解决方案:优采云v7.6采集在宝塔开启https后获取不到栏目的解决方法
优采云 发布时间: 2022-11-07 12:55解决方案:优采云v7.6采集在宝塔开启https后获取不到栏目的解决方法
if ($server_port !~ 443){
rewrite ^(/.*)$ https://$host
permanent;}
将上面的代码替换为以下代码;
set $flag 0;
<p>
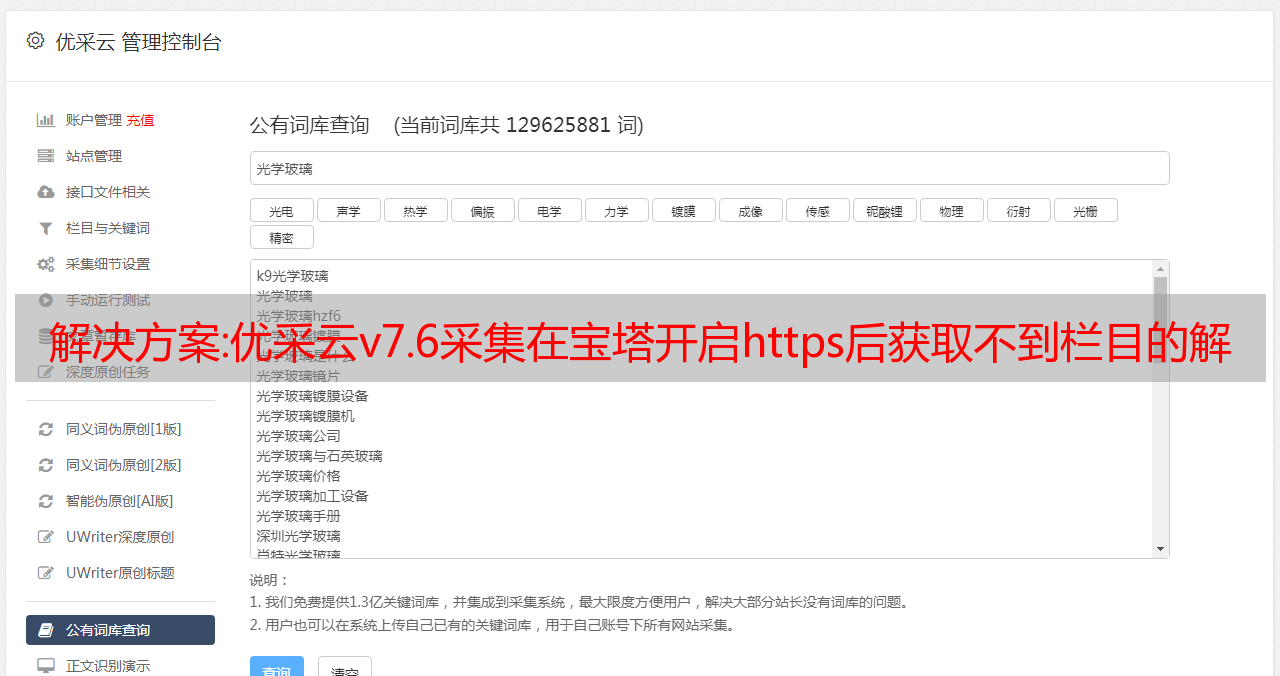
if ($server_port !~ 443) {
set $flag "${flag}1";
}
if ($request_uri !~ "/dede"){
set $flag "${flag}2";
}
if ($flag = "012"){
rewrite ^(.*)$ https://$host
permanent;}</p>
其中 /dede
是网站后台目录,也可以是免登录的PHP文件,比如/dede/jiekou.php
修改完成后,单击“保存”以正常获取该列。上一篇:
PHP评判用户UA向搜索引擎和用户展示不同页面下一篇:织梦Dedecms标签数组runphp静态生成乱码BUG解决方案
解决方案:中文网页自动采集与分类系统设计与实现
中文网页自动采集及分类系统设计与实现 保密级别: 保密期限:本人申报结果。尽管我包括其他人在教育机构的学习和贡献,但我已经签署了我在学校完成学位课程的学位申请。相关部门可发布学位论文的学位保存与汇编我签导师签名中文网页自动采集及分类系统设计与实现 摘要 随着科学技术的飞速发展,我们进入了时代的数字信息。互联网作为当今世界上最大的信息资源库,也成为人们获取信息的最重要手段。因为如何从网络上的海量信息资源中快速、准确地找到自己需要的信息,已经成为网络用户迫切需要解决的重大问题。因此,基于web的网络信息的采集和分类已成为研究热点。传统网络信息采集的目标是采集尽可能多的信息页面,甚至整个网络上的资源,在这个过程中不太关心顺序和混乱、重复的发生等由 采集 页面的相关主页。同时,有效地实现采集接收到的网页的自动分类,以创建一个更加有效和高效的搜索引擎也是非常必要的。网页分类是一种有效的信息组织和管理手段,它可以在很大程度上解决信息混乱的现象,方便用户准确判断自己需要的信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各类信息的迅速增加,仅靠人工处理已经不切实际。
因此,网页的自动分类是一种具有很大实用价值的方法,是组织和管理数据的有效手段。这也是本研究的一个重要内容。本文首先介绍了学科背景、研究目的和*敏*感*词*研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网页爬虫技术的几种典型算法和网页重复数据删除技术。之后,本文选取了分类性能优异的主题爬虫方法和KNN方法,结合去重、分词、特征提取等相关技术的配合,分析了中文网页的结构和特点,并提出了中文网页采集,最终通过编程语言实现了分类的设计和实现方法,并在文末进行了系统测试。测试结果满足系统设计要求,应用效果显着。关键词:网页信息采集网页分类信息提取分词特征提取OFCHINESEANDIMPLE转N1:ATIONDESIGNwEBPAGEAUT0~IATIC采集ANDCLASSIFICATIONABSTRACT随着科学的发展,进入了发展技术,信息迅速成为世界的信息数字化。Internet,其中最大的是maint001信息。