汇总:【抓包分析】采集豆瓣排名数据的脚本源码
优采云 发布时间: 2022-11-07 04:35汇总:【抓包分析】采集豆瓣排名数据的脚本源码
大家好,我是来自公众号3分钟学院的郭丽媛。今天给大家带来的是数据采集的源码分享。
本期以采集豆瓣排名数据为例:
分析
1、采集的内容:%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
选择任何类型电影的图表。
其次,尝试获取网页的源代码。
TracePrint url.get("https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=")
三、分析返回值
发现返回值不收录排行榜的内容,也就是说排行榜的内容是动态加载的,无法通过直接读取该URL的网页源码获取。
4.抓包分析,打开浏览器后按f12键,刷新网页,使用浏览器自带的抓包功能对网页进行分析。
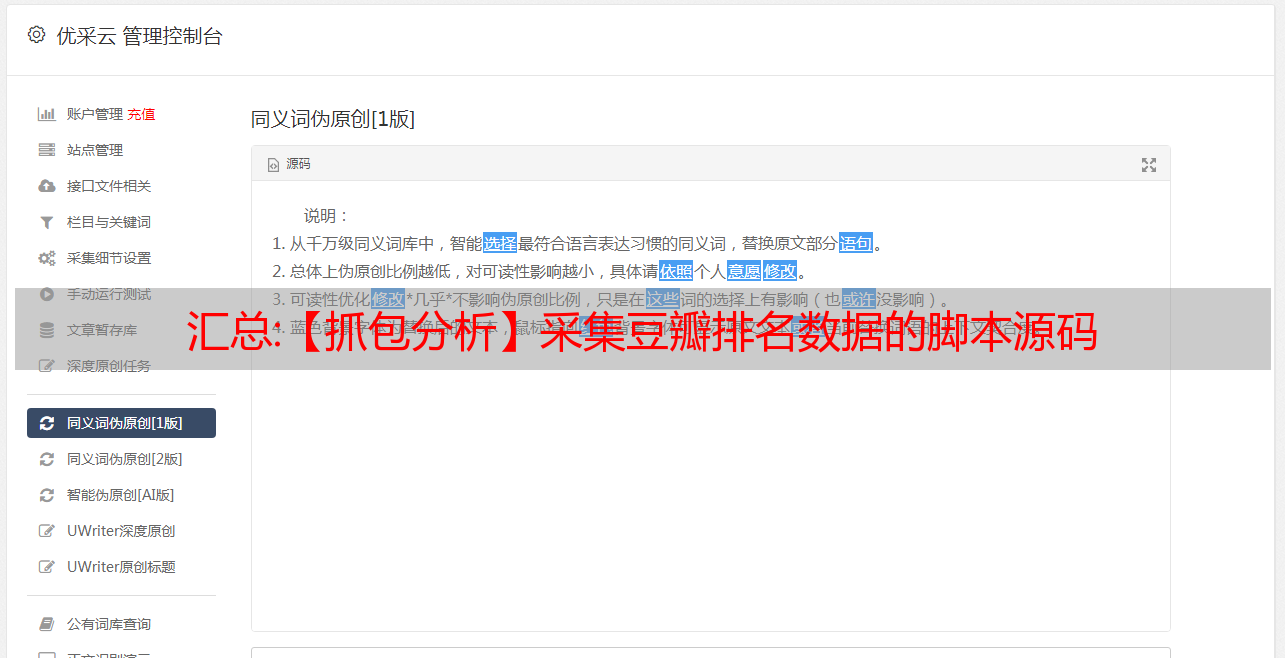
根据上图点击网络和标题。之后,因为有很多数据,我们用ctrl+f来搜索。搜索内容为热门电影《美丽人生》的片名,搜索结果有两个:
让我们选择其中一个进行分析,并首先复制URL。
%3A90&action=&start=0&limit=20
我们直接分析问号后面的部分参数:
type=24=> 电影类型:24
interval_id=100%3A90=>视频被点赞:100%-90%(%3A是冒号)
action==> 没有值,暂时无法判断,直译action可以省略
