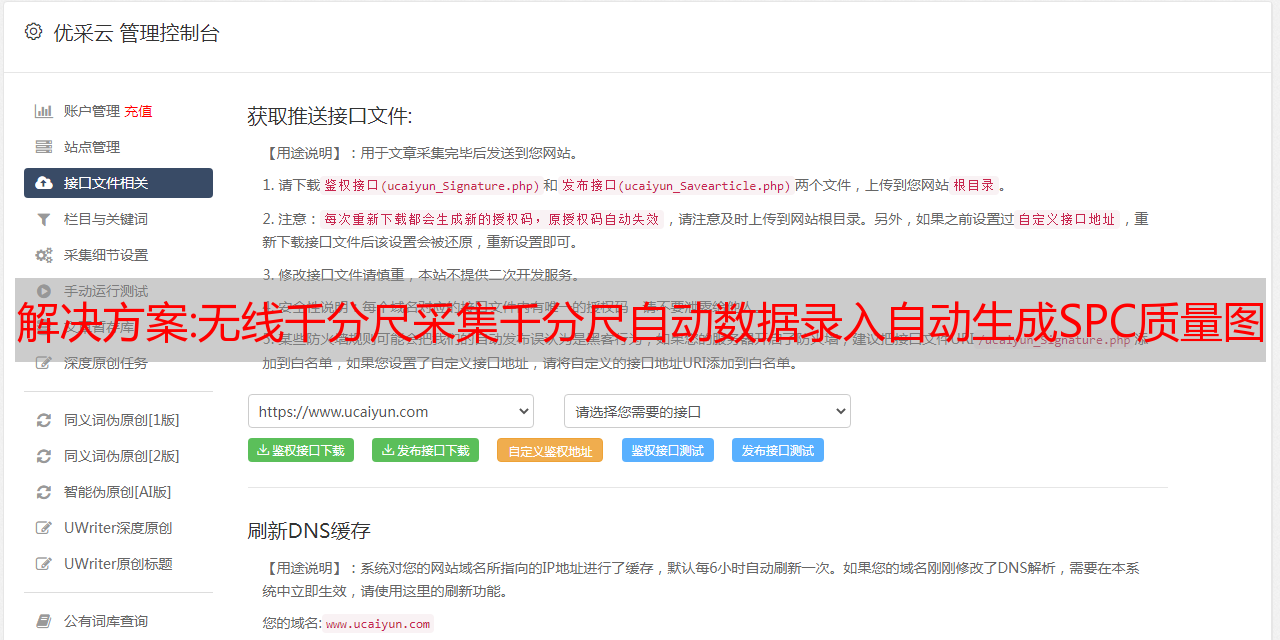
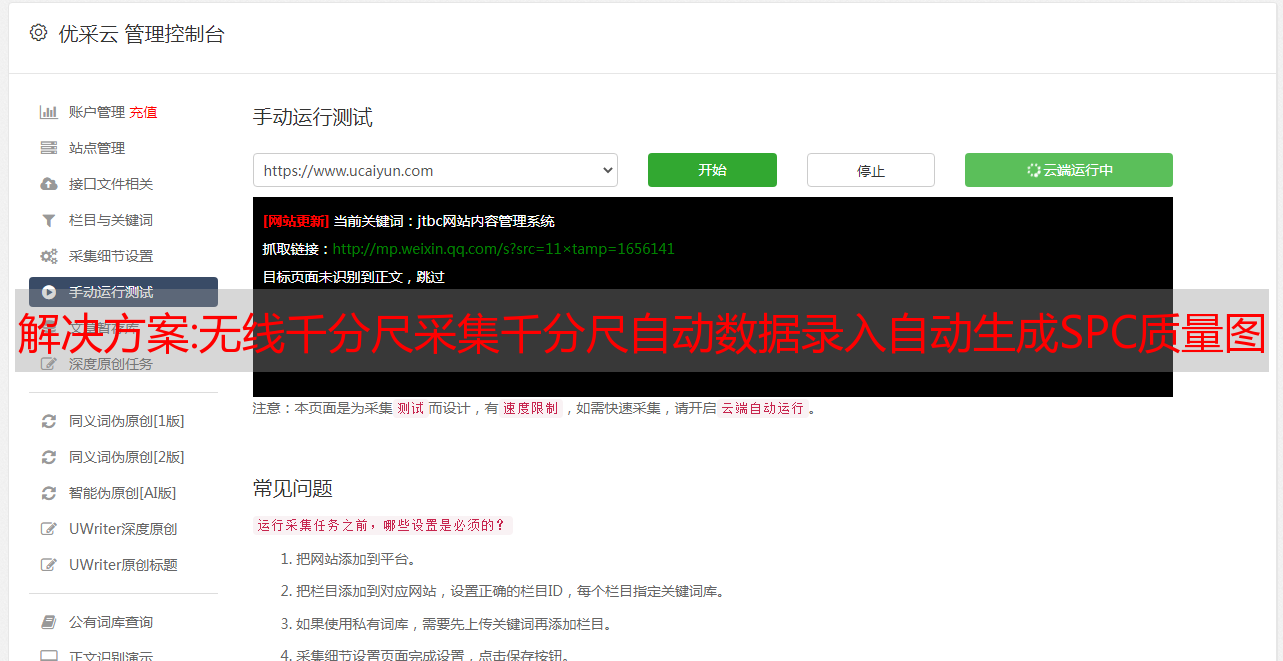
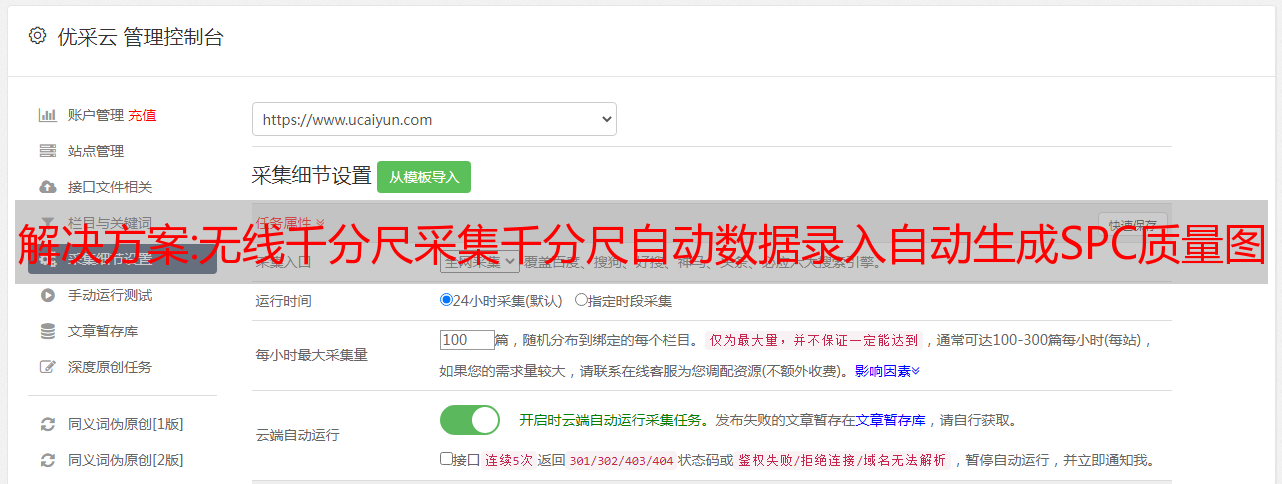
解决方案:无线千分尺采集千分尺自动数据录入自动生成SPC质量图
优采云 发布时间: 2022-11-08 14:19解决方案:无线千分尺采集千分尺自动数据录入自动生成SPC质量图
支持Mitutoyo数据采集、Mahr数据采集、Tesa数据自动录入、Minet数据采集、数量自动录入、青海、广鹿市场自动录入、Dashiko数据采集 ,三和自动输入,英显自动输入,海力自动输入,国产等品牌量具,可自动采集,自动保存数据库,自动生成SPC控制图,自动导出测量数据
# 无需人工干预或输入EXCEL表格即可顺序测量多个维度。产品名称无需手动输入,会自动采集,自动生成品控图
##无论是出于SPC、质量分析和改进的需要,还是从客户的要求出发,在实际生产过程中,测量工件尺寸往往是质量管理人员的例行公事。虽然测量尺寸的仪器有很多,但卡尺和千分尺由于使用方便,成本可控,受到了各企业的青睐。但是,采集测量数据的效率一直比较低。