数据库。如何从海量的信息资源中快速准确地获取用户需要的主要问题,由于网络信息资源缺乏一个特点,而呈现出海量、动态、异构、半结构化的统一信息采集管理组织。J那里的搜索和分类成为热点。信息采集以信息为目标,采集全部资源”,例如优点顺序和许多可能的页面,或内容中的主题,因此不关心采集。页面杂乱无章,被滥用的 SO 资源大部分是有节制地使用系统采集方法来减少采集的被浪费的。有效需要杂乱和 web 分类来创建页面自动复制页面。Theande cientsearchofweb 有效管理页面引擎。组织可以解决一定程度的分类iSan有效的膳食信息,这有助于用户以fiSmanual模式准确定位信息。有了传统的信息,他们需要。但是,操作信息在处理各种Internet 时,手动快速增加的方式分类并不是一种方法,而Sunrealistic Web 非常实用,也是一种有效的数据手段。Ttisan 重视,但组织管理研究这个重要的部分文件。研究现状首先介绍了网页采集理论的背景、目的、主题和分类,包括网页抓取技术、网页删除技术、重复网页提取技术、重复网页分割、特征技术、中文技术、信息网页分类提取技术等。多种爬虫和KNN制作的综合技术,专题比较典型算法之所以选择分类是因为性能出色。111e提出的中文web是经过和分类设计实现的采集结构和中文特点相结合,对web技术进行编码,实现语言页面分析。最后,编程结果符合语言。测试系统设计要求和应用程序完成。多信息分类,关键词:web采集,网页信息抽取,抽取,分割,字符法„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„。484.7.2 KNN 结 „„„„„„„„„„„„„„„„„„„„„„„„„„„„„„5253 „„„„„„„„„„„。它的编程结果是符合语言的。测试系统设计要求和应用程序完成。多信息分类,关键词:web采集,网页信息抽取抽取,分割,字法„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„„。484.7.2 KNN 结 „„„„„„„„„„„„„„„„„„„„„„„„„„„„„„5253 „„„„„„„„„„„。
63 北京邮电大学软件工程硕士论文 第1章 引言 1.1 项目背景与研究现状 1.1.1 项目背景与研究目的 以指数方式获取越来越多的信息,包括文本、数字、图形、图像、声音、视频等互联网。然而,随着网络信息的快速膨胀,如何从海量的信息资源中快速、准确地找到自己需要的信息,成为广大网络用户面临的一大难题。因此基于互联网和搜索引擎上的信息采集。这些搜索引擎通常使用一个或多个采集器从Internet、FTP、Email、News采集各种数据,然后在本地服务器上为这些数据建立索引。在索引库中快速找到您需要的信息。网络信息采集作为这些搜索引擎的基础和组成部分起着举足轻重的作用。网页信息采集是指通过网页之间的链接关系,自动从网页中获取网页信息,并随着链接不断扩展到需要的网页的过程。传统的W歌信息采集目标是采集尽可能多的信息页面,甚至全网资源,专注于采集的速度和量,相对易于实施。然而,这种传统的 采集 方法有很多缺陷。是指通过网页之间的链接关系,自动从Web中获取页面信息,并随着链接不断扩展到需要的网页的过程。传统的W歌信息采集目标是采集尽可能多的信息页面,甚至全网资源,专注于采集的速度和量,相对易于实施。然而,这种传统的 采集 方法有很多缺陷。是指通过网页之间的链接关系,自动从Web中获取页面信息,并随着链接不断扩展到需要的网页的过程。传统的W歌信息采集目标是采集尽可能多的信息页面,甚至全网资源,专注于采集的速度和量,相对易于实施。然而,这种传统的 采集 方法有很多缺陷。专注于 采集 的速度和体积,实现起来比较简单。然而,这种传统的 采集 方法有很多缺陷。专注于 采集 的速度和体积,实现起来比较简单。然而,这种传统的 采集 方法有很多缺陷。
