解决方案:DEDECMS自动内链生成解决方法--DEDE关键字内链
优采云 发布时间: 2022-11-11 01:22解决方案:DEDECMS自动内链生成解决方法--DEDE关键字内链
织梦DEDEcms是目前国内最好的cms程序之一,有很多朋友用它来建网站。我们都知道内部链接对于SEO有多重要,DEDE自带文档关键词批量维护功能,可以设置关键词和链接地址,在文章内容中自动添加关键词链接,但是有一个缺点,可能会被很多朋友发现,那就是只有在文章关键词标签中添加这个关键词后,相应的链接才会添加到内容中。
一般从SEO的角度来看,目前文章关键词标签只有一两个关于这个文章关键词,如果你想做好内部链接,就得自动添加指向首页和其他相关页面关键词的链接,这样程序就默认无法实现。
前两天,SEOWHY的一个朋友来找我,请我帮他实现这个功能,这里给大家分享一下。其实很简单,就是修改这个文件:/include/arc.archives.class.php,找到下面的代码:
福里奇($kws 饰 $k)
{
$k = 修剪($k);
if($k!=“”)
{
如果($i > $maxkey)
{
破;
}$myrow = $this->
dsql->GetOne(“从dede_keywords中选择 *,其中关键字='$k' 和 rpurl” “);
if(is_array($myrow))
{
$karr[] = $k;
$GLOBALS['替换'][$k] = 0;
$kaarr[] = “”;
}
$i++;
}
}
将其替换为以下代码:

全球$dsql;
$query=“从dede_keywords位置选择 * RPURL”按排名排序“;
$dsql->SetQuery($query);
$dsql->执行();
while($row = $dsql->GetArray())
{
$key = trim($row['关键字']);
$key_url=trim($row['rpurl']);
$karr[] = $key;
$kaarr[] = “$key”;
}。
然后去批量关键词维护设置关键词和链接地址,系统设置还可以设置每关键词的更换次数,君乐建议设置一次。DEDEcms自动内部链接生成解决方案 - DEDE关键字内部链接
解决方案:网页信息自动采集方法及系统技术方案
本发明专利技术属于互联网数据处理技术领域,具体涉及一种网页信息自动采集方法及系统。其中,爬取规则根据网页信息设置要匹配的内容,网页信息至少包括页面层次、网页源代码、DOM结构和分页规则;根据网页采集请求分析目标网站,提取目标网站采集请求的数据对象;将提取的数据对象与网站模板库中的网站模板对应的爬取规则匹配,再将提取的数据对象与网站中的网站模板对应的爬取规则匹配> 模板数据库,根据匹配结果采集登陆页面数据。本发明专利技术根据目标URL和DOM结构配置抓取规则,实现目标网页信息全自动化采集,解放人力资源,提高网页工作效率采集,可以保证抓取结果的准确性。爬取过程的完整性、稳定性和爬取内容的及时性具有良好的应用前景。良好的应用前景。良好的应用前景。解放人力资源,提高网页的工作效率采集,可以保证抓取结果的准确性。爬取过程的完整性、稳定性和爬取内容的及时性具有良好的应用前景。良好的应用前景。良好的应用前景。解放人力资源,提高网页的工作效率采集,可以保证抓取结果的准确性。爬取过程的完整性、稳定性和爬取内容的及时性具有良好的应用前景。良好的应用前景。良好的应用前景。
下载所有详细的技术数据
【技术实现步骤总结】
网页信息自动采集方法及系统
该专利技术属于互联网数据处理
,尤其涉及一种网页信息自动采集方法及系统。
技术介绍
