干货教程:优采云采集教你批量做高质量的伪原创文章的技巧
优采云 发布时间: 2022-11-09 12:18很多网站站长在进行网站升级、维护和排名优化的中后期阶段时,难免会涉及到文章 伪原创问题,如果很多文章伪原创水平差,就会对网站造成一定的危害。那么如何制作高质量的SEO原创工具呢?下面就让我们来看看吧。
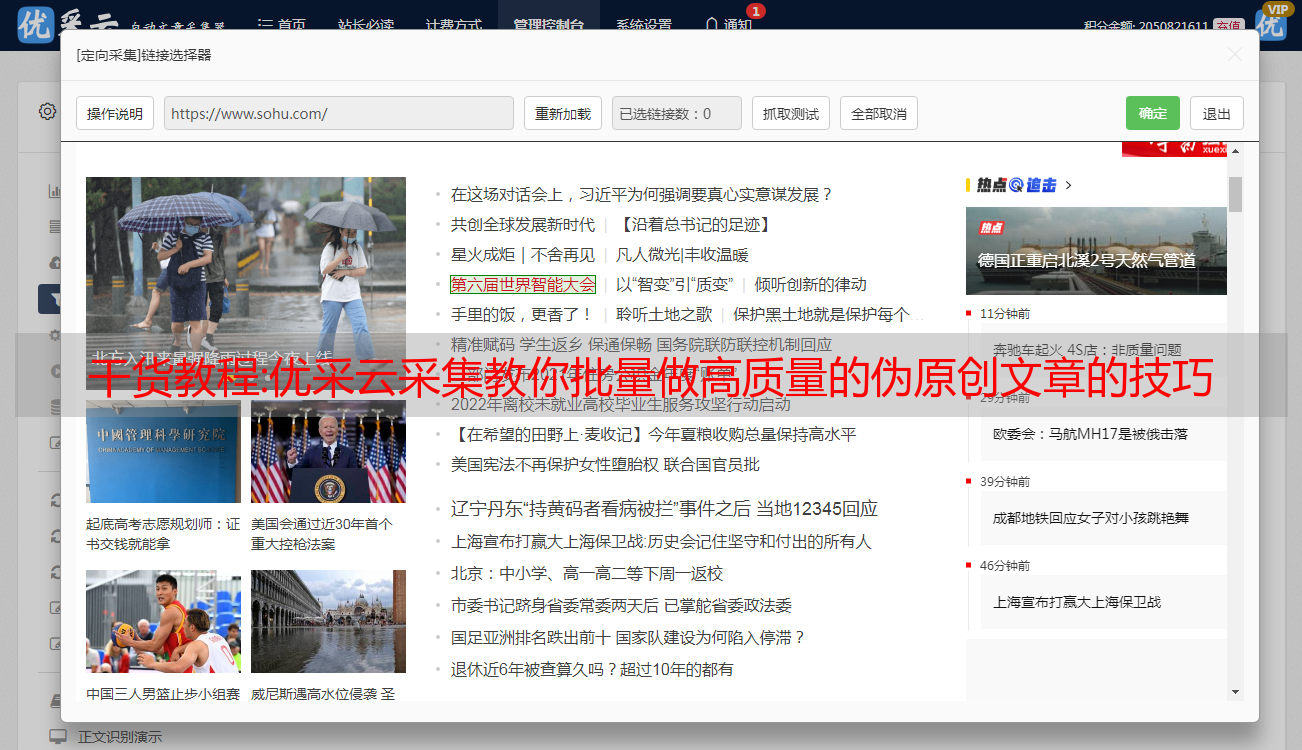
如何做高质量的伪原创文章 一、标题被改写了 在进行标题的伪原创时,没有必要因为麻烦而只升级或替换原标题作为伪原创。由于一个好的文章会被伪原创很多次,它会无意中与其他伪原创头条新闻相似。因此,你应该学会从文章内容中获得不同的见解来进行标题写作,文章标题的独特性可以提高百度搜索引擎的友好性。2.在文章段开头进行总结和归纳文章最好在段落开头进行一些总结和归纳,当然插入文章关键词,句型也不一定要太长,可以通过文章副标题获得,也可以自己总结。这样,网站访问者可以一目了然地了解文章在说什么,当百度搜索引擎抓取文章时,整个主题思路就会一目了然,这对很多人都有好处。第三,调整文章文本内容的最后一步是文章文本的伪原创。文章文章文本的伪原创应该集中在一定的方法上,这个时候可以调整每个文章意见的顺序,如果觉得文章 文章段太短,可以从其他文章找一部分来补充,文章太长也可以适度删减。怎么写好伪原创文章找到优质的原创文章源,要想写好伪原创文章,首先要找到高质量的原创文章,伪原创文章就像实物线货的仿制品,一个强大的产品,会被很多人模仿,我想大家对于腾讯的模仿工作能力是很清楚的,一款好玩的小游戏,腾讯模仿出来的手游会更有趣, 正因为如此,才会有很多人玩网易游戏。
果断不能滥用伪原创手机软件,
很多人干脆认为伪原创文章就是找个原创文章,然后应用伪原创手机软件进行伪原创,如果你也这么认为,那你就不对了,一般伪原创手机软件有两个致命缺陷,第一是一般伪原创手机软件保质保量(只是简单的关键词替换,原创性和通畅性很差), 伪原创文章很容易导致重复的内容。对原创文章进行大的改动,变化包括两个层次,一个层次是内容的左右顺序的变化,另一个层次是句子替换的变化,在不损害文章质量的情况下,以上两个改动都可以在原创文章上进行,无论是伪原创文章还是原创文章,都必须保证客户体验和原创文章并非无与伦比。会有人会有疑问,为什么要写伪原创文章而不是原创文章,是不是说伪原创文章比原创文章好,这里我想告诉大家,经常升级伪原创文章,不是伪原创文章强原创文章,而是由于内容资源匮乏,思维逻辑不足,网站原创文章不可能一直升级。URL无法保证每文章都是原创文章的,还有一个原因就是由于时间不够,尤其是网站新闻摘要,一个人必须写好原创文章,至少一个小时左右,即使你每天工作12个小时,不眠不休,只写了12篇原创文章文章,更何况很多网站站长都是*敏*感*词*, 根本没有那么多空闲时间。
