诀窍:干货 | 四两拨千斤,2步学会关键词策略,让你的Google Ads更高效
优采云 发布时间: 2022-11-04 08:48诀窍:干货 | 四两拨千斤,2步学会关键词策略,让你的Google Ads更高效
很多人都是从搜索广告开始做谷歌广告的,但是这种广告模式很容易花大价钱换来少量的询盘。
原因是搜索广告需要关键词进行精准定位,不同的关键词和匹配方式产生的*敏*感*词*用和查询量有很大差异。有些词每天点击量很少,但能带来非常可观的查询,而有些词点击量很大,但查询量很少。
关键词就像广告中的指标一样,我们需要找到投资回报率最高的指标来提供我们需要的结果。
01 关键词
首先我们要明白Google Ads的关键词和SEO的关键词的选择是不一样的。SEO 正在寻找有可能获得与您的产品或服务相关的尽可能多的流量的词。但做广告需要真金白银,注重投资回报。SEO可以使用与购买意向无关的词,但谷歌广告对关键词极为挑剔。
我们可以将 关键词 搜索意图分为三类:信息性、导航性和事务性。信息型关键词是不知道某件事,想获取信息,比如是什么,怎么做等。导航类型关键词是知道某事,想获取链接,比如华为store, Nike 等。Transactional关键词是用户考虑购买的关键词,比如价格、批发等。
我们需要找到的是交易类型关键词,也就是能够产生查询和订单高转化的词汇。我们不妨根据企业客户和个人客户将关键词分为B端词汇和C端词汇。
常用的B端交易类型关键词包括:product+manufacturer、supplier、批发商、factory和bulk等。以下是B端常用词,供大家参考:
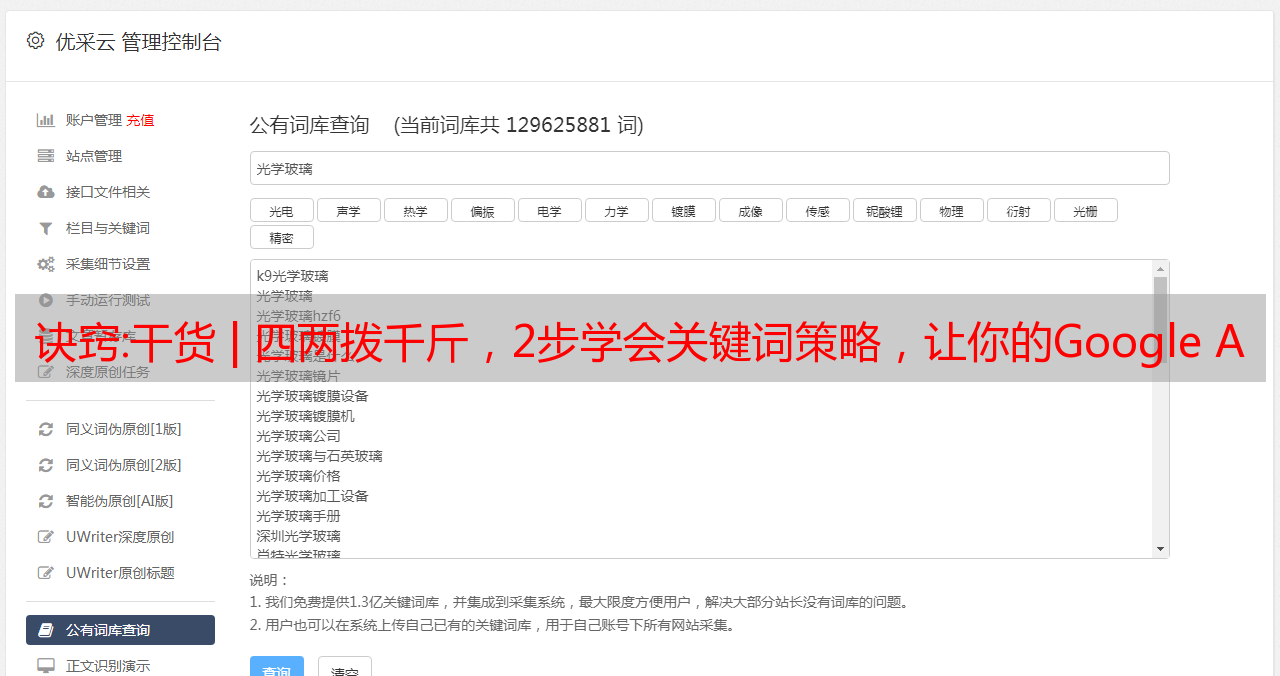
常用的C端词有:product+buy、forsale、cost、shop、store和price等。这里推荐几款关键词的谷歌搜索工具,帮助我们找到高转化词。
1.关键词规划师
使用我们的研究工具选择正确的关键字 - Google Ads
中文名称为关键词Planner,是谷歌官方的关键词规划工具。在搜索栏中输入与您的产品和服务相关的词。您可以使用逗号和空格分隔多个短语。选择语言和国家以获取估计数据。
如下图所示,我们可以获取关键字的历史数据和搜索量数据,并根据出价和预算为您的关键词列表提供性能预测。当列出 10-20 个 关键词 组时,单击左上角的“预测”按钮将显示潜在 关键词 的估计数据。
2. 赛姆拉什
Semrush是最全面的付费工具,我们可以使用这个工具中的Keywordmagic工具功能来过滤需要的Google关键词。另外,点击收录关键字,每行输入长尾词过滤关键词。
3.珍岛T云外贸版
锦道T云外贸版还内置了AI Box模块和广告投放模块。AI BOX模块的关键词规划工具,可以帮助用户精准、智能的扩词。在精准分词页面,用户只要在系统中输入产品本身的名称,系统就会给出相关的关键词,并在搜索流量、CPC、竞争等方面提供详细数据供参考和其他方面。
如果对结果不满意,可以切换到智能扩展页面。输入主词后,用户可以在前缀和后缀中选择想要的扩展方向,如制造商类别、销售类别、价格类别、产品特征类别等。
选择要放置的关键词后,也可以直接放置在T云外贸版后台,对放置效果进行多维度的审核分析。
4.谷歌搜索引擎联想词
当使用 Google 搜索引擎搜索单个 关键词 时,最直接的关联将出现在下拉列表中。
在搜索关键词时,你会遇到很多相关的词和同义词。这里有一个小技巧供大家参考判断关键词是否与产品相关:将确定的关键词输入Googleimage如果Googleimage页面搜索结果的第一页收录80%以上的相关产品,这意味着这个 关键词 与产品相关。
02 关键词 匹配模式
关键词 是用于将广告与用户搜索相关联的词或短语,关键词 匹配类型决定了 关键词 与用户搜索查询的匹配程度。使系统考虑在拍卖中放置广告。
如果您选择了 关键词,但使用了错误的 关键词 匹配类型,则很容易导致 Google Ads 的投资回报率降低。例如,如果你卖男鞋,你会在后台拿出 10 个与鞋子相关的词组,例如 blue man shoes,并将它们设置为精确匹配模式。在这种模式下,谷歌必须找到你精确设置的这些奇怪的关键词搜索客户,才能为你的网站带来流量,这不仅会导致少数人满足你的搜索需求, 单价也会很高。
因此,我们必须了解各种匹配模式的机制和适用场景。
1. 广泛匹配
广泛匹配意味着只要用户搜索关键词和你的广告关键词,即使只有轻微的联系,你的广告就会被展示。
它最大的优点是会给我们的网站带来非常大的流量,但是流量不准确,投资回报率低。比如你还是卖男鞋,搜索女鞋或男装的用户可能会看到你的广告,除非你有足够的资金,否则会造成相当大的浪费。
2.广泛匹配修饰符
广泛匹配修饰符是仅针对收录修饰符的字词(或变体,以任意顺序)展示广告。
例如,如果您的广泛匹配修饰符 关键词+men+shoes,将触发广告展示的搜索是:男鞋、男鞋、黑色男鞋等,但不包括女鞋和男装。因此,与广义匹配相比,它兼顾了准确性和可扩展性,是最常用的匹配模式。
3.短语匹配
词组匹配比广泛匹配修饰符更精确,只能根据特定词组展示广告。
例如,如果您的词组匹配 关键词 是“男鞋”,则会触发针对黑人男鞋和耐克男鞋的广告搜索,但不会出现男鞋耐克男鞋和男鞋。
4. 精确匹配
输入的 关键词 完全匹配,不会显示任何 关键词 变体的广告,是最精确的匹配模式。