start=0=> 起始位置,第一位开始
limit=20=>显示多少,限制最多20
在这些参数中,需要从原创URL中提取视频类型:(下图红色部分)
%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
每种类型对应一个数字,比如喜剧是24,动作是5,其他类型可以点击更多类型一个一个看网站。
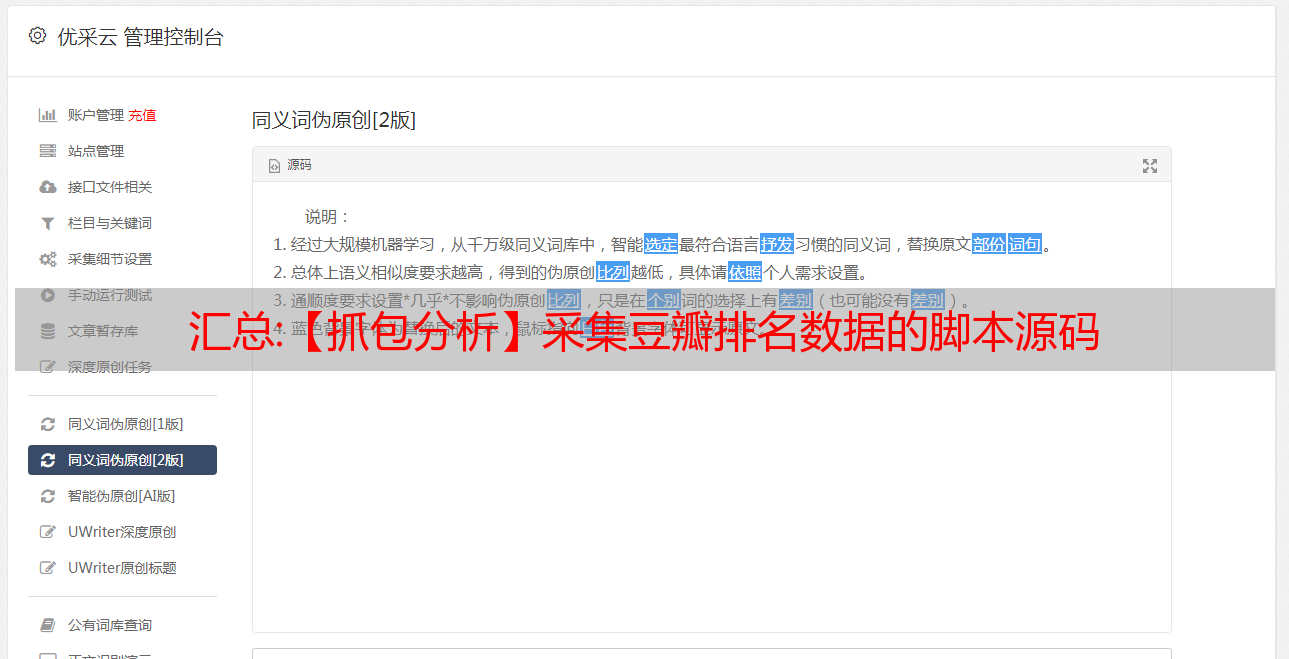
5.获取网页源代码
TracePrint url.get("https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=20")
6.网页返回值:
返回值是一个json。这里的提取是先对表进行转换,然后使用键值对进行提取。如果你不在我的公众号(3分钟学校)搜索json,有很多关于json提取的文章教程。
脚本源
dim json= url.get("https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90")Dim table=encode.jsontotable(json)For i = 1 To Len(table)TracePrint table[i]["title"],table[i]["rating"][1]Next
复活节彩蛋
先点看,再上教程,关注“3分钟学”,回复关键词【教程】下载我的基础教程。
新QQ交流群11已创建:936858410,有兴趣可以加入!
