解决方案:快速云:什么是站群,站群怎么做?站群服务器怎么挑?
优采云 发布时间: 2022-11-06 09:28解决方案:快速云:什么是站群,站群怎么做?站群服务器怎么挑?
站群在网络技术中应用广泛,所以站群的概念并不是网络技术人员的范本。站群的使用为视频行业、直播行业、旅游金融行业等诸多行业带来了更多价值。以下是站群的定义、站群的定义以及站群服务器的选择。
站群 的定义
网站的组合一般有几到几百个,其中一半的范围从几到几千甚至几万不等。站群网站可以理解为一组网站,但是这些网站的拥有者是同一个人。这些网站统称为站长的站群。站群的原理是通过搜索引擎自然优化规则的推广,从搜索引擎流量中获取更多的流量。
站群怎么样?
1.设置一个网站主题
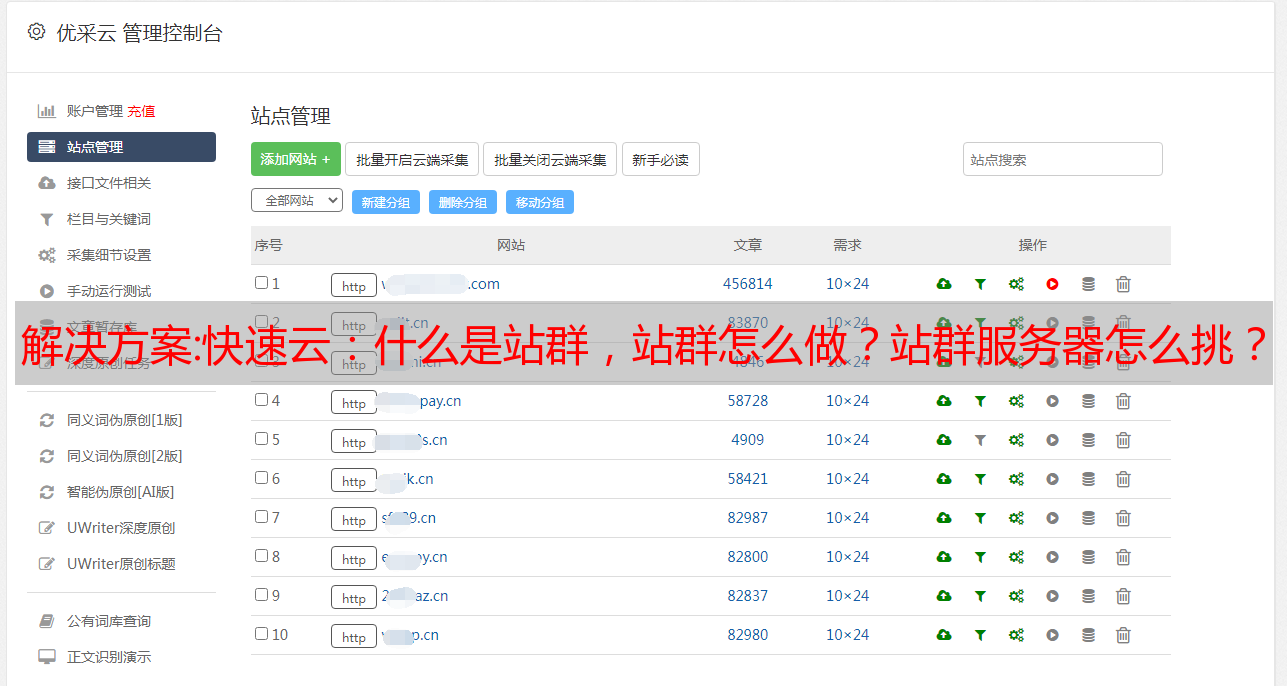
网站站群的构建需要足够长的尾巴关键词,而百度等大搜索引擎中的相关内容收录很大,SEO站群都这样需要做的是采集大量的内容,其中长尾关键词和内容要足够,这样SEO站群才能做到。
