解决方案:简单使用站群软件建立网站
优采云 发布时间: 2022-11-08 10:45解决方案:简单使用站群软件建立网站
教你怎么做站群
做站群的目的
首先,我们必须普及一些基本概念。站群是站长利用搜索引擎优化的自然规律来推广和带来搜索引擎流量的一种方式。站群系统对站群意义重大。站群的概念是对多个独立域名(包括二级域名)的网站进行管理和关联。
站群的目的是建立一个强链接资源库,带动网站关键词的排名上升,达到站群的最终目的,获得最大的流量从搜索引擎来说,通过一个好的商业模式是有利可图的。
准备做的事情站群1. 域名
对于域名,希望大家可以先去看看域名条目的解释。对于站群,域名可以分为几种形式和概念:
全新域名(指新购买的域名) 旧域名(指域名平台或他人转售的域名,已使用或解析一段时间的域名。) 三级域名(例如:前面的www是三级域名) 通用域名(指多个或无限个三级域名,具体含义可以查看条目)
一般情况下首选老域名,因为老域名是有域名年龄的。你认为一个10年的域名对于搜索引擎来说一定比一个新域名(老司机系列)更有权威性。但是老域名受不了这个价格,所以一般不是有钱人,如果家里有矿系列,乖乖买个新域名就好了。
我应该购买多少个域名?首先,它必须根据您的计划进行计算。当然,主要的因素是资金是否充足。那么第二点,如果新购买的域名不够用,可以使用二级域名或者直接打开泛域名解析补号。每个通用或二级域名都可以用作网站。
2. 站群服务器
很多人不知道为 站群 选择什么服务器。在这里我告诉你,这完全取决于你想要构建多少个 网站。网站 的个数越多,需要的配置就越高。一般香港的idc服务商都有站群的服务器配置。标准配置约254IP服务器,8核或16核,8G或16G内存,500Gssd或1Tsata硬盘。访问慢,带宽高,价格高。但香港一般是小水管。因此,业内有很多人购买老美服务器。服务器系统一般根据建站软件选择windows或linux。
3. 站群软件
建一个网站,博客或者商城,具体流程相信大家都知道,弄个服务器,启动dedecms或者wordpress等程序,分分钟建站。但是1000个中的100个呢?没关系,我们可以一一拿下。
显然,时间就是金钱。站群这种操作的东西,一个人操作的话,还是需要专业的软件来搭配的。以下操作均由软件完成。
站群软件创建网站的简单使用 1.安装
由于使用的站群软件是linux下的,所以下面的操作都是基于centos7系统的。
在服务器上以 root 权限执行以下命令:
yum install -y wget && wget -O install.sh http://download.swanyun.com/version/install.sh && sh install.sh
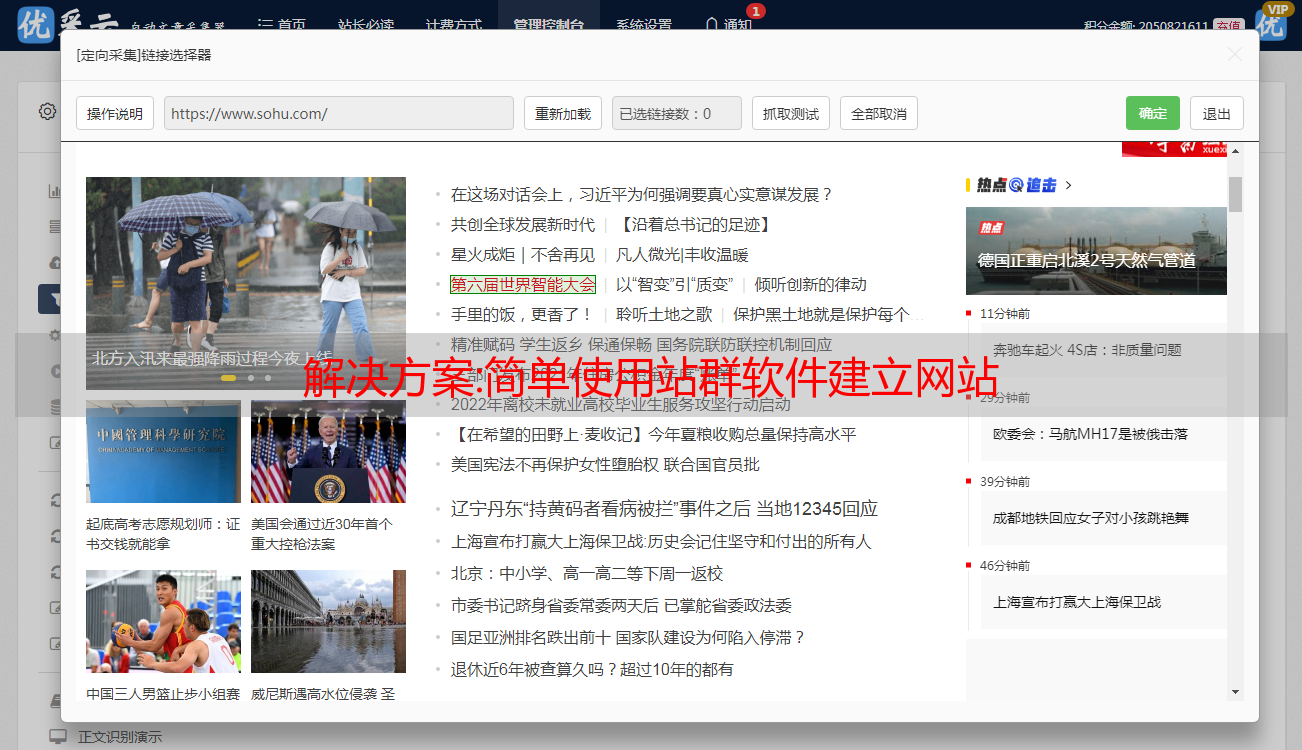
安装过程中会有地域选项,请选择您的服务器对应的地域,该选项可以优化安装下载速度,默认为CN:
Please select install source region:
(1) CN
(2) HK
然后安装程序会自动安装各种依赖,并下载编译软件。成功后会显示如下:
_____ ____ _ _ __
/ __\ \ /\ / / _` | '_ \
\__ \ V V / (_| | | | |
|___/ \_/\_/ \__,_|_| |_|
===========================================
mysql root pass: B4xzq1Vbwvw3@T4bQXWQ
database user: client
database pass: fG1V+Vz*aWXRVQ.cadRQ
Admin Login: http://ip:port
===========================================
2.建立网站
软件设置好后要做什么?域名也买了,站群软件也可以了。当然,网站已经启动。(当然,你还需要把域名解析到你的服务器上)
在这里填写我们购买的域名,然后一直点击下一步,最后开始生成。
程序会自动生成网站并初始化每个网站的文章数据。
1 分钟左右,设置好,然后查看我们构建的 网站 列表。
然后看看站群软件为我们生成的文章
3.配置
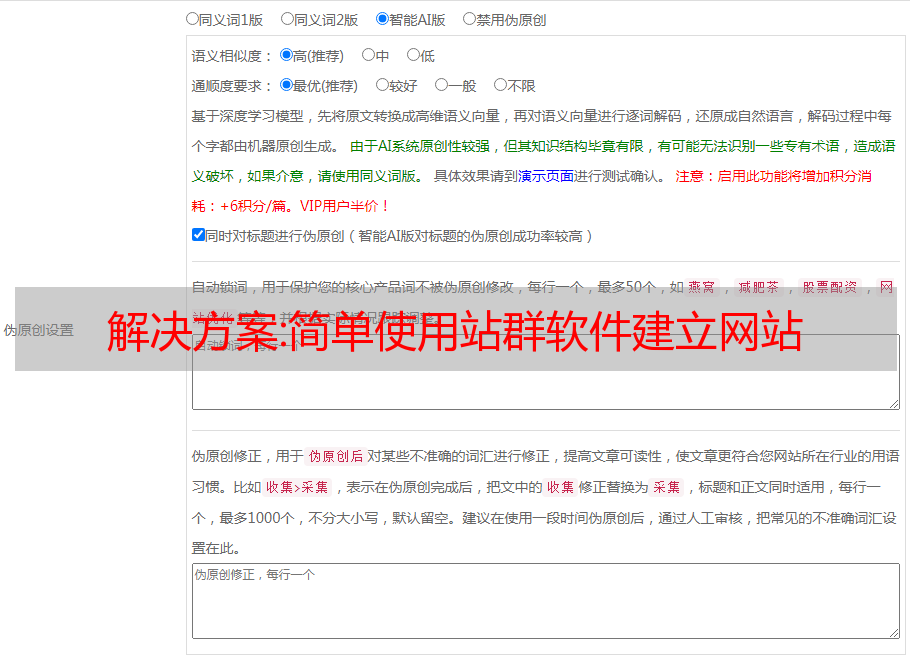