下面我就介绍一下我个人应用爱伪原创写作的体会,这款手机软件是由网站站长亲自研发设计的,采用AI人工智能技术自然语言理解词义解决方案SEO算法开发设计,让文章不仅保持了比较高的原创性,流畅度的易读性也比较一般伪原创手机软件也得到了很大的提升, 而且每天都有非常优质的文章源呈现,几个月的申请从我的百度出来收录量简直是飙升,养了三网站,都破了20W,很有兴趣的读者可以看看。
干货内容:Python学习福利,满满的干货,数据采集小技巧
学习Python也已经学习Python一段时间了,在学习的过程中,我不断练习学习的各种知识,做的最多的就是爬虫,也就是简单的数据采集,有采集图片(这是最多的......),有下载的电影,也有学习相关的比如PPT模板抓取,当然, 我也写过类似收发邮件、自动登录论坛发帖、验证码相关操作等等!
这些脚本有一个共性,都与网络有关,而且总是用一些方法来获取链接,这里总结一下,分享给学习伙伴
安装相关
各种版本的 Python 其实差别不大,所以不用太担心是用 3.6 还是用 3.7
而我们经常使用的库呢,建议大家学习安装哪些库,学习哪些库
有些同学会纠结,库安装的问题不可用,这个推荐是百度搜索:python whl 首先是它,里面每个库都有各种版本,选择对应的下载回来,用 pip install 文件完整路径进行安装!
最基本的停止是获取源代码
*敏*感*词*
请求# 导入库
HTML = requests.get(url)#获取源代码
适用于静态网页
网站反“反攀爬”
大多数网站(各种中小型网站)都需要您的代码具有标头,否则,他们将直接拒绝您的访问!大网站很少,尤其是门户网站,比如新浪新闻、今日头条图谱、百度图片爬虫,基本没有反爬虫措施,相关内容可以看到我的其他文章!
大多数具有反爬虫措施的网站都可以通过添加 UA 信息来尝试 - 将 HOST、Referer(反热链接)信息添加到标头数据(字典格式)中!代码格式 requeststs.get(url,headers=headers)
UA信息是浏览器信息,
告诉对方服务器我们是什么浏览器,通常你可以采集相关信息做一个UA池,需要的时候调用,也可以随机调用,防止被网站发现,注意如果是移动端,一定要注意手机网页和PC端不一样, 比如做微博爬虫,我们更喜欢移动端,它的防爬力远低于PC端,但也提醒大家,如果一个网站防爬非常强大,可以去手机端(手机登录并复制网址),说不定会有惊喜!