因为基于整个 Web 采集 的信息需要采集 页面的一部分未被充分利用。用户往往只关心极少数的这些页面,而 采集器采集 的大部分页面对他们来说是无用的。这显然是对系统资源和网络资源的巨大成本。随着网页数量的快速增长,即使使用topic-setting采集技术来构建topic-setting类,也非常有必要创建一个更高效、更快速的搜索引擎。传统的操作方式是人工分类后进行组织管理。这种分类方法更准确,分类质量更高。随着互联网上各类信息的迅速增加,仅靠人工处理已经不切实际。对网页进行分类可以在很大程度上解决网页信息的杂乱问题,方便用户准确定位自己需要的信息。有效手段。这也是本研究的一个重要内容。北京邮电大学硕士论文 1.1.2 *敏*感*词*课题研究现状 网页 采集技术发展现状 互联网不断改变着我们的生活,互联网已成为当今世界最大的信息资源库,如何从庞大的信息资源库中快速准确地找到所需信息成为网络用户面临的一大难题。无论是谷歌、百度等一些通用搜索引擎,还是某个主题的专用网页采集系统,都离不开网页采集,
传统Web信息采集的页面采集太大,采集的内容太杂乱,消耗大量系统资源和网络资源。同时,互联网信息的分散状态和动态变化也是困扰信息采集的主要问题。为了解决这些问题搜索引擎。这些搜索引擎通常通过一个或多个采集器从互联网上采集各种数据,然后在本地服务器上对数据进行索引,当用户根据用户提交的需要进行检索时。即使是大型信息采集系统,其对Web的覆盖率也只有30"--40%左右。即使使用处理能力更强的计算机系统,性价比也不是很高。相对更好地满足人们的需要。其次,互联网信息的分散状态和动态变化也是影响信息采集的原因。由于信息源随时可能发生变化,因此信息采集器必须频繁刷新数据,但这仍然无法避免采集进入无效页面。对于传统信息采集,由于需要刷新的页面数量较多,采集所访问的页面有相当一部分未被充分利用。因为,用户往往只关心极少数的页面,而这些页面往往集中在一个或几个主题上,采集器极大的浪费了网络资源。这些问题主要是由传统Web信息采集的页数采集引起的 太大,页面 采集 的内容太杂乱。如果信息检索仅限于特定学科领域,并根据学科相关信息提供检索服务,那么所需的采集网页数量将大大减少,成为北京大学软件工程的第一篇论文。邮政和电信将被占用。
这类Web信息采集称为主题确定的Web信息采集,由于主题确定的采集检索范围比较大,所以查准率和查全率都比较高。然而,随着互联网的飞速发展和网页数量的爆炸式增长,即使使用主题特定的采集技术来构建主题特定的搜索引擎,与广泛的主题相比,相同的主题仍然很大。因此,如何根据给定的模式有效地对同一主题的网页进行分类,从而创建一个更有效、更快的搜索引擎是一个非常重要的课题。网页分类技术发展现状 网页自动分类是在文本分类算法的基础上结合 6>HTML 语言结构的特点发展起来的。自动文本分类最初是为了满足信息检索 InformationRetrieval 和 IR 系统的需要而开发的。信息检索系统必须操作大量的数据,其文本信息库占据了大部分内容,同时用于表示文本内容的单词数以万计。在这种情况下,提供组织良好且结构化的文本集可以大大简化文本的访问和操作。自动文本分类系统的目的是将文本集以有序的方式组织起来,并将相似和相关的文本组织在一起。作为一种知识组织工具,它为信息检索提供了更高效的搜索策略和更准确的查询结果。自动文本分类的研究始于 1950 年代后期,H. RLulm 在这方面进行了开创性的研究。
