整套解决方案:迅奥I-Get互联网爬虫系统产品解决方案
优采云 发布时间: 2022-11-07 18:26整套解决方案:迅奥I-Get互联网爬虫系统产品解决方案
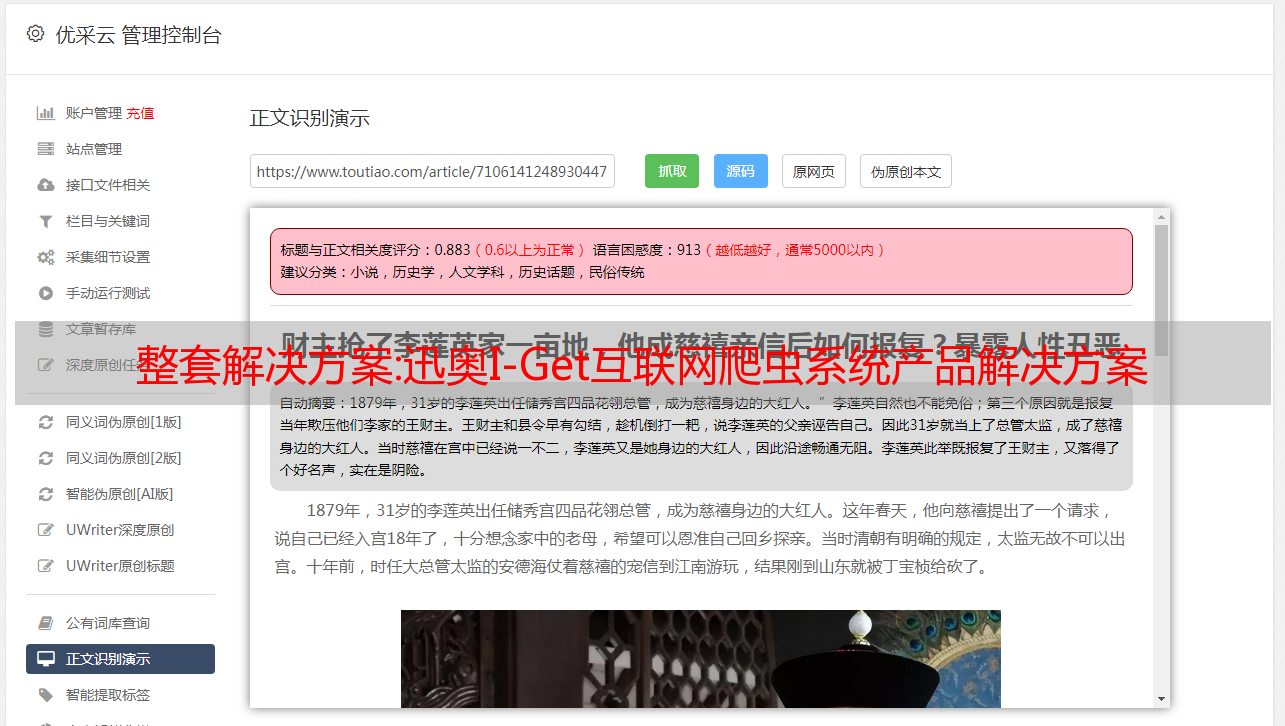
什么是网络爬虫系统
i-Get互联网爬虫系统是一个专业的网络数据采集/信息挖掘处理系统。通过灵活的配置,可以方便快捷地从网页中抓取结构化的文本、图片、文件等资源信息,经过编辑过滤后,可以选择发布到网站后台,各种应用系统,各种文件或其他数据库系统。广泛应用于数据采集挖掘、垂直搜索、信息聚合与门户、企业网络信息聚合、商业智能、论坛或博客迁移、智能信息代理、个人信息检索等领域。采集挖掘需求的群体。功能上,支持采集需要登录才能查看的内容,支持检测文件真实地址和下载远程文件,支持代理采集,支持采集数据直接入库等诸*敏*感*词*。同时它还拥有无限URL采集,无限多页面和分页规则采集,多语言,多编码支持,支持下载源权重设置,广告排除,垃圾邮件排除、网址排序、文字去除等功能。它可以完成您在浏览器中可以看到的各种信息的提取。强大的接口支持,让您通过二次开发实现您的数据抽取需求、定时任务和分布式采集终端,同时保证您的数据时效性和数据量需求。支持 采集 数据直接进入数据库和许多其他功能。同时它还拥有无限URL采集,无限多页面和分页规则采集,多语言,多编码支持,支持下载源权重设置,广告排除,垃圾邮件排除、网址排序、文字去除等功能。它可以完成您在浏览器中可以看到的各种信息的提取。强大的接口支持,让您通过二次开发实现您的数据抽取需求、定时任务和分布式采集终端,同时保证您的数据时效性和数据量需求。支持 采集 数据直接进入数据库和许多其他功能。同时它还拥有无限URL采集,无限多页面和分页规则采集,多语言,多编码支持,支持下载源权重设置,广告排除,垃圾邮件排除、网址排序、文字去除等功能。它可以完成您在浏览器中可以看到的各种信息的提取。强大的接口支持,让您通过二次开发实现您的数据抽取需求、定时任务和分布式采集终端,同时保证您的数据时效性和数据量需求。无限多页面和分页规则采集,多语言、多编码支持,支持下载源权重设置、广告排除、垃圾邮件排除、URL排序、文本删除等功能。它可以完成您在浏览器中可以看到的各种信息的提取。强大的接口支持,让您通过二次开发实现您的数据抽取需求、定时任务和分布式采集终端,同时保证您的数据时效性和数据量需求。无限多页面和分页规则采集,多语言、多编码支持,支持下载源权重设置、广告排除、垃圾邮件排除、URL排序、文本删除等功能。它可以完成您在浏览器中可以看到的各种信息的提取。强大的接口支持,让您通过二次开发实现您的数据抽取需求、定时任务和分布式采集终端,同时保证您的数据时效性和数据量需求。
功能说明
1.支持90%以上的互联网信息采集
媒体覆盖范围包括:新闻、论坛、新闻评论、论坛回复、博客、微博、搜索引擎、WAP网站、电子报刊、杂志以及国内大部分主流媒体和国外相关媒体。
2.动态网页信息采集
支持对主流动态脚本技术PERL、ASP、PHP、JSP站点的动态页面内容的爬取,系统具有避免“蜘蛛陷阱”脚本错误的机制。
3. 新站点发现
及时快速发现新数据源,支持新站点下载策略,快速实现新站点网页覆盖。
4.镜像网页识别
在网络中,镜像网页现象比较严重。75%的网页以镜像和转载的形式存在。识别镜像网站,避免镜像网站的页面下载,可以有效提高下载效率,节省下载带宽。
5. 网站权重设置
采集系统是带宽敏感型应用,带宽是系统性能的主要瓶颈。系统可以灵活配置网站、网页下载权重和优先级,为关键站点和重要网页提供更快的更新频率和更充足的带宽。
6.网站模板自动识别
无需为每个网站制作复杂的模板并匹配下载格式。系统自带云模板库和网站分析工具,自动识别网站内容下载,准确率80%以上。
7.增量下载模式
由于带宽限制,我们选择增量学习的方式下载。借助现有的关键词库和系统下载日志,我们可以有效自动增量下载,尽可能减少下载量,同时保证覆盖。