2.专业内容采集技术
站群失败的大部分原因是由于采集技术的缺失,以及对百度算法缺乏深入研究,导致站群变成垃圾站群。采集获取的内容没有阅读价值,流量介绍不好。因此,对于站群专业内容采集技术的开发非常重要。
3.涉及很多关键词
站群一般涵盖几个甚至几十万个关键词,包括相关的品牌词、行业词、长尾词等。站群的量级越大,它的流量就越多带来,但是像比较关键词可以吸引更精准的流量,所以部署大流量关键词也很重要。
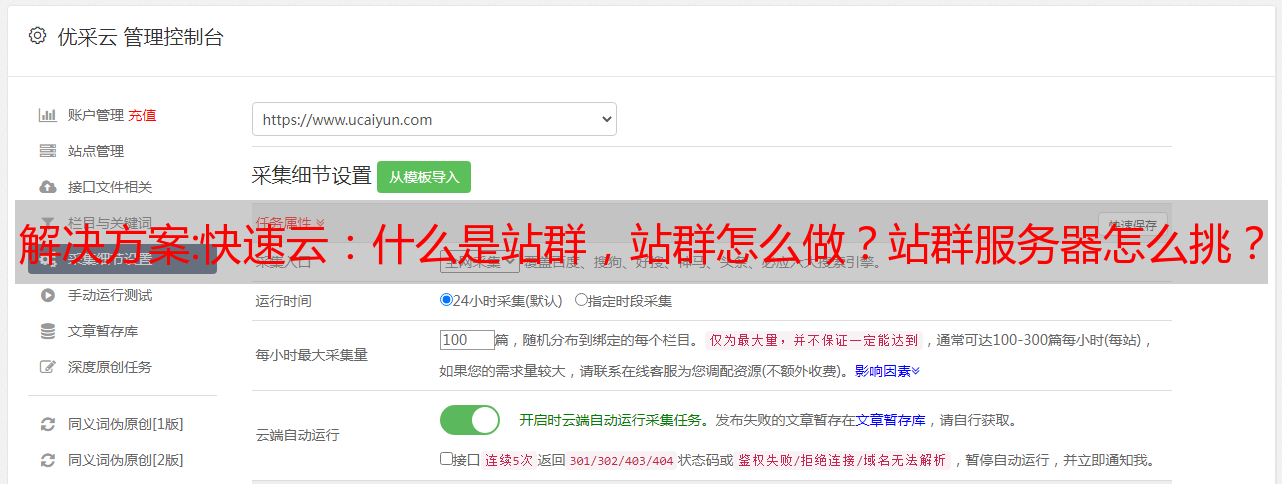
四、提升整体网站流量
网站的整体流量得到了提升,这是做站群最积极的结果。除了优化关键词的排名,足够的词可以覆盖大量的长尾词,这样可以增加曝光率,让站群获得越来越多的精准流量。
站群服务器选择
服务器的线路在国内分为电信和网通线路,区分了南方用户和北方用户的接入,所以出现了南北互通的情况。目前比较流行的是BGP多线线路,解决了线路不兼容的问题。.
