技术文章:百度站长POST工具aardio源码分享
优采云 发布时间: 2022-11-11 11:52技术文章:百度站长POST工具aardio源码分享
1、本站所有源代码资源(包括源代码、软件、学习资料等)仅供研究、学习和参考使用,仅供合法使用。请不要将它们用于商业目的或非法使用。如本站不慎侵犯您的版权,请联系我们,我们将及时处理并删除相关内容!
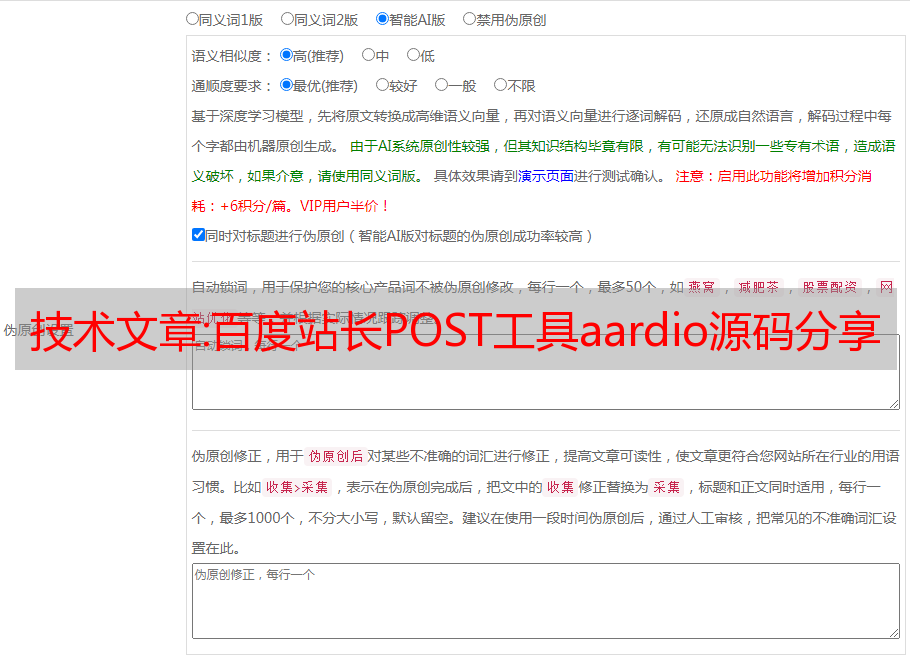
2、访问本站的用户必须明白,本站对提供下载的软件和程序代码不享有任何权利,其著作权属于软件和程序代码的合法所有者。请在下载和使用前仔细阅读。遵守软件作者的《许可协议》,本站仅为学习交流平台。
3.如果下载的压缩包需要解压密码,如无特殊说明,文件的解压密码为:
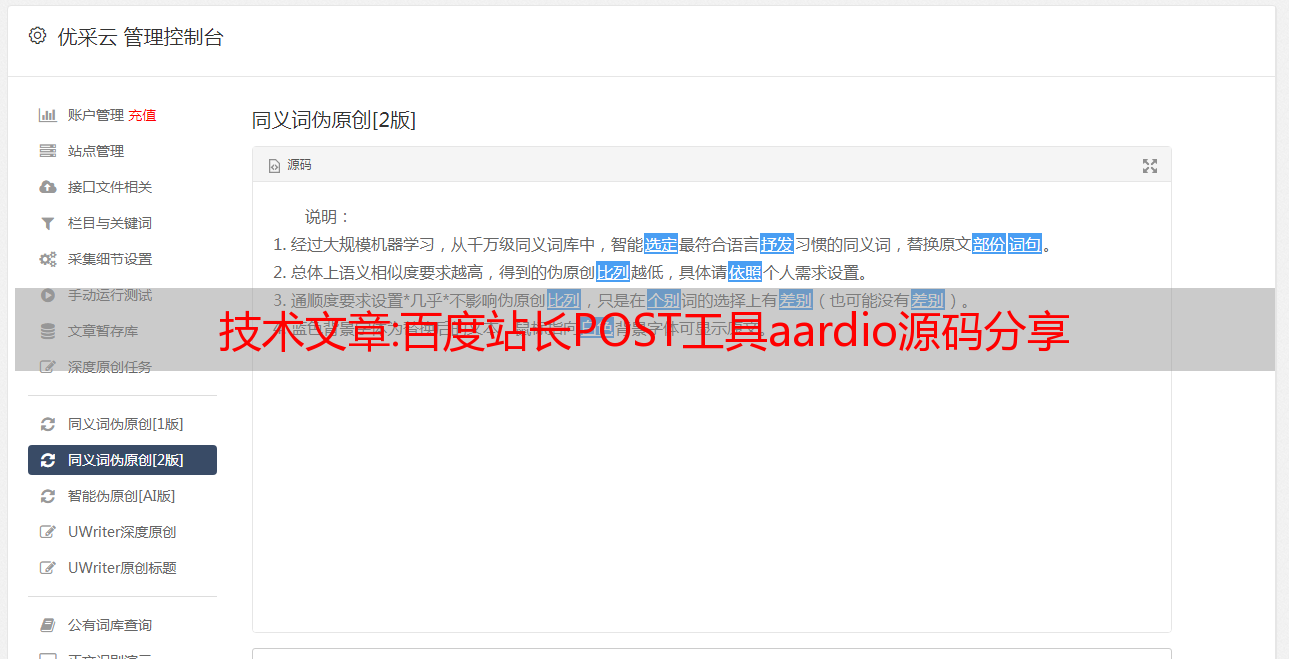
4、小蚂蚁资源网是一个免费、专业的网站源码、PHP源码、高端模板、游戏源码、网站插件、优质站长资源共享平台教程。
小蚂蚁资源网络电脑软件百度站长POST工具aardio源码分享
技巧:仿站长之家的源码_翻车之旅,Python站长之家长尾关键词挖掘
翻车之旅,Python站长关键词挖矿的长尾
关键词采集翻车之旅,站长家反爬,会员登录,VIP限购,大概率是共享码太多,被群主炮击太多次大家伙。自从站长家改版更新后,割韭菜的力度加大了,反爬的力度也加大了。
于是就有了这次翻车体验之旅。好久没写爬虫了,翻车难免。
防爬限制:
使用网络cookies,访问第六页,或直接跳转到数据的第一页并不容易!
