总结:收藏 | 机器学习数据集汇总收集
优采云 发布时间: 2022-11-08 16:34总结:收藏 | 机器学习数据集汇总收集
转载于:机器学习算法与 Python 实战
大学公共数据集
(斯坦福)69G 大型无人机(校园)图像数据集【斯坦福】
人脸素描数据集 [中大]
自然语言推理(文本蕴涵标签)数据集 [NYU]
伯克利图像分割数据集 BSDS500 [伯克利]
宠物图像(分割)数据集 [牛津]
~vgg/数据/宠物/
发布ADE20K场景感知/解析/分割/多目标识别数据集[MIT]
多模式二元行为数据集 [GaTech]
计算机视觉/图像/视频数据集
Fashion-MNIST风格服装图像数据集【小涵】
大型(500,000)LOGO数据集
4D 扫描(60fps 移动非刚性物体 3D 扫描)数据集 [D-FAUST]
Counting MNIST,基于 MNIST 的视觉计数合成数据集
YouTube MV 视频数据集 [Keunwoo Choi]
大量计算机视觉合成数据集/工具 [unrealcv]
动物属性标签数据集 [ChristophH. Lampert/Daniel Pucher/JohannesDostal]
*敏*感*词*数据集 Manga109
架空舞蹈视频数据集
Pixiv(着色)图像数据集 [Jerry Li]
e-VDS 视频数据集
#下载
快,画!简单的笔画涂鸦数据集
简单的笔画涂鸦数据集[hardmaru]
Clothing Portrait Generation Model (&Chictopia10K [HumanParsing] Fashion Portrait Analysis Dataset) [Christoph Lassner/Gerard Pons-Moll/Peter V. Gehler]
COCO 像素级标注数据集
*敏*感*词*街道级图像(分割)数据集 [Peter Kontschieder]
*敏*感*词*日本图像描述数据集
Cityscapes 街景语义分割数据集(50 个城市,30 个类别,5k 精细标签,20k 厚标签图像和带标签的视频)
(街头)时尚服装数据集(2000 多张带注释的图像)
PyTorch [BodoKaiser] 实现的 VOC2012 数据集的逐像素目标分割
200 亿个神经元对象复杂运动和交互视频数据集 [Nikita Johnson]
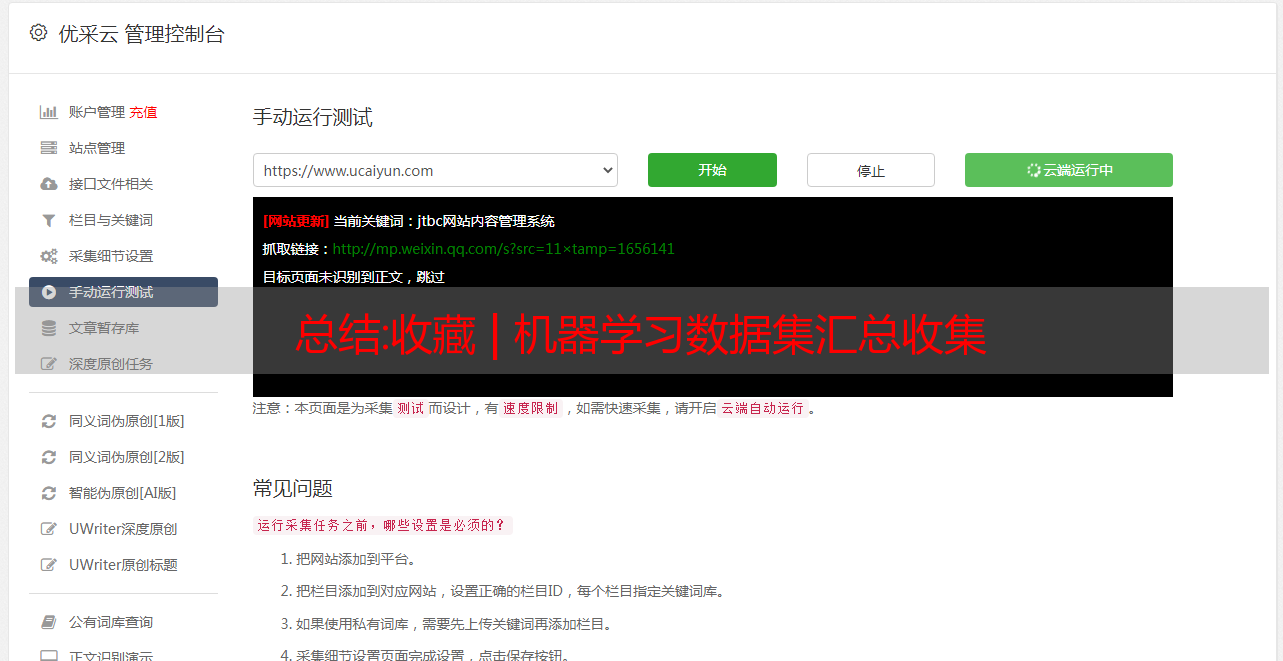
文本/评估/问答/自然语言数据集
(200,000) 个英语笑话数据集 [TaivoPungas]
机器学习保险行业问答开放数据集 [HainWang]
保险业问答 (QA) 数据集 [Minwei Feng]
斯坦福 NLP 发布新的多轮、跨领域、面向任务的对话数据集 [Mihail Eric]
实体/名词语义关系标签数据集 [David S. Batista]
NLVR:自然语言基础数据集(对象分组、数量、比较和空间关系推理)
28,000文章/100,000题*敏*感*词*(英语测试)阅读理解数据集
拼写错误的数据集
〜罗杰/corpora.html
文本缩减数据集