最后我们配置采集任务,让程序每天为我们的每一个网站自动执行采集和释放文章。
等等,他的采集文章是什么?别急,我们来看看网站的列配置,每一列都有具体的可定制列主关键词,采集文章是由关键词定义的到 采集。
这样一来,每一列下的文章都是精确相关的。那么 文章 是从哪里来的呢?是程序根据关键词从云端大数据中获取的相关文章。自动采集就是通过这里的关键词实现自动采集相关文章数据。
至此,即使我们的站群建立起来,整个过程也不会超过15分钟,这里只建立了100个。一千或一万是一样的操作方法!
以后会写下站群的各种详细操作方法,包括各种批处理工具的使用和搭配。
解决方案:实践应用|PyQt5制作雪球网*敏*感*词*爬虫工具
点击上方“菜鸟学Python”,选择“明星”公众号
超级无敌干货第一时间推送给你!!!
最近有朋友需要帮忙写一个爬虫脚本来爬取雪球网部分上市公司的财务数据。锅友希望可以根据自己的选择自由抢,所以干脆给锅友一个脚本。锅友还需要自己搭建python环境,还需要熟悉一些参数修改的操作,想想也麻烦。.
于是,结合我之前做的汇率计算器小工具,我决定用PyQt5为朋友做一个爬虫小工具,方便他的操作可视化。
效果演示:
1
功能说明
2
导入必要的库
import sys
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QApplication, QMainWindow,QFileDialog
import os
import requests
from fake_useragent import UserAgent
import json
import logging
import time
import pandas as pd
from openpyxl import load_workbook
3
Snowball 网页拆解
这一步的目的是获取待爬取数据的真实URL地址模式。
当我选择一只股票查看某类财务数据报告时,点击下一页,网站的地址没有变化。我基本上可以知道这是动态加载的数据。对于这类数据,我可以使用 F12 打开开发者模式。.
开发者模式下选择Network—>XHR查看真实数据获取地址URL和请求方法(General是请求URL和请求方法说明,Request Headers有请求头信息,如cookies,Query String Parameters可用Variable参数项,一般来说,数据源URL是由base URL和这里的可变参数组成)
当我们分析这个 URL 时,我们可以发现它的基本结构如下:
基于以上结构,我们将最终组合的 URL 地址拆分如下
#基础网站
base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
#组合url地址
url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
4
操作界面设计
操作界面设计使用PyQt5,这里不再详细介绍。我们将在后续对PyQt5的使用进行专门的讲解。
使用QT Designer可视化设计操作界面,参考以下:
Snowball Network Data Extraction.ui中各个组件的相关设置如下:
.ui文件可以使用pyuic5指令编译生成对应的.py文件,也可以直接在vscode中翻译(这里不再赘述,详见后续特别说明)。
本文没有单独使用操作界面定义文件,而是将所有代码集中在同一个.py文件中,所以翻译后的代码可供以后使用。
5
获取cookies和基本参数
5.1 获取 cookie
为了让小工具可以使用,我们需要自动获取 cookie 地址并将其附加到请求头中,而不是在开发人员模式下手动打开网页并填写 cookie。
自动获取cookies,这里使用的requests库的session会话对象。
requests 库的 session 对象可以跨请求维护某些参数。简单来说,比如你使用session成功登录到某个网站,那么再使用session对象请求网站。其他网页默认使用会话前使用的cookie等参数。
import requests
from fake_useragent import UserAgent