8.统一的多编码方式
中文信息主要有GB、BIG5、UTF8(UNICODE)、GBK等格式;对于其他语言,还有更多的编码格式如:UNICODE、UUENCODE、BASE64、Quoted Printable等,可以实现以上对多种编码格式的支持。
9.先进的下载重复数据删除技术
蜘蛛在“爬行”互联网时会发现大量重复信息。i-Get会对信息源进行URL重排、标题重排、文本重排三重重排,可以避免下载大量重复信息,既节省了系统资源,又节省了大量的网络带宽,从而大大提高了信息采集服务质量。
10.下载错误警告
i-Get具有服务器内存监控、带宽监控、下载日志统计、下载源错误邮件警告等机制,保证下载信息的连续性。
11. 云模板库
系统提供上万个模板库供下载系统调用,80%以上的网站不需要自定义模板。
服务方式
系统以两种方式提供服务:独立部署和数据推送。
独立部署:
a) 应提供足够的带宽,一台或多台下载机,下载源可自行配置,不受功能限制。
数据推送:
b) 根据网站、关键词、媒体类型、渠道等多种分类方式,可将迅澳数据中心的数据定时定时推送到客户端,推送格式可定制。
服务优势
a) 可以享受全网数据,数据更全面。
b) 服务更稳定,性能更好。
c) 独立部署系统,可随时添加或删除监控源。
d) 提供7×24小时人工服务
谷歌 网站URL Data AI采集 插件,允许我们自动将 采集 数据从 网站 到我们的本地或数据库。网站Web Data采集(也称为 ScreenScraping、WebDataExtraction、WebHarvesting 等)是一种用于从 网站 中提取大量数据的技术,从而将数据提取并保存到我们的网站/数据库。
使用网站URL Data采集插件,我们可以一次创建多个采集任务,可视化的界面让我们的操作变得简单,不需要我们专业的编程知识也可以完成采集
1. URL可视化采集
Google 的 网站URL采集 软件使用简单,不需要深奥的编程规则。可视化界面使操作变得简单。一个可视化的界面让我们的操作极其简单,我们只需要按图中的顺序点击,就可以帮助我们执行单个采集或者预设的配置数据。
视觉选择器的工作方式与数据选择器非常相似。不同之处在于我们只需要选择一个链接到我们希望 采集 转到我们的 网站 的 URL。然后,视觉选择器会将所有相似的链接导入到一个列表中,供我们与多个 采集 任务一起使用。
2. 关键词火柴盘采集
输入我们的关键词,匹配全网热门平台的内容,为我们提供采集相关热门文章和数据。我们可以通过简单地选择或取消选择要导入的数据块来选择尽可能多的数据。为我们完成数据的处理。
3.自动采集
Auto采集 将自动从我们选择的源 URL 中提取所有 url,并将任何新帖子添加到我们的站点。例如,假设我们在 Data采集 任务中有一个博客,我们希望添加到其中的每个 文章 都自动导入到我们的 网站 中。我们可以将 auto采集 设置为我们的 data采集 博客主页,该主页通常会显示一个指向我们最近发布的每个 文章 帖子的链接。
1. 移除不需要的数据块的能力,例如:社交图标、标题、横幅、分隔边等。
2. 自动化:网站URL 数据采集该插件将根据预选或我们自己的预选,递归地自动化每个 URL 中的标题、标签、类别和图像。
3. 从源 URL 中选择一个标题或添加我们自己的标题。
4.我们可以选择源URL的多个区域,包括图片发布数据。
5. 从源 URL 中选择一个类别或创建一个新类别。
6. 标签:从源 URL 中选择标签或添加我们自己的标签。
7. 特*敏*感*词*片:从源 URL 中选择图片或添加我们自己的图片。
8.前缀/后缀:为所有标题添加我们自己的前缀和后缀。
Google 网站URL Data采集插件是我们数据采集和分析的好帮手。在大数据时代,我们无法避免使用数据,无论是通过数据分析自己的网站信息,还是用数据来统计我们的日常工作流程,通过数据整理分析,做出理性判断在我们的工作中。,完成工作总结和后续目标的指定。