~dkauchak/简化/
英文单词/句子/语义框架标注数据集FrameNet
(另一个) 自然语言处理 (NLP) 数据集列表 [Nicolas Iderhoff]
用于跨语言/多样式/多粒度文本相似性检测的数据集
Quora 数据集:400,000 行潜在的重复问题
文本分类数据集
框架:Maluuba 对话数据集
跨域(亚马逊产品评论)情感数据集
~mdredze/数据集/sentiment/
语义 Web 机器学习系统评估/基准数据集采集
其他数据集
数据科学/机器学习数据集摘要
CORe50:连续对象识别数据集 [Vincenzo Lomonaco & Davide Maltoni]
(Matlab) 自动发现数据集的统计分布 [Isabel Valera]
(建筑)损害评估数据集 [海啸]
IndieWeb 社交图数据集 [IndieWeb]
DeepMind 开源环境/数据集/代码合集【DeepMind】
鸟叫数据集 [xeno-canto]
Wolfram 数据集存储库
*敏*感*词*音乐分析数据集 FMA
(300 万) Instacart 在线杂货*敏*感*词*集 [Jeremy Stanley]
用于欺诈检测的合成金融数据集 [TESTIMON]
NSynth:一个*敏*感*词*的高质量音符标记音频数据集
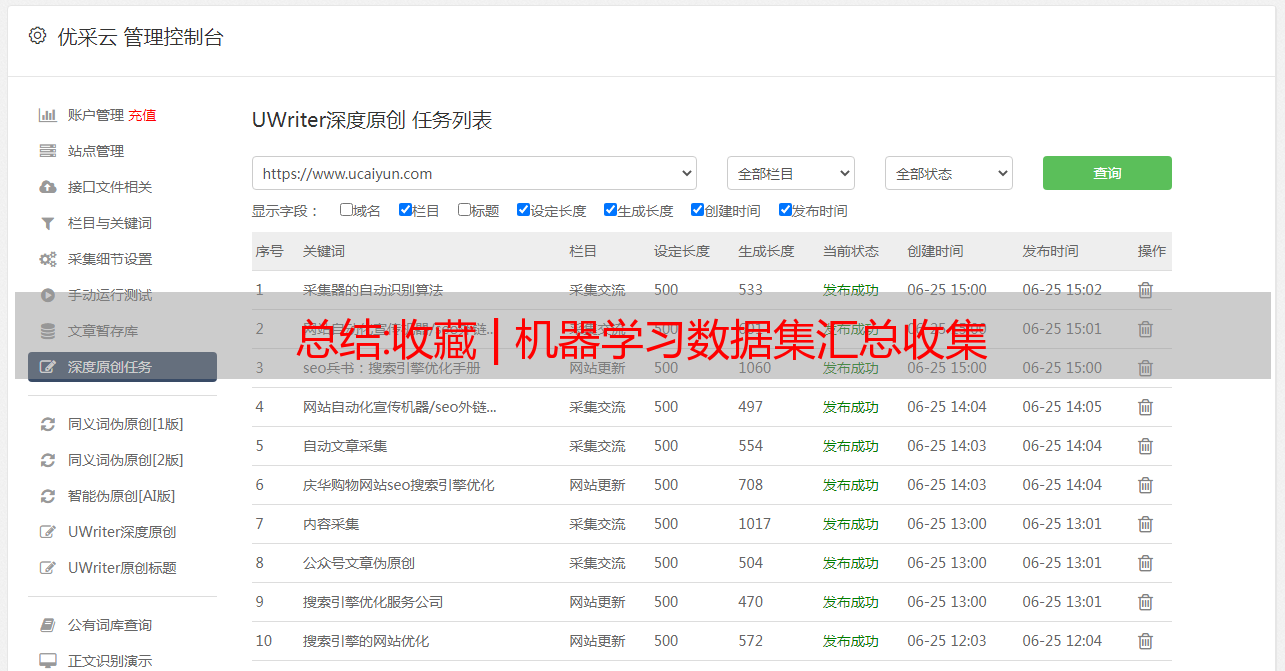
LIBSVM 格式分类/回归/多标签/字符串数据集
~cjlin/libsvmtools/datasets/binary.html
笔记本电脑使用逻辑回归拟合 100G 数据集 [DmitriySelivanov]
StackExchange 近似/重复问题数据集
2010-2017最全的KDD CUP试题及数据集
食谱数据集:超过 20,000 个带有评级、营养和类别信息的食谱 [HugoDarwood]
奥斯卡数据集【电影艺术与科学学院】
计算医学库:大型医学数据集的 (TensorFlow) 分析和机器学习建模 [AkshayBhat]
聚类数据集
官方开放气候数据集
全球恐怖袭击数据集【START联盟】
七个机器学习时间序列数据集
*敏*感*词*众包关系数据库自然语言查询语义解析数据集(80,000+查询样本)
赛马赔率数据集
新的 YELP 数据集:收录 470 万条评论和 156,000 个商家
JMIR 数据集特刊“JMIR 数据”
日本木刻版画文字识别数据集
多模式二元行为数据集
机器学习论文/数据集/工具集(日语)
机器学习公司的十大数据采集策略
NLP 数据集加载工具集
日语相似词数据集
*敏*感*词*以人为本的完形填空(多项选择阅读理解)数据集
高质量免费数据集列表
“数据之美”自然语言数据集/代码
微软数据集MS MARCO,阅读理解领域的“ImageNet”
AI2科学问答数据集(多选)
常用图像数据集
(分类、跟踪、分割、检测等)
搜狗实验室数据集:
互联网图片库来自搜狗图片搜索索引的部分数据。共有 2,836,535 张图片,类别包括人物、动物、建筑、机械、风景和运动。对于每张图片,原创图片、缩略图、图片所在的网页以及网页中的相关文本都在数据集中给出。超过200G