网页自动分类在国外经历了三个发展阶段:第一阶段1958.1964开展自动分类可行性研究,第二阶段1965.1974开展自动分类实验研究,第三阶段1975年。已进入实用阶段[l_]。我国对自动分类的研究起步较晚,始于1980年代初。中文文本分类的研究相对较少。*敏*感*词*的研究基本上是在英语文本分类的基础上,结合汉语文本和汉语的特点采取相应的策略,然后将其应用到汉语中,进而形成汉语文本运动。分类研究系统。1981年,侯汉清讨论了计算机在文档分类中的应用。早期系统的主要特点是结合词库进行分析和分类,人工干预的分量很大。林等人。将KNN方法与线性分类器相结合,取得了良好的效果。香港中文大学的Wai回报率接近90%。t31的准确率超过80%。C。K. P Wong 等人。研究了一种混合关键词的文本分类方法,召回率和准确率分别为72%和62%,t41。复旦大学和富士通研发中心的黄守柱、吴立德、石崎阳智研究了独立语言的文本分类,并利用词类互信息作为评分函数,使用单分类器和多分类器分别对中文和日文进行分类。文本进行了实验,最好的结果是召回率为 88.87% [5'。
上海交通大学刁谦、王永成等人结合词权重和分类算法进行分类,在使用VSM方法的封闭测试实验中分类正确N97% t71。此后,基于统计的思想,以及分词、语料库等技术不断应用于分类。万维网收录大约 115 亿个可索引的网页,每天都在增加数千万或更多。如何组织这些海量有效的信息网络资源是一个很大的现实问题。网页数量实现了网页采集的功能子系统。2、网页信息提取技术、中文分词技术分析比较,特征提取技术和网页分类技术,利用性能优异的KNN分类算法实现网页分类功能。第三,使用最大匹配算法对文本进行分段。清理网页,去除网页中的一些垃圾信息,将网页转换成文本格式。第四,网页预处理部分,结合网页的模型特点,对网页文本进行加权,不考虑HTML标记。通过以上几方面的工作,最终完成了网页自动采集分类系统的设计与实现,并对上述算法进行了实验验证。1.3 论文结构 本文共分6章,内容安排如下:第一章绪论,介绍了本课题的意义、*敏*感*词*的现状和任务。第二章介绍网页采集及分类相关技术。本章介绍了采集相关技术的原理和方法,以及将用于分类的北京邮电大学软件工程硕士论文。包括常用的网络爬虫技术、网页到页面分类技术。以及将用于分类的北京邮电大学软件工程硕士论文。包括常用的网络爬虫技术、网页到页面分类技术。以及将用于分类的北京邮电大学软件工程硕士论文。包括常用的网络爬虫技术、网页到页面分类技术。
第三章网页采集及分类系统设计。本章首先进行系统分析,然后进行系统大纲设计、功能模块设计、系统流程设计、系统逻辑设计和数据设计。第4章网页采集及分类系统实现,本章详细介绍各个模块的实现过程,包括页面采集模块、信息提取模块、网页去重模块、中文分词模块、特征向量提取模块,训练语料库模块和分类模块。第五章网页采集及分类系统测试。本章首先给出了系统的操作界面,然后给出了实验评价标准,并对实验结果进行了分析。第六章结束。本章对本文的工作进行了全面总结,给出了本文取得的成果,并指出了存在的不足和改进方向。北京第二章网页 2.1 网络爬虫技术程序也是搜索引擎的核心组件。搜索引擎的性能、规模和可扩展性很大程度上取决于网络爬虫的处理能力。网络爬虫 Crawler 也被称为网络蜘蛛 Spider 或网络机器人 Robot。网络爬虫的系统结构如图2-1所示:下载模块用于库存储从被爬取的网页中提取的URL。图 2.1 网络爬虫*敏*感*词* 网络爬虫从给定的 URL 开始,跟随网页上的传出链接。链接,根据设置的网页搜索策略,例如广度优先策略、深度优先策略或最佳优先策略,采集URL队列中优先级高的网页,然后判断是否为主题网页通过网页分类器,如果是则保存,否则丢弃;对于采集的网页,提取其中收录的URL,通过对应的地方插入到URL队列中。