url = 'https://xueqiu.com'
session = requests.Session()
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
session.get(url, headers=headers)
#获取当前的Cookie
Cookie= dict(session.cookies)
5.2 基本参数
基本参数用于在请求财务数据时选择原创的 URL 组成参数。我们需要在可视化操作工具中选择财务数据类型,所以这里需要建立一个财务数据类型字典。
#原始网址
original_url = 'https://xueqiu.com'
#财务数据类型字典
dataType = {'全选':'all',
'主要指标':'indicator',
'利润表':'income',
'资产负债表':'balance',
'*敏*感*词*流量表':'cash_flow'}
6
访问各种证券市场的上市目录
因为我们在可视化操作工具上选择股票代码抓取相关数据并导出,导出的文件名预计以股票代码+公司名称的形式存储(SH600000上海浦东发展银行),所以我们需要获取股票代码和名称。对应的字典表。
这实际上是一个简单的网络爬虫和数据格式调整过程。实现代码如下:
1import requests
2import pandas as pd
3import json
4from fake_useragent import UserAgent
5#请求头设置
6headers = {"User-Agent": UserAgent(verify_ssl=False).random}
7#股票清单列表地址解析(通过设置参数size为9999可以只使用1个静态地址,全部股票数量不足5000)
8url = 'https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=9999&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz'
9#请求原始数据
10response = requests.get(url,headers = headers)
11#获取股票列表数据
12df = response.text
13#数据格式转化
14data = json.loads(df)
15#获取所需要的股票代码及股票名称数据
16data = data['data']['list']
17#将数据转化为dataframe格式,并进行相关调整
<p>
18data = pd.DataFrame(data)
19data = data[['symbol','name']]
20data['name'] = data['symbol']+' '+data['name']
21data.sort_values(by = ['symbol'],inplace=True)
22data = data.set_index(data['symbol'])['name']
23#将股票列表转化为字典,键为股票代码,值为股票代码和股票名称的组合
24ipoCodecn = data.to_dict()</p>
A股股票代码和公司名称字典如下:
7
获取并导出上市公司财务数据
在可视化操作界面根据财报时间间隔、财报数据类型、选择的股票行情类型、输入选择的股票代码,我们需要根据这些参数形成我们需要请求数据的URL,然后制作数据要求。
由于请求的数据是json格式,所以可以直接转换成dataframe类型再导出。导出数据时,我们需要判断数据文件是否存在,存在则追加,不存在则新建文件。
7.1 获取上市公司财务数据
通过选择的参数生成财务数据URL,然后根据是否全部选择来判断后续数据请求的操作,因此可以分为获取数据URL和请求详细数据两部分。
7.1.1 获取数据地址
数据URL根据证券市场类型、金融数据类型、股票代码、单页数和起始时间戳确定,并通过可视化操作界面设置这些参数。
股市类型控件是radioButton,可以通过ischecked()方法勾选,然后用if-else设置参数;
需要先选择金融数据类型和股票代码,因为它们支持全选(全选的情况下,需要循环获取数据URL,否则只能通过单一方式获取),所以这个部分需要再次拆分;