vip群①群:242971687(满)
vip群②群:242971687(群费48.8,提供基础教程问答,2118小伙伴已加入付费群)
汇总:Kubernetes日志采集方案
前言
上一期主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,记录采集的方式与普通虚拟机有很大不同,相对实现难度和部署成本也略高。但是,如果使用得当,可以实现比传统方式更高的自动化程度和更低的运维成本。
Kubernetes 日志采集 难点
在 Kubernetes 中,logging采集 比传统的虚拟机和物理机要复杂得多。最根本的原因是Kubernetes屏蔽了底层异常,提供了更细粒度的资源调度,向上提供了一个稳定动态的环境。因此,log采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
对于一个运行时间很短的Job应用,从启动到停止只需要几秒,如何保证日志采集的实时性能跟得上,数据不丢失?K8s 一般推荐使用大型节点。每个节点可以运行 10-100+ 个容器。如何以尽可能低的资源消耗采集100+ 个容器?在K8s中,应用以yaml的形式部署,日志采集主要是手动配置文件的形式。日志采集如何以K8s的方式部署?
Kubernetes传统日志类型文件、stdout、host文件、journal文件、journal日志源业务容器、系统组件、宿主业务、宿主采集方法代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)代理、直接-write 单机应用号 10-1001-10 应用动态高低 节点动态高低 采集 部署方式手动、Yaml手动、自定义
采集模式:主动或被动
日志采集方法有两种:被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方式。主动推送包括 DockerEngine 推送和业务直推。写两种方式。
总结:DockerEngine直接写一般不推荐;日志量大的场景推荐业务直写;DaemonSet 一般用于中小型集群;建议在非常大的集群中使用 Sidecar。各种采集方法的详细对比如下:
DockerEngine业务直接写入DaemonSet方法Sidecar方法采集*敏*感*词*志高,可定制根据业务特点 高,可自定义查询,高统计,可根据业务特点自定义 低和高 可定制性,可自由扩展低和高,每个POD单独配置高耦合,强绑定DockerEngine 固定, 修改需要重启 DockerEngine High, 采集
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件。在容器中,标准输出直接将日志输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,收到日志后根据DockerEngine配置的LogDriver规则进行处理;日志打印到文件的方式与虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然 Docker 官方推荐使用 Stdout 打印日志,但需要注意的是,这个推荐是基于容器仅作为简单应用使用的场景。在实际业务场景中,我们还是建议大家尽量使用文件方式。主要原因如下。观点:
stdout性能问题,从应用输出stdout到服务器,会有几个过程(比如常用的JSON LogDriver):应用stdout -> DockerEngine -> LogDriver -> 序列化成JSON -> 保存到文件 -> Agent采集文件 -> 解析 JSON -> 上传服务器。整个过程需要比文件更多的开销。压力测试时,每秒输出 10 万行日志会占用 DockerEngine 的额外 CPU 内核。stdout 不支持分类,即所有输出混合在一个流中,不能像文件一样分类输出。通常,一个应用程序包括AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog等。这些日志的格式和用途不,会很难采集 如果在同一流中混合,则进行分析。stdout 只支持容器主程序的输出。如果是 daemon/fork 模式下运行的程序,则无法使用 stdout。文件转储方式支持多种策略,如同步/异步写入、缓存大小、文件轮换策略、压缩策略、清除策略等,相对更加灵活。
因此,我们建议在线应用使用文件输出日志,而Stdout仅用于功能单一或部分K8s系统/运维组件的应用。
CICD 集成:日志记录操作员
Kubernetes提供了标准化的业务部署方式,可以通过yaml(K8s API)声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分。必须实时采集业务上线后的所有日志。
原来的方法是在发布后手动部署log采集的逻辑。这种方式需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始基于日志打包API/SDK采集一个自动部署的服务,发布后通过CICD的webhook触发调用,但这种方式开发成本高。