2.1.1 通用网络爬虫通用网络爬虫会根据一个或几个预设的初始*敏*感*词*URL启动,下载模块会不断从URL队列中获取一个URL来访问和下载页面。页面解析器去除页面上的HTML标签得到页面内容,将摘要、URL等信息保存在web数据库中,提取当前页面新的URL保存到UURL队列中,直到系统停止条件满足。一般网络爬虫的工作流程如图2.2所示。北京邮电大学软件工程硕士论文 图2-2 万能爬虫工作流程 万能爬虫的结构如图2.3 所示。其主要模块的功能如下[8'9]: 1. Page采集 模块:该模块主要通过各种Web协议对互联网上的各种数据块进行处理,如页面分析、链接提取等。2.页面分析模块:该模块主要分析保存的页面,提取队列中的URL。此时,队列中已经收录的URL和循环链接的URL一般都会被过滤掉。3、页库:用于存放已经采集进行后期处理的页面。4、等待采集 URL队列:从采集网页中提取的URL并进行相应处理,当URL为空时,爬虫将终止。5. 初始 URL:提供 URL *敏*感*词*以启动爬虫。该模块主要分析保存的页面并提取队列中的URL。此时,队列中已经收录的URL和循环链接的URL一般都会被过滤掉。3、页库:用于存放已经采集进行后期处理的页面。4、等待采集 URL队列:从采集网页中提取的URL并进行相应处理,当URL为空时,爬虫将终止。5. 初始 URL:提供 URL *敏*感*词*以启动爬虫。该模块主要分析保存的页面并提取队列中的URL。此时,队列中已经收录的URL和循环链接的URL一般都会被过滤掉。3、页库:用于存放已经采集进行后期处理的页面。4、等待采集 URL队列:从采集网页中提取的URL并进行相应处理,当URL为空时,爬虫将终止。5. 初始 URL:提供 URL *敏*感*词*以启动爬虫。当 URL 为空时,爬虫将终止。5. 初始 URL:提供 URL *敏*感*词*以启动爬虫。当 URL 为空时,爬虫将终止。5. 初始 URL:提供 URL *敏*感*词*以启动爬虫。
根据给定的出生。焦点爬虫FocusedCrawler,又称主题爬虫Topical的爬取目标,选择性地访问万维网上的网页和相关链接,获取需要的信息,获取符合预定爬取目标的信息,因此返回的数据资源更多准确【11'12J. 聚焦爬虫需要根据一定的网页分析算法过滤掉不相关的链接,保留有用的链接,并将其放入待爬取的URL队列中。然后按照一定的检索策略检索北京邮电大学的硕士论文文件。所有爬取的网页都会被系统存储,经过一定的分析、过滤,然后建立搜索供用户查询和检索;在这个过程中得到的分析结果可以为后续的爬取过程提供反馈和指导。焦点爬虫的工作流程如图 24 所示。 陈] 2-4 焦点爬虫的工作流程 与一般的网络爬虫相比,焦点爬虫需要解决以下问题: 爬取目标的描述或定义是决定如何进行制定网页分析算法和URL搜索策略。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。互联网上网页的主题分析和网页信息的过滤是海量的,我们希望采集到一小部分信息,
