教程:优采云自动采集发布插件|优采云WordPress采集发布插件 V
优采云 发布时间: 2022-11-06 12:54教程:优采云自动采集发布插件|优采云WordPress采集发布插件 V
优采云 WordPress采集发布插件是使用PHP语言开发的博客平台,可以用作网站或通过WordPress作为cms,用户可以使用它一键将优采云上抓取/购买/创建的数据发布到您的WordPress网站。
[软件功能]。
1. 数据采集自动重复数据删除
在优采云上抓取的数据会根据 URL 自动进行重复数据删除,您还可以自定义重复数据删除基础
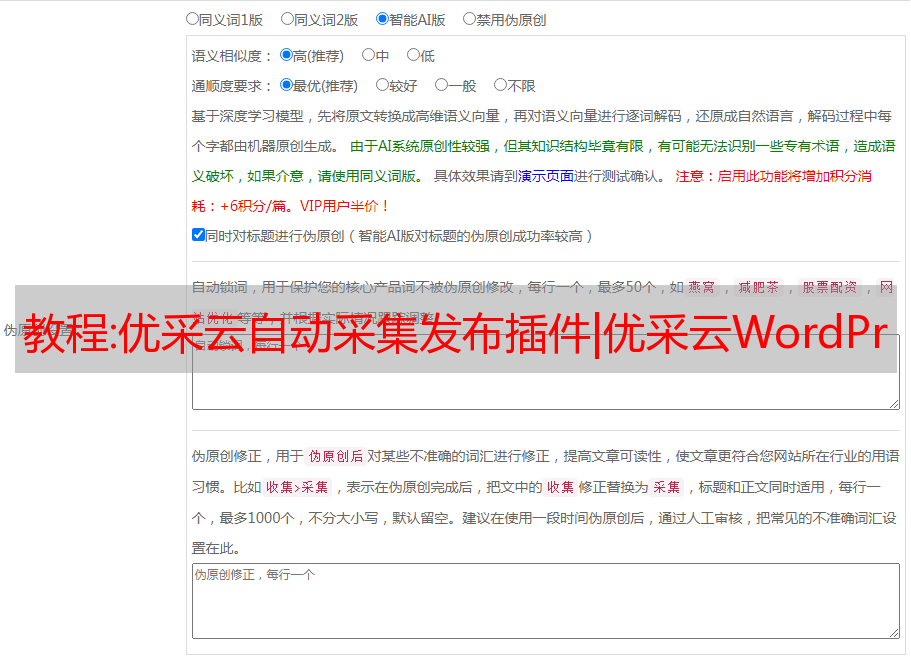
2. 自动数据发布
安装插件后,一键即可将采集数据自动发布到您的网站,实现可视化控制
3.定期运行并自动更新
支持定时采集任务,自动采集最新数据,更新旧数据
4.自动下载图片和其他文件
在采集过程中,您可以启用文件云托管并自动下载图像/音频和视频文件
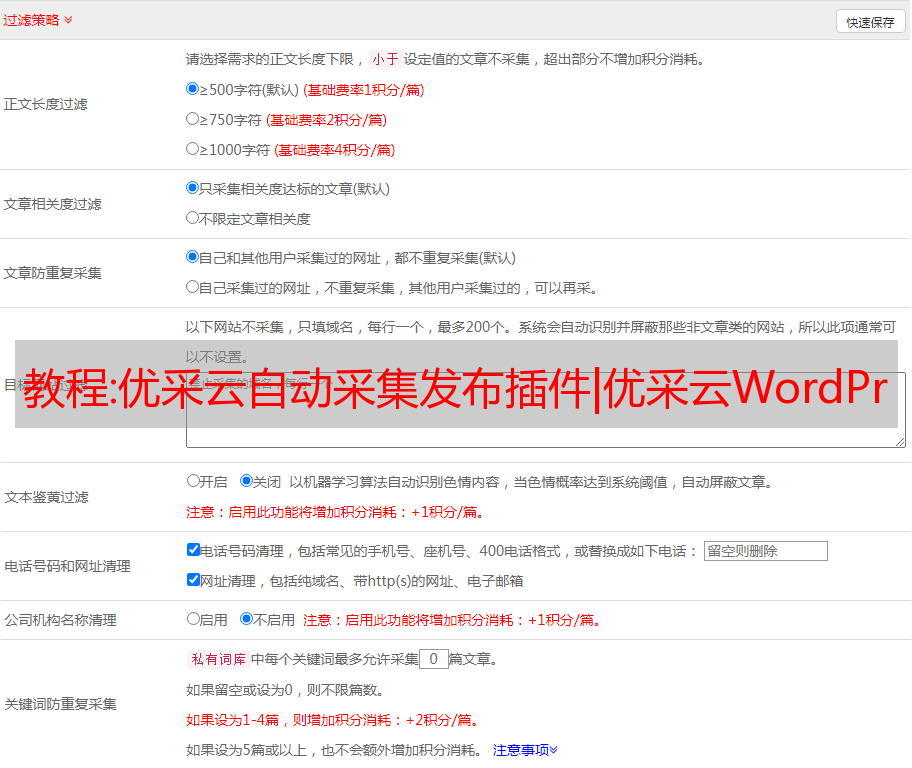
5. 伪原创/搜索引擎优化支持
数据可以在发布之前链接和关键词替换,这有助于伪原创和SEO优化
6.支持字段映射,WordPress功能
支持发布为草稿、设置文章访问密码和缩略图、自定义字段映射等
提示:插件安装完成后,数据采集和发布全部登录优采云官网进行操作~
最新信息:数据治理 | 数据采集实战:动态网页数据采集
我们将在数据治理版块推出一系列原创推文,帮助读者构建完善的社会科学研究数据治理软硬件体系。本节将涉及以下模块:
计算机基础
(1)
编程基础
(1)
(2)
(3)
(4)
(5)
(6)
数据采集
(1)
(2)
(3) 本期内容:数据治理 | 数据采集实践:动态网页数据采集
数据存储
(1) 安装
(2) 管理
(3) 数据导入
(4)
数据清洗 数据实验室建设 Part1 简介
在上一条推文中,我们已经解释了静态网页的 采集 方法。在本文中,我们介绍动态网页的方法采集。
本文采集的例子网站为:我们的目标是采集网页中指定的文字信息,并保存。
完整代码见文末附件!
Part2 什么是动态网页
通常,我们要提取的数据不在我们下载的 HTML 源代码中。比如我们刷QQ空间或者微博评论的时候,一直往下滑,网页不刷新就会越来越长,内容越来越多。
具体来说,当我们浏览网站时,用户的实际操作(如向下滚动鼠标滚轮加载内容)不断向服务器发起请求,并使用JavaScript技术将返回的数据转换成新的内容添加到网页。以百度图片为例: ,我们进入百度图片后,搜索我们要找的图片,然后不断向下滚动页面,会看到网页中不断加载图片,但是网页没有刷新,这个动态加载页面。
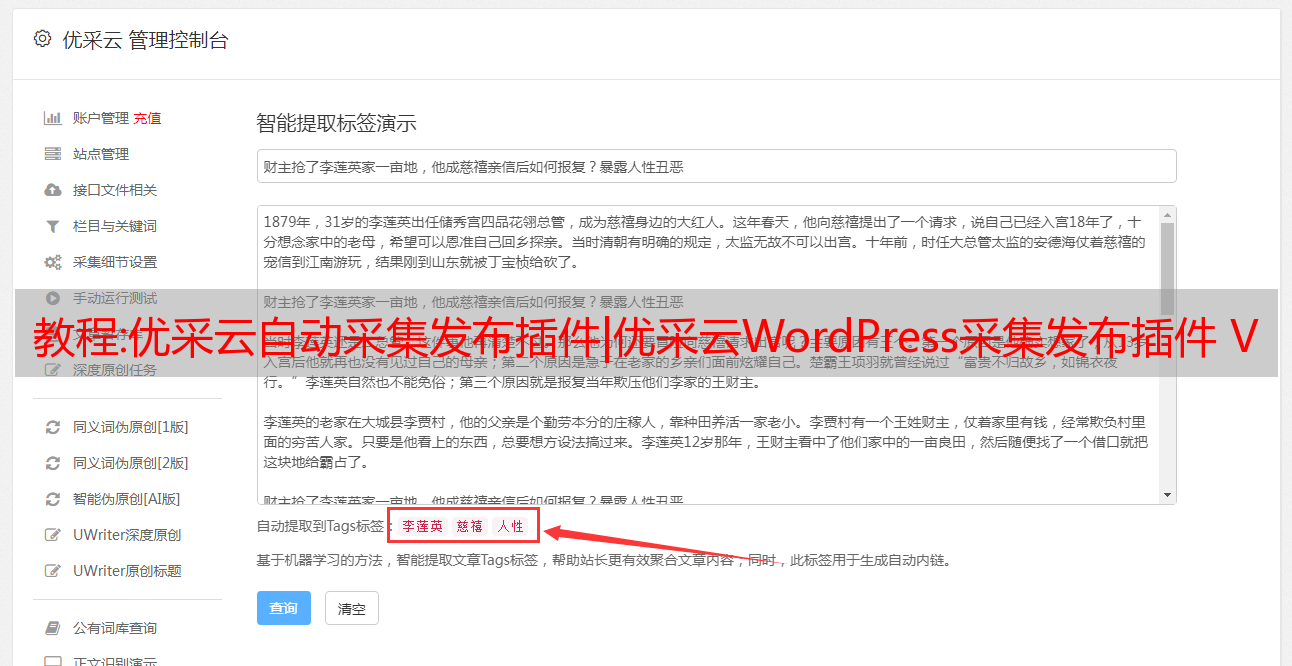
Part3 手册采集操作步骤
本文中采集的例子网站为:,内容如下图所示:
假设我们需要采集的内容是:文章的标题,关键词,这4部分的发布日期和详情链接,对于标题的3部分,关键词,发布日期信息我们可以在列表页面上看到。详情链接,我们还需要点击网站到采集上的指定详情页面,如下图:
假设我们要采集有很多内容,单独手动采集操作会浪费很多时间,那么我们可以使用Python来自动化采集数据。
Part4 自动采集的步骤(一)动态加载页面分析
在不刷新网页的情况下,网站需要点击网页末尾的按钮来加载新数据,如下图所示:
