技巧:如何利用易语言实现伪原创功能原理和实战-摘要
优采云 发布时间: 2022-11-10 15:24技巧:如何利用易语言实现伪原创功能原理和实战-摘要
易语言伪原创功能原理与实战-摘要这篇技术文章给大家分享一下如何利用易语言实现伪原创功能原理和实战。易语言是百度公司出品的小型的汉化编程工具。近些年来,其中心化的处理平台在个人站长中被广泛使用。毕竟对于很多中小站长来说,如果自己的网站一个月内访问量有几千甚至上万,可能是一个非常可观的数字。而且由于易语言与百度开发平台实现了接口对接,可以为自己的站点增加大量的流量。
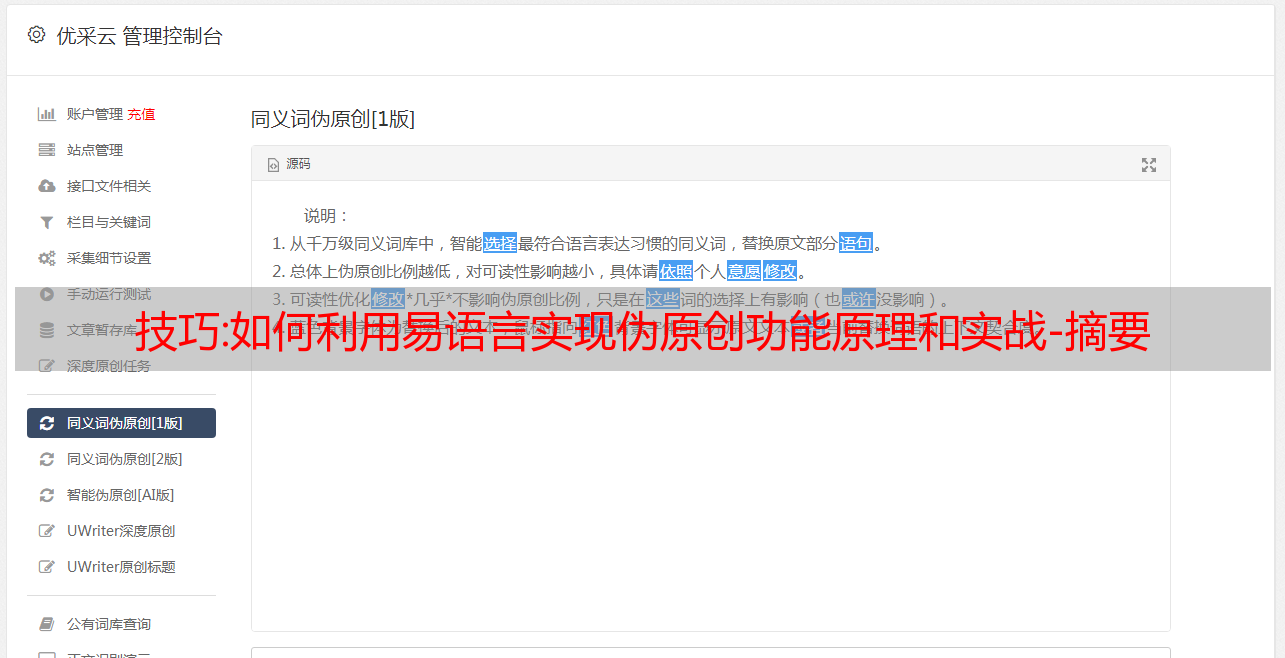
目前学习易语言没有门槛,下面将会给大家详细介绍易语言伪原创功能实现原理以及实战。python技术分享群号:72338582自定义规则在开始实现网站伪原创功能之前,我们必须要学会定义自定义规则。我们要通过python实现伪原创功能,所以必须要获取百度的模板文件。在最新的爬虫中,百度的原创文章数量是十万多篇,对于百度这样的公司来说肯定是做不到的。
由于没有能力去统计更多数量的原创文章,所以我们必须要掌握爬虫网站,去爬取类似于“蝉大师”这样的网站去抓取用户爬取的原创文章。网站爬取之后,我们进行自定义规则的设置。自定义规则是一个经典的伪原创功能实现流程。我们要获取原创文章标题和伪原创标题。并且通过自定义规则,把自己的伪原创标题写入文章。获取原创文章主体结构我们已经获取了原创文章的核心结构,那么只要把我们获取到的核心结构设置为我们伪原创中的标题。
我们需要定义两个变量,一个是原文标题,一个是伪原创标题。当然我们需要设置一些时间,这样我们伪原创中的标题才能在时间轴上凸显出来。设置伪原创标题在原文标题中加入伪原创的标题,以此把文章主体信息和核心结构包含到文章中。注意我们在伪原创中的主体可以不是原文主体,需要你自己新添加一个文本文件或者图片文件,添加到原文标题中。
伪原创规则的实现过程伪原创主体文件如果是第一次建立规则的话,规则会自动生成。过一段时间后,我们新建规则规则生成的文件会包含文章主体内容,如果没有发现之前生成的规则,可以检查我们文件是否有问题。下面再讲下批量伪原创的处理。在第一次批量伪原创时,一篇文章就可以进行伪原创处理。假设我要批量批量伪原创2万篇文章,伪原创标题是一样的。
我们会发现,获取的主体结构中有一部分文章的伪原创并不完整。也就是说,我们获取的文章主体结构中的文章部分并不完整。可以把我们获取的文章主体结构中有一部分不完整的部分删除。然后在写入文章主体信息,处理之后我们会发现文章核心结构完整了。当我们把伪原创主体信息发送到百度服务器处理并返回给用户的时候,我们已经获取了第一。

