解决方案:Java爬虫自动采集文章内容的处理方法-乐题库
优采云 发布时间: 2022-11-08 01:19解决方案:Java爬虫自动采集文章内容的处理方法-乐题库
自动采集文章内容,也就是说,不需要写任何代码的自动采集网页内容。
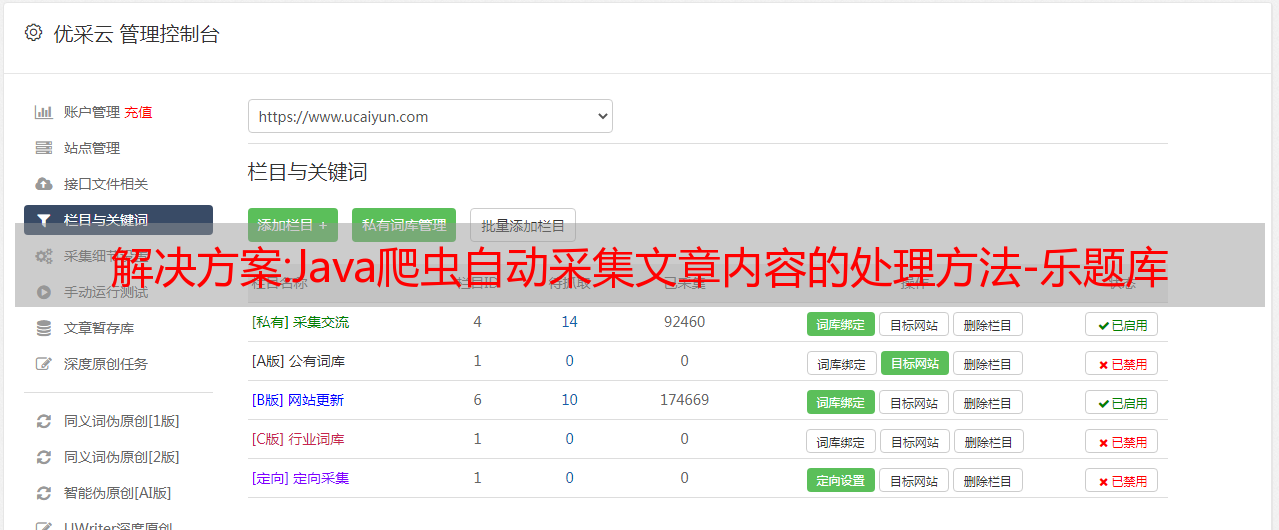
1、需要进行网页爬虫的处理:利用chrome浏览器,并选择google自带的浏览器标准网页(如果是使用baidu等搜索引擎的话,建议先使用googleanalytics\googlesiteapp\googleanalytics\nas\chromecrawler3。0/da04\siteapp2。0\crawler1。4\browser)。
2、使用requests的xpathhttp向网页内容发送post请求,如果你使用requests会自动查找url中相应的xpath,
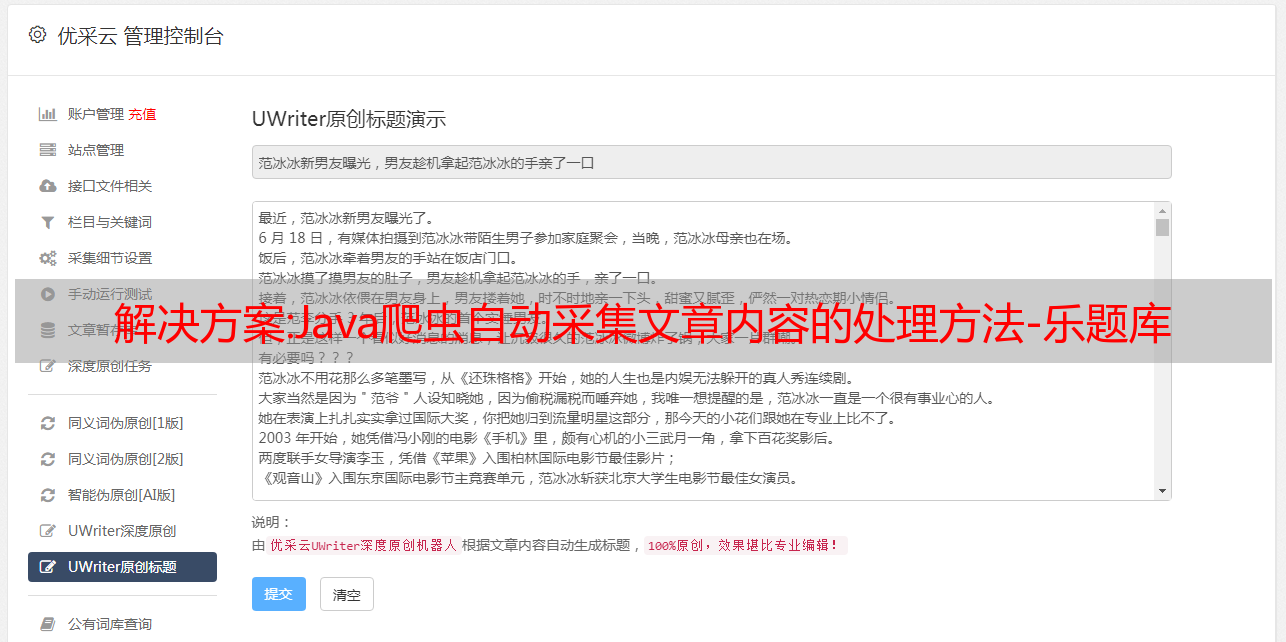
3、用lxml的解析函数进行解析网页,并将内容存入本地。如果你爬取a文件夹的话,那么就存入本地。如果爬取另一个文件夹的话,存入目标文件夹。
4、写一个程序(python
3),用函数来解析网页并存入本地,并通过f12进行查看是否正常查看网页文件结构:files包含每一篇爬取的所有文章的列表,并给出css属性,html代码等。最后你会看到一些标识(),直接把数据存入本地就可以了。---我才学习web,如果你问我python,php,java爬虫的内容,我可以给你推荐资料和脚本,不过一般都是从实战开始,另外有一些线上培训讲课比较好,不过一般要钱,根据自己选择吧,另外,没必要都去报班,看个人能力,因为如果你的能力和我差不多,那么自学也是可以的。