我们打开开发者工具(谷歌浏览器按F12),点击过滤器XHR,然后多次点击网页底部的按钮加载内容。我们可以看到,每次点击按钮,我们都可以抓包,我们查看抓包信息,可以发现请求返回的响应内容中收录了我们想要的数据。实际操作如下:
网页中显示的内容:
所以我们可以直接请求这个接口来获取我们想要的数据。我们首先提取这三个不同请求的URL,如下图:
第2页:https://www.xfz.cn/api/website/articles/?p=2&n=20&type=<br />第3页:https://www.xfz.cn/api/website/articles/?p=3&n=20&type=<br />第4页:https://www.xfz.cn/api/website/articles/?p=4&n=20&type=
提示:此 URL 是带有参数的 GET 请求。域名和参数用?分隔,每个参数用&分隔。
我们观察每个页面的 URL 参数的变化,发现 p 是三个参数中的一个可变参数。我们每点击一次,p就加1,所以p参数和翻页有关。我们可以通过修改 p 参数来访问它。从不同页面的信息内容我们也可以推断,当p参数的值为1时,就是请求网站的第一页的内容。
(二)代码实现 1.请求页面并解析数据
import requests<br />import time<br /><br />for page in range(1, 6): # 获取5页数据<br /> # 利用format构造URL<br /> url = 'https://www.xfz.cn/api/website/articles/?p={}&n=20&type='.format(page)<br /> # 发送请求获取响应<br /> res = requests.get(url=url)<br /> # 将响应的json格式字符串,解析成为Python字典格式<br /> info_dic = res.json()<br /> # 提取我们想要的数据,并格式化输出<br /> for info in info_dic['data']:<br /> result = {<br /> 'title': info['title'],<br /> 'date': info['time'],<br /> 'keywords': '-'.join(info['keywords']),<br /> 'href': 'https://www.xfz.cn/post/' + str(info['uid']) + '.html'<br /> }<br /> print(result)<br /> time.sleep(1) # 控制访问频率<br />
执行结果(部分):
{'title': '「分贝通」完成C+轮1.4亿美元融资', 'date': '2022-02-17 10:17:13', 'keywords': '分贝通-DST Global', 'href': 'https://www.xfz.cn/post/10415.html'}<br />{'title': '「塬数科技」完成近亿元A轮融资,凡卓资本担任独家财务顾问', 'date': '2022-02-15 10:17:42', 'keywords': '塬数科技-凡卓资本-晨山资本-博将资本', 'href': 