单页数考虑到每年有4份财报,所以这里默认是年差*4;
时间戳是根据开始时间中的结束时间计算的。由于可视化界面中输入的是整数年份,我们可以通过mktime()方法获取时间戳。
1def Get_url(self,name,ipo_code):
2 #获取开始结束时间戳(开始和结束时间手动输入)
3 inputstartTime = str(self.start_dateEdit.date().toPyDate().year)
4 inputendTime = str(self.end_dateEdit.date().toPyDate().year)
5 endTime = f'{inputendTime}-12-31 00:00:00'
6 timeArray = time.strptime(endTime, "%Y-%m-%d %H:%M:%S")
7
8 #获取指定的数据类型及股票代码
9 filename = ipo_code
10 data_type =dataType[name]
11 #计算需要采集的数据量(一年以四个算)
12 count_num = (int(inputendTime) - int(inputstartTime) +1) * 4
13 start_time = f'{int(time.mktime(timeArray))}001'
14
15 #证券市场类型
16 if (self.radioButtonCN.isChecked()):
17 ABtype = 'cn'
18 num = 3
19 elif (self.radioButtonUS.isChecked()):
20 ABtype = 'us'
21 num = 6
22 elif (self.radioButtonHK.isChecked()):
23 ABtype = 'hk'
24 num = 6
25 else:
26 ABtype = 'cn'
27 num = 3
28
29 #基础网站
30 base_url = f'https://stock.xueqiu.com/v5/stock/finance/{ABtype}'
31
32 #组合url地址
33 url = f'{base_url}/{data_type}.json?symbol={ipo_code}&type=all&is_detail=true&count={count_num}×tamp={start_time}'
34
35 return url,num
7.1.2 请求详情数据
data采集 方法需要根据用户输入来确定。代码主要根据用户输入进行判断,然后进行详细的数据请求。
1#根据用户输入决定数据采集方式
2def Get_data(self):
3 #name为财务报告数据类型(全选或单个)
4 name = self.Typelist_comboBox.currentText()
5 #股票代码(全选或单个)
6 ipo_code = self.lineEditCode.text()
7 #判断证券市场类型
8 if (self.radioButtonCN.isChecked()):
9 ipoCodex=ipoCodecn
10 elif (self.radioButtonUS.isChecked()):
11 ipoCodex=ipoCodeus
12 elif (self.radioButtonHK.isChecked()):
13 ipoCodex=ipoCodehk
14 else:
15 ipoCodex=ipoCodecn
16#根据财务报告数据类型和股票代码类型决定数据采集的方式
17 if name == '全选' and ipo_code == '全选':
18 for ipo_code in list(ipoCodex.keys()):
19 for name in list(dataType.keys())[1:]:
20 self.re_data(name,ipo_code)
21 elif name == '全选' and ipo_code != '全选':
22 for name in list(dataType.keys())[1:]:
23 self.re_data(name,ipo_code)
24 elif ipo_code == '全选' and name != '全选':
25 for ipo_code in list(ipoCodex.keys()):
26 self.re_data(name,ipo_code)
27 else:
28 self.re_data(name,ipo_code)
29
30#数据采集,需要调用数据网址(Get.url(name,ipo_code)
31def re_data(self,name,ipo_code):
32 name = name
33 #获取url和num(url为详情数据网址,num是详情数据中根据不同证券市场类型决定的需要提取的数据起始位置)
34 url,num = self.Get_url(name,ipo_code)
35 #请求头
36 headers = {"User-Agent": UserAgent(verify_ssl=False).random}
37 #请求数据
38 df = requests.get(url,headers = headers,cookies = cookies)
39
<p>
40 df = df.text
41try:
42 data = json.loads(df)
43 pd_df = pd.DataFrame(data['data']['list'])
44 to_xlsx(num,pd_df)
45 except KeyError:
46 log = '该股票此类型报告不存在,请重新选择股票代码或数据类型'
47 self.rizhi_textBrowser.append(log) </p>
7.2 财务数据处理与导出
简单的数据导出是一个比较简单的操作,就是to_excel()。但是考虑到同一个上市公司有四种类型的财务数据,我们希望它们都存储在同一个文件中,对于可能批量导出的同类型数据,我们希望添加。因此需要特殊处理,使用pd.ExcelWriter()方法进行操作。
1#数据处理并导出
2def to_xlsx(self,num,data):
3 pd_df = data
4 #获取可视化操作界面输入的导出文件保存文件夹目录
5 filepath = self.filepath_lineEdit.text()
6 #获取文件名
7 filename = ipoCode[ipo_code]
8 #组合成文件详情(地址+文件名+文件类型)
9 path = f'{filepath}\{filename}.xlsx'
10 #获取原始数据列字段
11 cols = pd_df.columns.tolist()
12 #创建空dataframe类型用于存储
13 data = pd.DataFrame()
14 #创建报告名称字段
15 data['报告名称'] = pd_df['report_name']
16 #由于不同证券市场类型下各股票财务报告详情页数据从不同的列才是需要的数据,因此需要用num作为起点
17 for i in range(num,len(cols)):
18 col = cols[i]
19 try:
20 #每列数据中是列表形式,第一个是值,第二个是同比
21 data[col] = pd_df[col].apply(lambda x:x[0])
22 # data[f'{col}_同比'] = pd_df[col].apply(lambda x:x[1])
23 except TypeError:
24 pass
25 data = data.set_index('报告名称')
26 log = f'{filename}的{name}数据已经爬取成功'
27 self.rizhi_textBrowser.append(log)
28 #由于存储的数据行索引为数据指标,所以需要对采集的数据进行转T处理
29 dataT = data.T
30 dataT.rename(index = eval(f'_{name}'),inplace=True)
31 #以下为判断数据报告文件是否存在,若存在则追加,不存在则重新创建
32 try:
33 if os.path.exists(path):