IMAGECLEF 致力于为图像相关领域(检索、分类、注释等)提供基准跨语言评估论坛(CLEF)。该比赛自2003年起每年举办一次。
~xirong/index.php?n=Main.Dataset
专业知识:seo专家:八个工具助您的外贸网站快速排名
八款工具助你外贸网站快速排名
做外贸网站,没有好的SEO策划,很难在激烈的竞争中脱颖而出。一个好的网站SEO需要分析网站本身,什么是外贸,以及竞争对手的网站。SEO分析对于外贸新手网站或者SEO不好的网站尤为重要。本文精选了 8 个 SEO 工具,可以帮助您发现 SEO网站 的问题。同时还可以分析竞争对手的关键词选型、链式、链式设计,然后用在自己的外贸网站中,推广SEO的隐藏东西。
1. SEMrush
SEMrush 可以称为一个综合性的 SEO 工具,SEO 初学者和专家都可以通过 SEMrush 流程获得帮助。什么是外贸,从竞争对手分析和展示到关键词研究、广告策略分析、逆向检查、关键词难度、品牌展示等。你甚至可以用它来发现新的竞争对手,观察行业变化帮助您连接和领导的领域。
SEMrush 从 Google 和 Bing 中提取大量 SEO 数据,让您能够以难以置信的细节探索 关键词。什么是外贸,以便捷的方式提供所有这些数据,并进行全面的现场审核和持续跟踪。如果您只为您的专业博客业务使用一种工具,那么设置 SEMrush 是一个不错的选择。
2. 最佳搜索引擎优化
Yoast SEO 是一个 WordPress SEO 插件。这是市场上最好的 SEO 插件之一。从主页面到文章页面,从存档页面到标签页,都提供了详细的设置。可以说,Yoast SEO对SEO设计的每一页的规划都是很小的。如可读性分析、关键词、meta关键词、关键词网页内容结构、图片分析、内外链接分析、标题和描述分析、链接地址分析等。
Yoast SEO 可能是您可以用来改善博客 SEO 的最佳整体工具。
3.Moz工具
Moz 工具可用于链接构建和分析、Web 功能、关键词sink 研究、网站 拥抱、列表查看等。什么是外贸是互联网上最大最准确的SEO关键词数据库之一。在几秒钟内,专业博主可以使用它在 网站 上找到 关键词 并确定其优先级。没有用于分析或统计过滤的复杂图表,SEO 建议简单直观。
Moz 提供了许多可供博主用来推广 SEO 的工具。这个大扇区是免费的,几乎没有限制。
4. BuzzSumo
BuzzSumo 是一个智能工具。哪些*敏*感*词*绕该内容定制您的工作。
在快速搜索中,您可以在 Facebook、Twitter、Pinterest、Reddit 上查看 关键词,包括订阅、反向链接、总份额。
5. 隔壁
强大的 SEO 集成,从 关键词 研究到链接分析,无所不能。Serpstat 提供范围广泛的 SEO 工具,几乎每个人都会在城市中找到方便的工具,包括长尾 关键词 研究、每次点击成本分析、PPC 竞争洞察、搜索量分析。
因此,您可以使用 Serpstat 做的最有用的事情是对您的站点进行全面审核。什么是外贸,包括反向链接和 Serpstat 本身,是完全自动的。
天蜘蛛网专注于SEO培训,大量学员受益。

