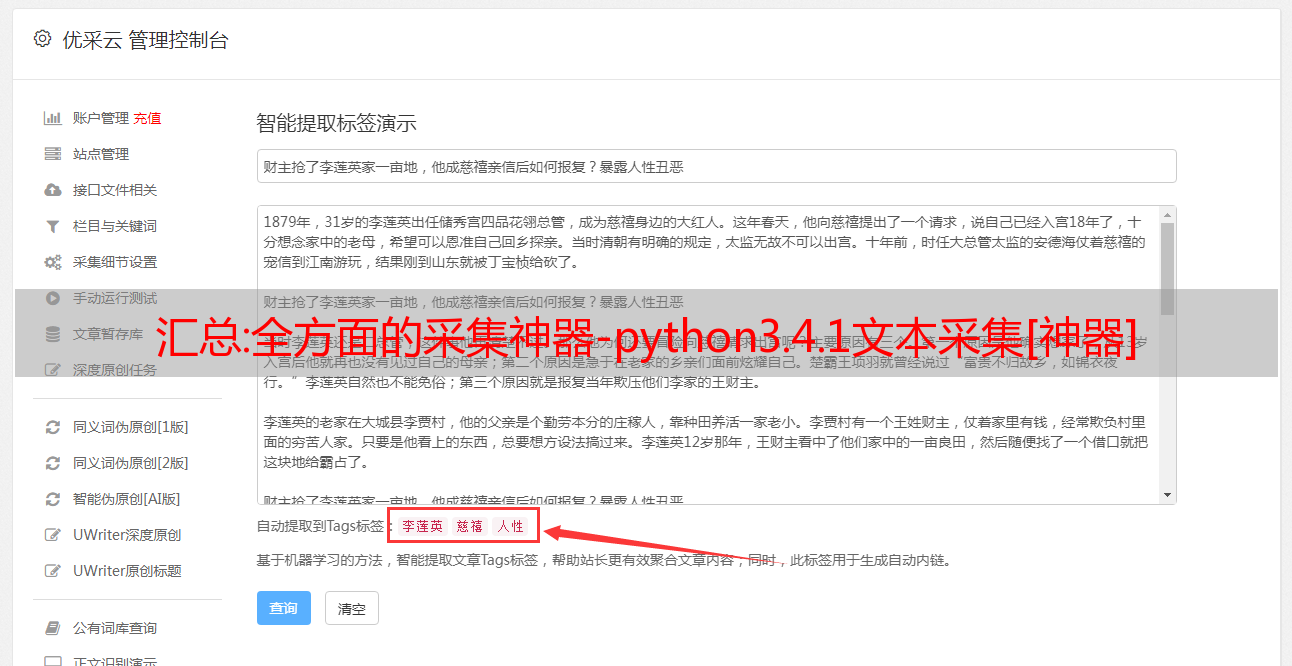
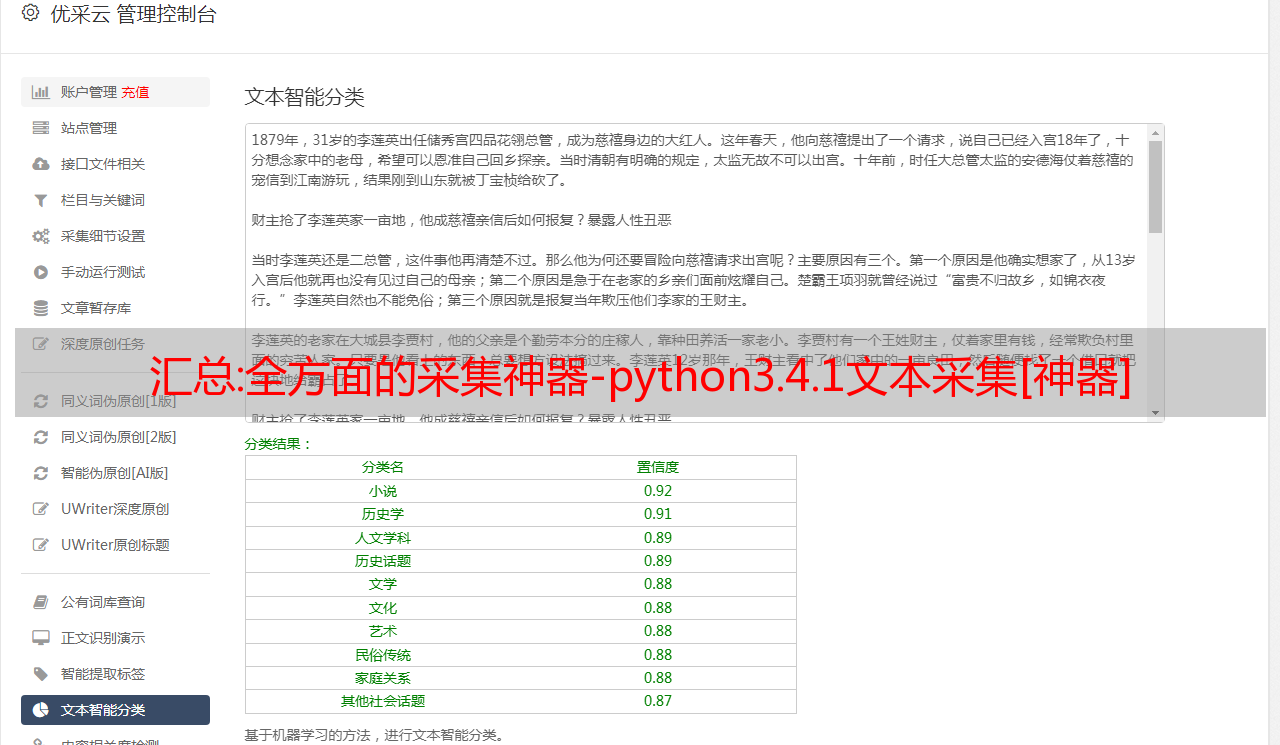
汇总:全方面的采集神器-python3.4.1文本采集[神器]
优采云 发布时间: 2022-11-06 03:09汇总:全方面的采集神器-python3.4.1文本采集[神器]
全方面的采集神器-python3.4.1文本采集[神器]python3.4.1汉字图片采集神器[神器]python3.4.1图片采集[神器]python3.4.1文本采集-xunjie-fen-yan/#dist/book/3_4/2017072002.pdf
用xpath编码,sublime之类打开,用sublime的edit-source编码最高就是python内置的xpath吧,不会有太大问题,就是没法写前端代码。之前做文本识别写过python内置xpath,结果发现返回的xpath很可能是乱码。
如果这个html里面包含了很多的数据,比如百度的点击记录,txt文件里的字符串,notebook里面记录的各种邮件地址等等等等那...你会崩溃的
编码工具,
xpath很难只要字符打开xpath比较有优势直接看看网页结构好了
如果你是想用python做数据分析或者展示图片数据,可以去看我的csdn博客ahasankou的教程,里面大致就是用python做爬虫的,其实有类似的前端框架做的很好,比如pyspider。
推荐一个python写的网页解析库xpaths-windows、linux、mac三平台的python包解析器。输入网址,解析就行了,想爬哪个页面就哪个页面。没有什么多余的逻辑,能返回一个列表就行。