34 #读取文件全部页签
35 df_dic = pd.read_excel(path,None)
36 if name not in list(df_dic.keys()):
37 log = f'{filename}的{name}数据页签不存在,创建新页签'
38 self.rizhi_textBrowser.append(log)
39 #追加新的页签
40 with pd.ExcelWriter(path,mode='a') as writer:
41 book = load_workbook(path)
42 writer.book = book
43 dataT.to_excel(writer,sheet_name=name)
44 writer.save()
45 else:
46 log = f'{filename}的{name}数据页签已存在,合并中'
47 self.rizhi_textBrowser.append(log)
48 df = pd.read_excel(path,sheet_name = name,index_col=0)
49 d_ = list(set(list(dataT.columns)) - set(list(df.columns)))
50#使用merge()进行数据合并
51 dataT = pd.merge(df,dataT[d_],how='outer',left_index=True,right_index=True)
52 dataT.sort_index(axis=1,ascending=False,inplace=True)
53 #页签中追加数据不影响其他页签
54 with pd.ExcelWriter(path,engine='openpyxl') as writer:
55 book = load_workbook(path)
56 writer.book = book
57 idx = writer.book.sheetnames.index(name)
58 #删除同名的,然后重新创建一个同名的
59 writer.book.remove(writer.book.worksheets[idx])
60 writer.book.create_sheet(name, idx)
61 writer.sheets = {ws.title:ws for ws in writer.book.worksheets}
62
63 dataT.to_excel(writer,sheet_name=name,startcol=0)
64 writer.save()
65 else:
66 dataT.to_excel(path,sheet_name=name)
67
68 log = f'{filename}的{name}数据已经保存成功'
69 self.rizhi_textBrowser.append(log)
70
71 except FileNotFoundError:
72 log = '未设置存储目录或存储目录不存在,请重新选择文件夹'
73 self.rizhi_textBrowser.append(log)
由于源代码内容较多,不会完整展示。可以在公众号回复“雪球”获取源代码文件。
参考:
Python Qt GUI 和数据可视化编程
#会话对象
近期九大热门:
终于,Flask 迎来了真正的对手!
发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片!
盗墓热再起!我爬取了6万条《重启之极海听雷》的评论,发现了这些秘密
用Python一键生成炫酷九宫格图片,火了朋友圈
菜鸟也疯狂!8分钟用Python做一个酷炫的家庭随手记
Github获8300星!用Python开发的一个命令行的网易云音乐
一道Python面试题,硬是没憋出来,最后憋出一身汗!卧槽!Pdf转Word用Python轻松搞定!教你6招,不错的Python代码技巧!由 菜鸟学Python 原班人马打造的公众号:程序员GitHub,现已正式上线!接下来我们将会在该公众号上,为大家分享GitHub上优质的开源神器,程序员圈的趣事,坚持每天一篇原创文章的输出,感兴趣的小伙伴可以关注一下哈!点这里,领取新手福利

