解决方案:智能标签采集器api怎么说呢?有点不负责任
优采云 发布时间: 2022-11-10 06:06解决方案:智能标签采集器api怎么说呢?有点不负责任
智能标签采集器api是在原有的excel、word等平台基础上进行了智能变革,提高工作效率。工作效率大幅提升。标签采集器api提供海量丰富的数据获取方式、自动填充、自动转换、自动筛选等特性,将数据提供给搜索引擎,并给用户留有简单的评论,通过浏览器进行抓取,简单快捷。实现一键统计多个网站标签收集情况,一键在线转换标签。
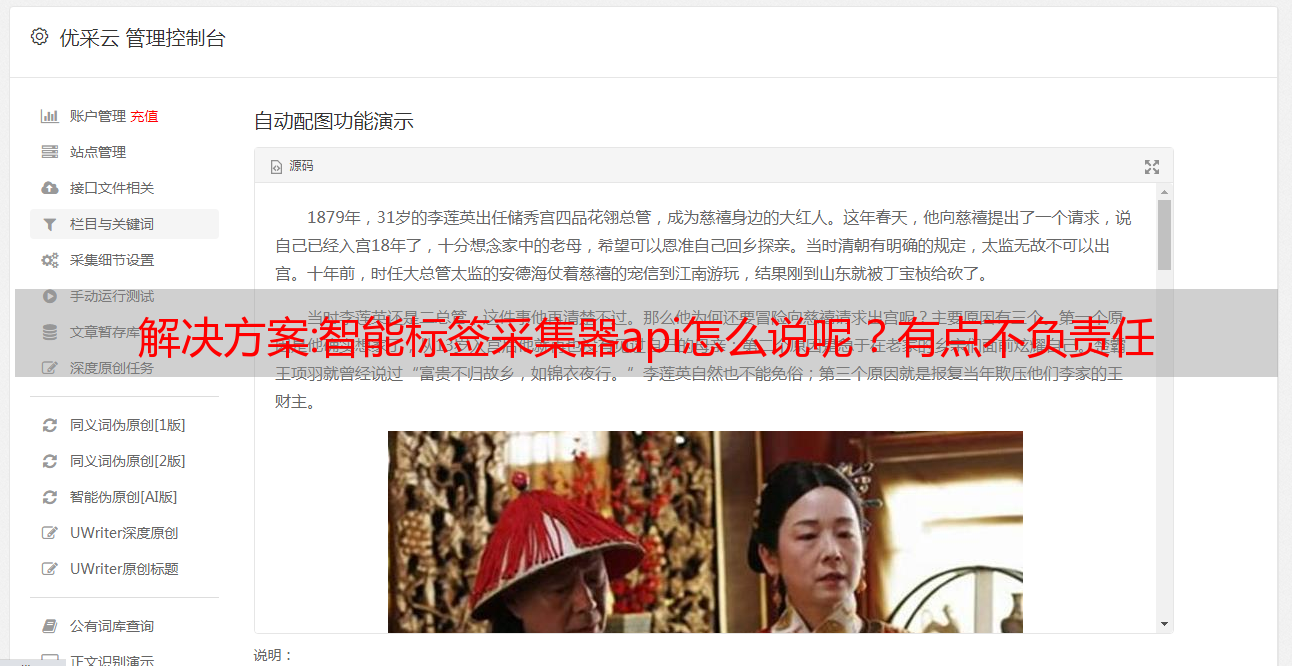
由于本项目提供给用户海量的html标签采集,所以还可以实现海量数据的自动搜索、筛选、排序等。标签采集器api是以spring服务的形式实现的,与excel文件无任何关系,该api为inputbus提供,内置高质量的json格式转换restful方法,可替代domainhandler。此外为保证有足够的速度,我们的payload中不使用json对象,而采用了api封装的htmlforms对象,保证满足国内海量数据、准实时的需求。标签采集器api采用jdk6,支持windows、linux等平台,免费提供,作者使用效果图如下。
怎么说呢,有点不负责任。首先,搜狗是为了做搜索和浏览器搜索,使用了比较好的web标签api,比如,提供css的,比如css3的;支持请求json格式。但这仅仅针对json;对于其他格式,搜狗是不支持的。比如png和jpg,因为jpg是dxid标识。另外,搜狗搜索的数据处理能力还不错,只是做了点“小改进”,所以它给人留下来,只有web搜索的影子,没有搜狗的影子。
网页编码是不是要转换成二进制格式,这方面,应该是浏览器提供了。(应该是,js/webgl的做法)要说到搜狗的市场占有率,应该是巨头中,最高的。如果,谁真的想做搜索和搜狗自己的应用,应该也不用担心搜狗api的服务器负载,毕竟搜狗自己就是一个公司。浏览器市场占有率低,是因为app的需求量太大,做这种基于web标签的应用对搜狗自己是百害而无一利的。毕竟web标签的灵活性和交互是优于标签本身的,要说难度,网页的和web相比,还是小多了。