[0002] 随着互联网的飞速发展和Web信息的迅速扩展,在为人们提供丰富信息的同时,也使人们在有效利用方面面临着巨大的挑战。因此,基于Web的信息采集、发布及相关信息处理越来越成为人们关注的焦点。
[0003] 传统Web信息采集的目标是尽可能多的采集信息页面,甚至是整个网站的资源,在这个过程中需要有一定技术背景的工程师,分析目标网站,配置爬取规则,可能涉及到分页规则、内容页规则等很多页面的DOM结构,目标网站的模板可能会频繁出现升级和修改,要求工程师重新分析他的DOM结构并配置规则。这种方法费时费力,时效性差。采集收到的信息不完整,采集的进程不稳定。
技术实现思路
为此,本专利技术提供了一种网页信息自动采集方法及系统,通过设置不同行业的网站模板库,实现根据目标网址、DOM结构配置抓取规则, 进而实现根据抓取规则自动抓取目标信息的全自动信息采集。
根据该专利技术提供的设计方案,提供了一种网页信息自动化方法,包括以下内容:
[0006] 采集不同行业的网页信息,构建爬取规则设置模板库,其中,爬取规则根据待匹配的网页信息设置,网页信息至少包括页面层级、网页源代码、DOM结构和分页规则;
[0007] 根据网页采集的请求,分析目标网站,提取目标网站采集请求的数据对象;
[0008] 根据匹配结果采集目标网页数据,将提取的数据对象与网站模板库中网站模板对应的模板的抓取规则进行匹配。
作为本专利技术中网页信息的自动获取方法,进一步根据网页URL链接中的字符规则或网页源代码内容,通过分隔符或定位符在抓取规则中设置网页中要匹配的内容。
[0010] 作为本专利技术中网页信息的自动获取方法,进一步地,对于抓取规则中要匹配的内容,通过设置唯一标识来进行内容定位和规则配置。
[0011] 作为本专利技术中自动采集网页信息的方法,进一步的,规则配置包括:设置逻辑表达式、正则匹配或CSS选择器。
作为本专利技术的网页信息自动采集方法,进一步,在爬取规则中还包括:对于采集目标网页数据的纠偏内容为零的情况,其中,该纠偏内容通过分析目标网站 页面信息循环调整爬取规则中设置的待匹配内容,直到爬取到网页数据。
[0013] 作为本专利技术网页信息自动采集方法,进一步根据网页采集请求,通过目标网站 URL链接获取目标网站信息,以提取目标网站采集请求的数据对象。
[0014] 作为本专利技术网页信息自动采集方法,进一步,在通过目标网站 URL链接获取目标网站信息的同时,设置对应网页采集请求爬取时间和/或爬行频率。
进一步地,本专利技术还提供了一种网页信息自动采集系统,包括:构建模板模块、目标分析模块和数据采集模块,其中,
[0016] 构建模板模块,用于采集不同行业网页的信息,构建用于设置爬取规则的模板库,其中,爬取规则是根据待匹配的网页信息设置的,网页信息至少收录页面层级、网页源代码、DOM结构和分页规则;
[0017] 目标分析模块,用于根据网页采集的请求分析目标网站,提取目标网站采集的请求的数据对象>;
[0018] 数据抓取模块用于根据匹配结果采集目标web,将提取的数据对象与网站模板库中对应的网站模板的抓取规则进行匹配页面数据。
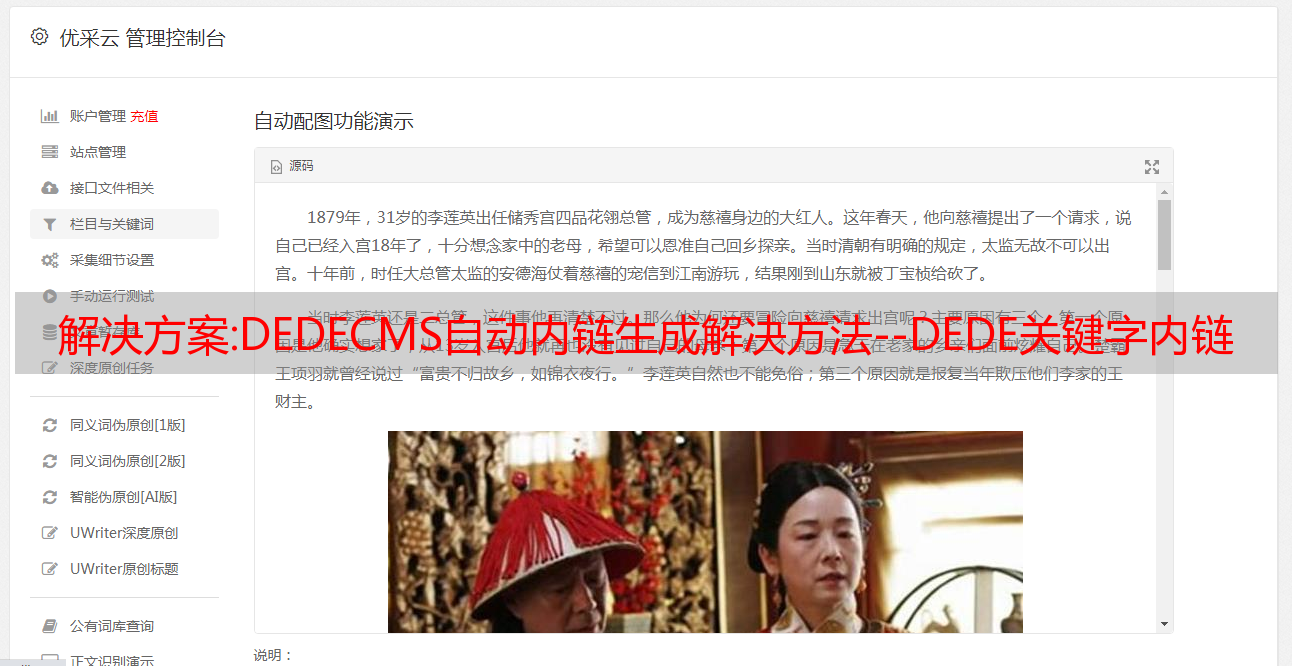
该专利技术的有益效果:
该专利技术根据目标网站、DOM结构配置爬取规则,用户在使用时,可以根据需要输入请求信息,例如通过输入目标网站、爬取时间、频率等,自动匹配模板库对应的爬取。取规则等数据,自动抓取目标网页数据内容,实现目标网页信息全自动化采集,解放人力资源,提高网页工作效率采集 >,并能保证抓拍效果。爬取过程的完整性、稳定性和爬取内容的及时性具有良好的应用前景。
图纸说明:
[0020] 图1是实施例中网页信息自动采集处理流程*敏*感*词*;
[0022] 图。图2为本实施例的网页源代码内容*敏*感*词*。
详细方法:
[0023] 为使本专利技术的目的、技术方案及优点更加清楚明白,以下结合附图及技术方案对本专利技术作进一步详细说明。
[0024] 对于第三方网页采集,尤其是部分待采集的网页布局复杂、内容动态加载、分页列表地址规则不明显、抓取页面内容等.,不存在通用性的独特特征的情况下,本专利技术的实施例,如图1所示。1、提供网页信息自动采集方法,包括:
[0025] S101,采集不同行业的网页信息,构建爬取规则设置模板库,其中,根据待匹配内容的网页信息设置爬取规则,该网页信息至少包括页面层级、网页源代码、DOM结构和分页规则;
[0026] S102,根据网页采集请求分析目标网站,提取目标网站采集请求的数据对象;
[0027] S103,根据匹配结果采集目标网页数据,将提取的数据对象与网站模板库中对应的网站模板的爬取规则进行匹配。
[0028] 本案例实施例中,可以针对不同行业建立海量模板库,通过存储目标网站的页面层次结构、网页源码、DOM结构、分页规则等模板库。而用户在使用时只需输入目标URL、爬取时间、频率等请求内容,通过自动匹配找到模板库对应的爬取规则等数据,实现自动爬取目标网页数据对象,效率高,灵活性好。
[0029] 进一步地,本案实施例中,根据网页URL链接中的字符规则或网页源代码的内容,通过分隔符或分隔符设置抓取规则中网页中待匹配的内容。定位器。进一步地,对于爬取规则中要匹配的内容,通过设置唯一标识来进行内容定位和规则配置。
[0030] 例如:列表页面链接为:
[0031]、/2、3
...
shtml,可以发现正则链接的最后一个数字是一个一个递增的,可以在起始URL的文本框中输入${1:+}.shtml。如果链接中的数字在递减,例如 ${9:
——
}。
另一个例子:详情页的链接是:
[0033]
——
10
——
19/文档
——
ifxivscc0178885.shtml
[0034]
——
10
——
19/文档
——
ifxiwazu5595286.shtml
[0035]
——
10
——
17/文档
——
ifxivsch3667038.shtml
通过上述三个详情页进行连接,可以发现正则链接从倒数第二个字符串改变,然后输入URL的匹配文本框。
【技术保护点】
【技术特点总结】
1. 一种网页信息自动采集方法,其特征在于,包括以下内容:采集不同行业的网页信息,构建用于设置抓取规则的网站模板库,其中,抓取规则是根据网页信息设置要匹配的内容,其中至少包括页面层级、网页源码、DOM结构和分页规则;根据网页采集请求分析目标网站,提取目标网站采集请求的数据对象;将提取的数据对象与网站模板库中网站模板对应的爬取规则进行匹配,根据匹配结果采集目标网页数据。2. 2.根据权利要求1所述的网页信息自动化方法,其特征在于,根据网页URL链接中的字符规则或网页源代码内容,通过分隔符或定位符将待抓取的网页设置在抓取规则中。匹配内容。3.根据权利要求1或2所述的网页信息自动采集的方法,其特征在于,所述爬取规则中要匹配的内容通过设置唯一标识进行内容定位和规则配置。4. 4.根据权利要求3所述的网页信息自动采集的方法,其特征在于,所述规则配置包括:设置逻辑表达式、正则匹配或CSS选择器。5. 5.根据权利要求1所述的网页信息自动采集方法,其特征在于,所述抓取规则还包括:对于采集目标网页数据零情况修正内容,其中,修正内容通过重新分析目标网站页面信息,循环调整爬取规则中设置的待匹配内容,直到网页数据被爬取. 6.根据权利要求1所述的网页信息自动采集方法,其特征在于,根据网页采集请求,通过目标网站URL链...
【专利技术性质】
技术研发人员:高俊涛、张洋洋、何文焕、刘德超、左宏强、姚金龙、顾景忠、
申请人(专利权)持有人:谷网安全科技*敏*感*词*,
类型:发明
国家省市:
下载所有详细的技术数据 我是该专利的所有者