那么,URL搜索策略是如何在这个庞大的万维网上引导聚焦爬虫的呢?2.5 深度爬虫流程图 深度爬虫与普通爬虫的区别在于,深度爬虫下载页面后不会立即遍历页面。10 北京邮电大学软件工程硕士论文记录了其中的所有超链接,但使用一定的算法对其进行分类。下载的页面是通过提交表单来访问的,所以爬深页面有以下三个难点。*敏*感*词*数据;许多服务器端 DeepWeb 需要验证表单输入,例如用户名、密码和验证。如果验证失败,爬虫将无法访问UDeepWeb数据;客户端 DeepWeb 的分析需要 JavaScript 等脚本的支持。通过对上述三种爬虫技术的对比,我们发现深网爬虫实现起来难度比较大,在对比普通爬虫和聚焦爬虫之后,在第三章中将采用聚焦主题技术进行系统设计。2.2 中文网页信息提取技术 2.2.1 中文网页特征分析 要实现网页的自动分类,首先要了解网页的基本结构,然后提取网页中的信息。网页由文本和 HTML 标记组成。尽管互联网上有多种形式的信息载体,但文字仍然是互联网上信息的主要来源。网页不同于文本文件。它以 RTML HypertextMarkup 后缀结尾。
标题中的内容与网页的主题密切相关,是对整个内容的总结。关键词 关键词一般是专业词,它比其他特征项更能确定网页的类别。元标签可以在网页的头部/头部之间使用,以描述页面的关键字。网页正文 网页正文是描述网页内容的文本,介于body/body之间。大多数专业网站 主要是用自然语言编写的。快速准确地识别网页中的正文内容是提高网页分类准确性的一项重要而关键的任务。根据网页的形式,网页可以分为:主题网页、相关链接从自然语言文档中提取特定信息、主要利用文本中的语法和语义信息来提取合理的自由文本OH新闻报道。信息抽取系统中的关键部件是一系列抽取规则和模式,用于确定要抽取的信息主题。对网络文本信息海量增长的研究受到高度重视。人们提出了多种不同的技术来实现网页信息提取,通常由包装器完成,包装器是一种可以从HTML页面中提取数据并将其还原为结构化数据的软件。程序。根据包装器工作原理的不同,信息抽取可分为以下几类:基于自然语言处理的信息抽取、基于归纳学习的信息抽取、
l. 基于自然语言处理的信息抽取:这类信息抽取主要适用于源文档中收录大量文本的信息。借助自然语言处理技术NLP,汇总数据抽取规则,抽取符合自然语言规则的文档数据。首先过滤掉网页的HTML标签,然后采用词性标注和语法分析的方法构建信息并提取,更适合符合语法规则且由文本组成的HTML文档. 2.基于归纳学习的信息抽取:基于归纳学习方法的信息抽取对用户预先标记的一系列训练样本进行分析,并根据分隔符生成提取规则。其中,分隔符本质上是对感兴趣的语义项的上下文的描述。最大的不同是归纳学习方法只使用语义项的上下文来定位信息,不依赖语言约束,而是基于半结构化文档。格式特征形成提取规则。这种方法比基于自然语言处理的方法更适合 HTML 文档。但由于基于归纳学习的信息抽取技术需要大量人工参与,必须进行大量样本训练才能获得准确的抽取规则,用户负担沉重,难以完全实现自动提取。3. 基于HTML结构的信息抽取:这种信息抽取技术的特点是根据网页的结构来定位信息。信息抽取前——12北京邮电大学软件工程硕士论文,通过解析器将w歌文档解析成句法树,将信息抽取转化为句法树的操作语义分析部分。基本实现了全自动模式,大大减轻了用户的工作量,在网络信息的提取方面取得了长足的进步。存在的问题是提取结果的粒度比较粗,系统的鲁棒性稍差。4、基于自定义查询语言的信息抽取:基于自定义查询语言的信息抽取技术是在信息抽取过程中,以自定义查询语言作为启发式规则来抽取信息。它比简单分析网页结构的技术更有效。