在 Kubernetes 中,集成日志最标准的方式是在 Kubernetes 系统中注册一个新资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统就不需要额外开发,部署到Kubernetes系统时只需要附加日志相关的配置即可。
Kubernetes 日志采集 方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发 log采集 解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的 log采集 方案。主要功能有:
支持各种数据的实时采集,包括容器文件、容器Stdout、宿主文件、Journal、Event等;支持多种采集部署方式,包括DaemonSet、Sidecar、DockerEngine LogDriver等;日志数据丰富,包括Namespace、Pod、Container、Image、Node等附加信息;稳定高可靠,基于阿里巴巴自研Logtail采集Agent实现。目前,全网部署实例数以百万计。; 基于CRD扩展,日志采集规则可以以Kubernetes部署发布的方式部署,与CICD完美集成。
安装日志采集组件
目前,这个采集解决方案已经对外开放。我们提供 Helm 安装包,收录 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明和 CRD Controller。安装后直接使用DaemonS优采云采集器即可,CRD配置完毕。安装方法如下:
阿里云Kubernetes集群在激活的时候就可以安装,这样在创建集群的时候会自动安装以上的组件。如果激活的时候没有安装,可以手动安装。如果是自建Kubernetes,无论是自建在阿里云上还是在其他云上还是离线,都可以使用这个采集方案。具体安装方法请参考【自建Kubernetes安装】()。
上述组件安装完成后,Logtail和对应的Controller会在集群中运行,但默认这些组件不会采集任何日志,需要配置日志采集规则为采集 指定各种日志的Pod。
采集规则配置:环境变量或CRD
除了在日志服务控制台上手动配置外,Kubernetes 还支持另外两种配置方式:环境变量和 CRD。
环境变量是自swarm时代以来一直使用的配置方式。您只需在要采集的容器环境变量上声明需要采集的数据地址,Logtail会自动将数据采集传输到服务器。该方法部署简单,学习成本低,易于使用;但是可以支持的配置规则很少,很多高级配置(如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明方式也不支持修改/删除,每个修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
CRD的配置方式非常符合Kubernetes官方推荐的标准扩展方式,允许采集配置以K8s资源的形式进行管理,通过部署特殊的CRD资源AliyunLogConfig到Kubernetes来声明数据这需要 采集。例如,下面的例子是部署一个容器的标准输出采集,其中定义需要Stdout和Stderr 采集,并排除环境变量收录COLLEXT_STDOUT_FLAG: false的容器。基于CRD的配置方式以Kubernetes标准扩展资源的方式进行管理,支持配置的完整语义的增删改查,支持各种高级配置。
采集推荐的规则配置方式
在实际应用场景中,一般使用 DaemonSet 或者 DaemonSet 和 Sidecar 的混合。DaemonSet 的优点是资源利用率高。但是存在一个问题,DaemonSet的所有Logtail共享全局配置,单个Logtail有配置支持上限。因此,它无法支持具有大量应用程序的集群。以上是我们给出的推荐配置方式。核心思想是:
一个尽可能多的采集相似数据的配置,减少了配置的数量,减轻了DaemonSet的压力;核心应用 采集 需要获得足够的资源,并且可以使用 Sidecar 方法;配置方式尽量使用CRD方式;Sidecar 由于每个Logtail都是独立配置的,所以配置数量没有限制,适用于非常大的集群。
练习 1 - 中小型集群
大多数 Kubernetes 集群都是中小型的。中小企业没有明确的定义。一般应用数量小于500,节点规模小于1000。没有功能清晰的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet可以支持所有的采集配置:
大部分业务应用的数据使用DaemonS优采云采集器方式,核心应用(对于可靠性要求较高的采集,如订单/交易系统)单独使用Sidecar方式采集
练习 2 - 大型集群
对于一些用作PAAS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上。有专门的Kubernetes平台运维人员。这种场景下应用的数量没有限制,DaemonSet 无法支持。因此,必须使用 Sidecar 方法。总体规划如下:
Kubernetes平台的系统组件日志和内核日志的类型是比较固定的。这部分日志使用了DaemonS优采云采集器,主要为平台的运维人员提供服务;每个业务的日志使用Sidecar方式采集,每个业务可以独立设置Sidecar的采集目的地址,为业务的DevOps人员提供了足够的灵活性。