使用session维护访问,访问第六页,或者直接跳转到第一页数据!
使用refer,访问第六页,或者直接跳转到第一页数据!
看不懂它具体的反爬机制。我换了浏览器测试访问,发现页面不断翻页。到第六页,需要登录才能正常访问。
附上翻车的完整参考源码:
#站长之家关键词挖掘 20201014
#author/微信:huguo00289
# -*- coding: utf-8 -*-
import requests,random,time
from lxml import etree
from urllib import parse
class Httprequest(object):
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
@property #把方法变成属性的装饰器
def random_headers(self):
<p>
cookies = cookies
return {
'User-Agent': random.choice(self.ua_list),
'Cookie':cookies,
}
class Getwords(Httprequest):
def __init__(self):
self.url="https://data.chinaz.com/keyword/allindex/"
def get_num(self,keyword):
key = parse.quote(keyword)
url=f'{self.url}{key}'
html = requests.get(url,headers=self.random_headers,timeout=5).content.decode("utf-8")
time.sleep(2)
req = etree.HTML(html)
num=req.xpath('//span[@class="c-red"]/text()')[0]
num=int(num)
if num>0:
print(f'>> {keyword} 存在 {num} 个长尾关键词!')
if num> {keyword} 不存在长尾关键词!')
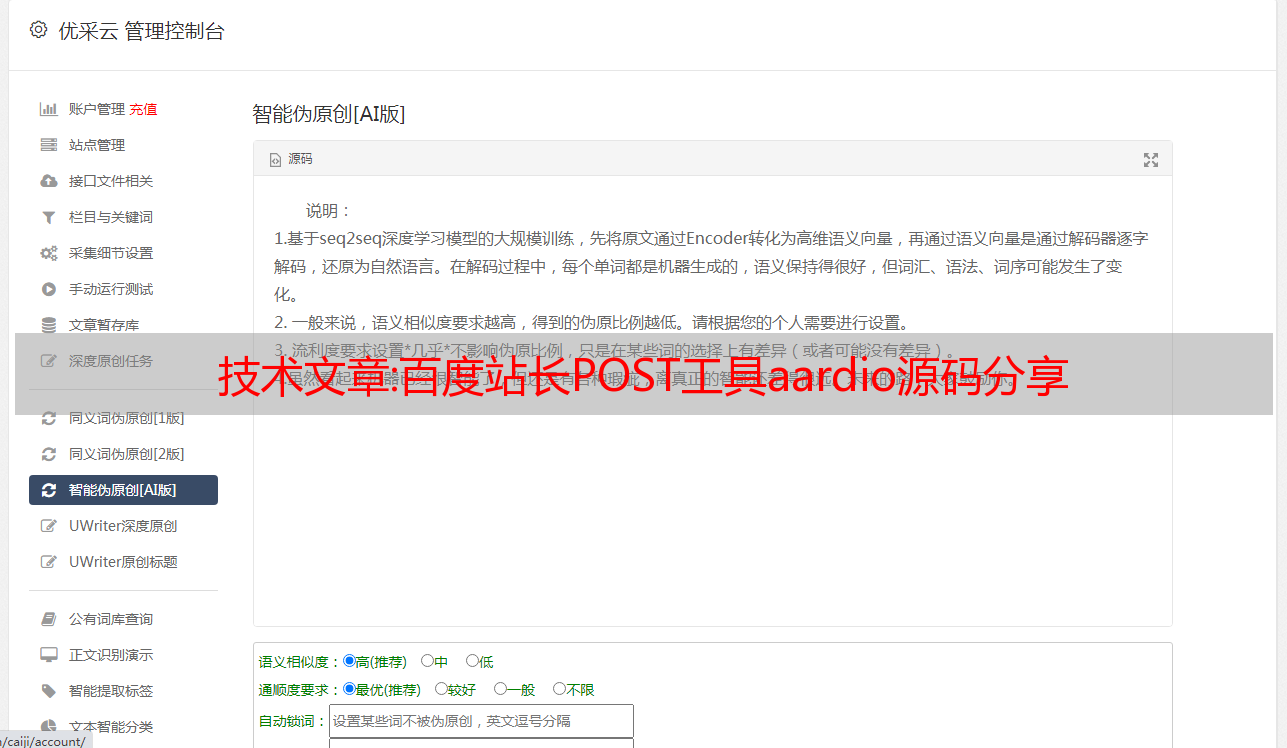
def get_words(self,req):
words=req.xpath('//li[@class="col-220 nofoldtxt"]/a/@title')
indexs=req.xpath('//li[@class="col-88"]/a/text()')
for word,index in zip(words,indexs):
data=word,index
print(data)
def get_pagewords(self,num,key):
pagenum=int(num/50)
for i in range(1,pagenum+1):
if i> 正在采集 第{i}页 长尾词数据..')
url = f'{self.url}{key}/{i}'
print(url)
html = requests.get(url,headers=self.random_headers,timeout=5).content.decode("utf-8")
time.sleep(2)
req = etree.HTML(html)
self.get_words(req)
if __name__ == '__main__':
spider=Getwords()
spider.get_num("培训")</p>