优化的解决方案:NVIDIA 自动驾驶算法的keras(TensorFlow)实现
NVIDIA 端到端自动驾驶深度学习算法
上一篇文章文章提到使用tf来实现,但是当时写的代码版本已经老了,所以干脆用keras重写了,后端还是用tensorflow。
本文使用Udacity的开源无人驾驶模拟器生成数据并测试效果:
udacity/自动驾驶汽车模拟
模拟器的使用方法可以参考:
udacity/CarND-行为克隆-P3
先上模型*敏*感*词*
其实代码比较清晰,更何况Keras真的是一个非常好用的工具,写的模型也很干净整洁。
使用的 API
顺序模型指南
卷积层 conv2d - Keras 文档
卷积层cropping2d - Keras 文档
核心层扁平化 - Keras 文档
核心层密集 - Keras 文档
核心层 lambda - Keras 文档
核心层丢失 - Keras 文档
# 数据载入依赖
import csv
import cv2
import numpy as np
# 模型构建依赖
from keras.models import Sequential
from keras.layers import Conv2D, Cropping2D
from keras.layers import Flatten, Dense, Lambda, Dropout
# 模型数据处理所需要的依赖
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# 加载训练数据
LINES = []
# 数据矫正值,用于纠正方向盘角度
CORRECTION = 0.2
# 从数据集中读取必要数据
with open('./data/driving_log.csv') as csvfile:
READER = csv.reader(csvfile)
for line in READER:
LINES.append(line)
<p>
# 分组出训练集与校验集
TRAIN_SAMPLES, VALIDATION_SAMPLES = train_test_split(LINES, test_size=0.2)
# 用一个*敏*感*词*来传入训练数据,避免出现内存不足的情况
def generator(samples, batch_size=32):
"""
generat training samples
"""
num_samples = len(samples)
while 1: # Loop forever so the generator never terminates
shuffle(samples)
for offset in range(0, num_samples, batch_size):
batch_samples = samples[offset:offset+batch_size]
images = []
measurements = []
for batch_sample in batch_samples:
# Use 3 cameras
measurement = float(batch_sample[3])
measurement_left = measurement + CORRECTION
measurement_right = measurement - CORRECTION
for i in range(3):
source_path = batch_sample[i]
filename = source_path.split('/')[-1]
current_path = './data/IMG/' + filename
image_bgr = cv2.imread(current_path)
# OpenCV的大坑,大坑啊!!!
image = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
# image = cv2.resize(image, (80, 160), cv2.INTER_NEAREST)
images.append(image)
# Augment image
images.append(cv2.flip(image, 1))
measurements.extend([measurement,
measurement*-1,
measurement_left,
measurement_left*-1,
measurement_right,
measurement_right*-1])
x_train = np.array(images)
y_train = np.array(measurements)
yield shuffle(x_train, y_train)
TRAIN_GENERATOR = generator(TRAIN_SAMPLES, batch_size=32)
VALIDATION_GENERATOR = generator(VALIDATION_SAMPLES, batch_size=32)
# 输入帧的参数
ROW, COL, CH = 160, 320, 3
# Model
MODEL = Sequential()
# 执行图像归一化
MODEL.add(Lambda(lambda x: x / 127.5 - 1.0, input_shape=(ROW, COL, CH)))
# 剪裁图片 只保留和道路相关的部分
#MODEL.add(Cropping2D(cropping=((60, 20), (0, 0))))
# 利用卷积层来进行特征提取
MODEL.add(Conv2D(24, 5, strides=(2, 2), activation='relu'))
MODEL.add(Dropout(0.7))
MODEL.add(Conv2D(36, 5, strides=(2, 2), activation='relu'))
MODEL.add(Conv2D(48, 5, strides=(2, 2), activation='relu'))
MODEL.add(Conv2D(64, 3, activation='relu'))
MODEL.add(Conv2D(64, 3, activation='relu'))
# 如果出现过拟合可以添加Dropout
# MODEL.add(Dropout(0.8))
# 全链接层
MODEL.add(Flatten())
MODEL.add(Dense(100))
MODEL.add(Dense(50))
MODEL.add(Dense(10))
MODEL.add(Dense(1))
MODEL.compile(loss='mse', optimizer='adam')
MODEL.fit_generator(TRAIN_GENERATOR,
steps_per_epoch=len(TRAIN_SAMPLES),
validation_data=VALIDATION_GENERATOR,
validation_steps=len(VALIDATION_SAMPLES),
epochs=3)
# 保存模型
MODEL.save('model.h5')
</p>
然后汽车可以启动:
提高训练效果的小技巧:
使用模拟器生成数据时,尽量使用摇杆或鼠标,这样数据比较流畅,尽量将车保持在车道中间,如果驾驶技术不好就慢慢开。注意opencv读取图片颜色顺序为BGR。这是一个大坑。在训练开始时,它总是在水中打开。后来发现,颜色反了。