'https://www.xfz.cn/post/10412.html'}<br />{'title': '「BUD」获1500万美元A+轮融资', 'date': '2022-02-14 10:15:35', 'keywords': '启明创投-源码资本-GGV纪源资本-云九资本', 'href': 'https://www.xfz.cn/post/10411.html'}<br />{'title': '以图计算引擎切入千亿级数据分析市场,它要让人人成为分析师,能否造就国内百亿级黑马', 'date': '2022-02-10 11:04:52', 'keywords': '欧拉认知智能-新一代BI', 'href': 'https://www.xfz.cn/post/10410.html'}<br />{'title': '前有Rivian市值千亿,后有经纬、博原频频押注,滑板底盘赛道将诞生新巨头?丨什么值得投', 'date': '2022-02-09 11:51:36', 'keywords': '什么值得投', 'href': 'https://www.xfz.cn/post/10409.html'}<br />
2.保存到本地csv
在原代码的基础上,我们添加了一点内容,并将我们爬取的内容保存到一个CSV文件中。有很多方法可以将其保存到 CSV 文件。这里我们使用pandas第三方模块来实现,需要pip install pandas。安装。
import requests<br />import time<br />import pandas as pd # 导入模块<br /><br /># 创建一个数据集,用来保存数据<br />data_set = [<br /> ('标题', '日期', '关键词', '详情链接'), # 这边先定义头部内容<br />]<br />for page in range(1, 6): # 获取5页数据<br /> # 利用format构造URL<br /> url = 'https://www.xfz.cn/api/website/articles/?p={}&n=20&type='.format(page)<br /> # 发送请求获取响应<br /> res = requests.get(url=url)<br /> # 将响应的json格式字符串,解析成为Python字典格式<br /> info_dic = res.json()<br /> # 提取我们想要的数据,并格式化输出<br /> for info in info_dic['data']:<br /> result = {<br /> 'title': info['title'],<br /> 'date': info['time'],<br /> 'keywords': '/'.join(info['keywords']), # 关键词会含有多个,每个关键词用斜杠隔开<br /> 'href': 'https://www.xfz.cn/post/' + str(info['uid']) + '.html' # 构造详情页url<br /> }<br /> # 获取字典里面的值,并转换成列表<br /> info_list = list(result.values())<br /> # 添加到数据集<br /> data_set.append(info_list)<br /> time.sleep(1) # 控制访问频率<br /><br /># 保存成为csv文件<br />df = pd.DataFrame(data_set)<br />df.to_csv('xfz.csv', mode='a', encoding='utf-8-sig', header=False, index=False)<br />