## 图片:这些测量工具是不是很眼熟?
在“制造2025战略”和“工业4.0”被广泛讨论和实践的今天,很多企业还处于纸质文件手动记录数据的阶段。在最极端的情况下,即使是一个测量站也有两名操作员,一名负责操作测量仪器完成操作,另一名负责将测量结果以打印形式记录下来,或者通过键盘。这种方法有很多缺点:
• 不仅效率低下,而且非常容易出错,甚至存在测量数据被认为被篡改的情况;
• 以纸质形式记录的数据难以长期有效地保存和分析,分散在不同电子表格中的数据也给有效整合和分析带来诸多不便。
好在现在的很多测量仪器都有数显和直接输出测量数据的功能,给数据采集带来了很大的方便,可以帮助我们大大提高测量和数据的采集电子数据的效率也可以为后续的数据分析提供无限可能。
图:终于可以输出数据了!下图是最常见的通过USB数据线直接将电脑与电脑连接,将测量数据传输到电脑的方法。(其中一些是通过无线WIFI和脚踏开关。)
注意clock_diff_with_master不是每次都计算一次,而是在主从连接上或者重连的时候计算一次。
handle_slave_io/* 建立主从连接*/|->safe_connect(thd, mysql, mi)) /* connected:主从连接成功后,计算主从clock_diff_with_master */|->get_master_version_and_clock
MySQL中的源码注释和强制更正逻辑如下:
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp)- mi->clock_diff_with_master);/*显然在某些系统上 time_diff 可以
创建Vue+Springboot前后端分离项目,需要使用Websocket进行通信,但是后端报如下错误,不是每次都是经常
运行结果和错误内容 java.lang.IllegalStateException: WebSocketSession not yet initialized at org.springframework.util.Assert.state(Assert.java:76) ~[spring-core-5.3.19.jar:5.3.19]at org . springframework.web.socket.sockjs.transport.session.WebSocketServerSockJsSession.getPrincipal(WebSocketServerSockJsSession.java:87) ~[spring-websocket-5.3.19.jar:5.3.19]master的时间戳被读取,它在最后second 1,并且(很短的时间之后)读取从属的时间戳时,它位于 second2 的开头。那么master的记录值为1,slave的记录值为2。在SHOW SLAVE STATUS时间,假设slave的时间戳和rli-
后端配置
/**
* websocket 配置类
* @作者刘长兴
*
*/
@配置
@EnableWebSocketMessageBroker
公共类 WebSocketConfig 实现 WebSocketMessageBrokerConfigurer {
@Value("${jwt.tokenHead}")
私有字符串令牌头;
Redis去获取之后,需要过滤掉缺失的,然后去DB/RPC去获取,然后把这部分值写回Redis。因为用户量大,毛党会刷界面,漏掉的值可能还需要做短缓存,防止渗透到DB中。
此存储库收录以下内容:
@Cache注解可以自动缓存指定的方法(Redis或者caffeine本地缓存),可以自动清空不存在的数据,同时防止缓存穿透。可以在获取缓存时开启自动互斥锁,防止缓存击穿保护。DB(下个版本更新)安装导入
这个库已经放到了maven中央仓库,并且已经引入到自己项目的pom文件中了。请注意,mvnrepository中会直接有很多2.0.0以下的版本,请不要使用,然后……那个……那是我放在架子上做测试不小心发到debug版本的release .
有关所有版本的查询,请单击此处此处
马文
cn.somegetcache-anno2.0.0
摇篮
// /artifact/cn.someget/cache-anno实现组:'cn.someget',名称:'cache-anno',版本:'2.0.0'
@自动连线
私人用户详细信息服务用户详细信息服务;
@自动连线
私人 JwtTokenUtil jwtTokenUtil;
/**
* 添加端点,使网页可以通过websocket连接到服务器
* 即我们配置websocket的服务地址,可以指定是否可以使用socketJS
* @作者刘长兴
*
* @pa>last_master_timestamp 为 0(即它们在同一秒内),然后我们得到 0-(2-1)=-1 作为结果。这会让用户感到困惑,所以我们不会低于 0:因此最大值().last_master_timestamp == 0(一个“不可能的”时间戳 1970)是一个特殊的标记,表示“考虑我们已经赶上”。*/protocol->store((longlong)(mi->rli->last_master_timestamp ?max(0L , time_diff) : 0));
解决方案:万能的可视化发布功能多级模拟发布功能
该功能是熊猫独有的行业领先技术之一。
在 Panda V1.2 版本中,增加了一个通用的仿真发布模块。
在传统的 采集 发布过程中,需要手动编辑 POST 提交参数。甚至需要在网站后台编写一个专门的发布接口文件来接收发布提交的数据。这个方法不用多说,因为一般cms下发布接口文件的通用性,很容易导致网站的安全性出现重大漏洞。
在独有的仿浏览器解析技术的基础上,熊猫开发了一款通用的仿真发布模块,不仅直观,而且方便简单。在网站的后台发布不需要编辑专门的发布接口文件,直接使用网站已有的手动发布页面来模拟手动发布和提交。
模拟发布的“登录”功能界面
模拟发布的“发布”功能接口
手册只需要找到需要填写的发布控件的名称,并设置为使用“参数赋值方法1:从采集结果中选择”。默认情况下,采集一条新数据会立即发布到设置的网站。系统会自动过滤采集的重复数据,避免重复发布采集的重复数据。
此外,熊猫还拥有独特的“多层次模拟发布”功能。新用户注册、数据发布、重复子项数据的循环发布等可以依次模拟,一个完整的过程。多级仿真发布功能可以保证采集接收到的数据一次性完整发布到自己的网站。网站 的完整无缝移动中的一个关键要求功能,新的 网站 数据填充。

