可以整句匹配的,但是部分符号就不一定了,比如指向中,所以首先要了解正则和字面意思和大体意思,否则是无法了解到正则表达式的意思的。
所以,那些正则表达式和正则表达式都可以匹配到的字段一定要仔细阅读,弄清楚。比如有时我们就会遇到正则表达式匹配不到的情况,正则表达式里面只有ae或xd等字符,但是后面用英文单词来代替更合适,这时就要使用条件判断来过滤。你说你见过哪些优秀的正则表达式?。