执行结果(部分):
Part5总结
文中介绍了动态网站data采集的基本流程和方法,结合上期我们讲的静态网页数据采集实战,相信大家已经掌握了数据采集基本功。那么返回的数据采集 呢?请继续关注下一条推文:Python 数据处理的基础知识。
附件:get_web_data.py
import requests<br />import time<br />import pandas as pd # 导入模块<br /><br /># 创建一个数据集,用来保存数据<br />data_set = [<br /> ('标题', '日期', '关键词', '详情链接'), # 这边先定义头部内容<br />]<br />for page in range(1, 6): # 获取5页数据<br /> # 利用format构造URL<br /> url = 'https://www.xfz.cn/api/website/articles/?p={}&n=20&type='.format(page)<br /> # 发送请求获取响应<br /> res = requests.get(url=url)<br /> # 将响应的json格式字符串,解析成为Python字典格式<br /> info_dic = res.json()<br /> # 提取我们想要的数据,并格式化输出<br /> for info in info_dic['data']:<br /> result = {<br /> 'title': info['title'],<br /> 'date': info['time'],<br /> 'keywords': '/'.join(info['keywords']), # 关键词会含有多个,每个关键词用斜杠隔开<br /> 'href': 'https://www.xfz.cn/post/' + str(info['uid']) + '.html' # 构造详情页url<br /> }<br /> # 获取字典里面的值,并转换成列表<br /> info_list = list(result.values())<br /> # 添加到数据集<br /> data_set.append(info_list)<br /> time.sleep(1) # 控制访问频率<br /><br /># 保存成为csv文件<br />df = pd.DataFrame(data_set)<br />df.to_csv('xfz.csv', mode='a', encoding='utf-8-sig', header=False, index=False)<br />
明星⭐我们不会迷路的!想要文章及时到达,文末“看”很有必要!
点击搜索您感兴趣的内容
过去推荐
数据研讨会
这是大数据、分析技术和学术研究的三向交叉点
文章 | 《大数据时代社会科学研究数据治理实践手册》