用户获取信息
主机信息,
网站主机信息,这通常保持不变
引荐来源信息,这就是“防盗蛭”的关键信息,简单来说,你来到当前页面的地方,破解也很简单,只要把URL放进去就行了!
如果上面的方法还是绕不开反向爬行,那就更麻烦了,把所有信息都写在头上
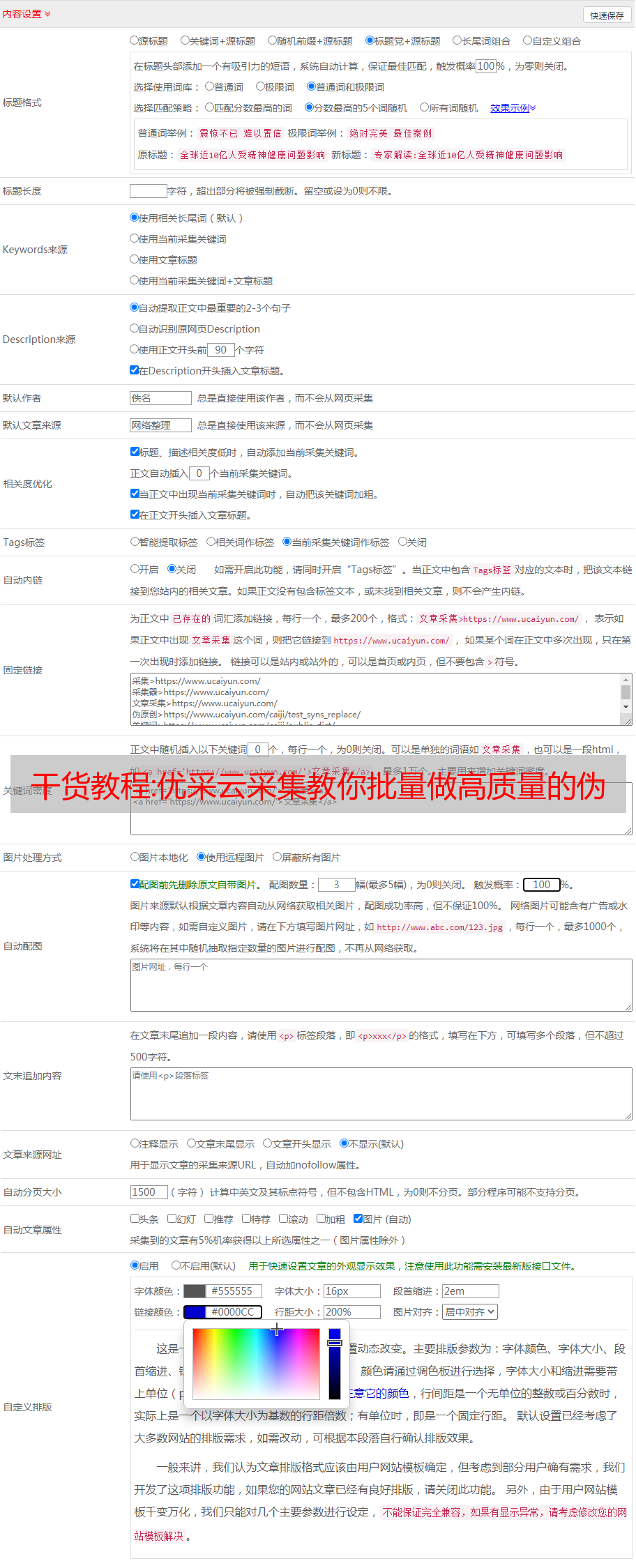
终极反“反攀爬”:快去学硒少年吧!
保存文件
其实可以简单分为两类:字符串内容保存和其他内容保存!那么一个简单的2代码就可以解决它
A+
是文末的追加写入模式,适合写字符串内容,注意排版,也可以在'A+'后添加参数 encoding='utf-8' 来指定保存文本的编码格式
WB为二进制写入模式,适用于找到对象真实下载地址后以二进制模式下载文件
待续
篇幅有限,我想读完,但有人告诉我,我写得太多了,没人看......这太尴尬了!那就先写在这里吧!
还有时间重新排列其余内容,其中可能包括:自动登录(cookie 池)和保持活动登录、IP 代理、验证码(这是一个大项目)以及 Scarpy 框架的一些注意事项。
同学们有其他的技能或者问题,也可以在评论区写,一起来讨论吧!