这种模式流量很少,但也不是一文不值。通过长尾关键词的精确匹配,我们可以准确找到我们需要的潜在客户。
5. 否定 关键词
Negative 关键词 表示只要用户搜索我们设置的否定词,广告就不会展示。常用于拒绝一些非目标用户。
以上就是优化Google Ads搜索广告关键词的具体方法。Google Ads 中有许多不同类型的广告。如何选择合适的广告类型,怎么做也是一门学问。进道一直致力于赋能外贸企业营销能力,打造全球领先的营销云平台。未来,我们还将带来更多优质的营销干货内容。
技巧:三、分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
一、背景资料
ShardingSphere提供了多种内置的分片算法,根据类型可分为自动分片算法、标准分片算法、复合分片算法和Hint分片算法,可以满足用户大部分业务场景的需求。此外,考虑到业务场景的复杂性,内置算法还提供了自定义分片算法的方式,用户可以通过编写Java代码来完成复杂的分片逻辑。
二、配置文件一、参数说明
rules:
- !SHARDING
tables: # 数据分片规则配置
(+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: # 分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键*敏*感*词*
keyGeneratorName: # 分布式序列算法名称
auditStrategy: # 分片审计策略
auditorNames: # 分片审计算法名称
-
-
allowHintDisable: true # 是否禁用分片审计hint
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
-
-
broadcastTables (+): # 广播表规则列表
-
-
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
# 分片算法配置
shardingAlgorithms:
(+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
(+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
# 分片审计算法配置
auditors:
(+): # 分片审计算法名称
type: # 分片审计算法类型
props: # 分片审计算法属性配置
# ...
2.配置示例
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t-order-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
auditStrategy:
auditorNames:
- sharding_key_required_auditor
allowHintDisable: true
t_order_item:
<p>
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order-item-inline
keyGenerateStrategy:
column: order_item_id
keyGeneratorName: snowflake
t_account:
actualDataNodes: ds_${0..1}.t_account_${0..1}
tableStrategy:
standard:
shardingAlgorithmName: t-account-inline
keyGenerateStrategy:
column: account_id
keyGeneratorName: snowflake
defaultShardingColumn: account_id
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_address
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database-inline
defaultTableStrategy:
none:
shardingAlgorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t-order-inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order-item-inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
t-account-inline:
type: INLINE
props:
algorithm-expression: t_account_${account_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
auditors:
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
props:
sql-show: false
</p>
3、分片策略,默认是指使用默认的分片策略。只能选择以下分片策略之一。1.标准
单个分片键的标准分片方案
2. 复杂
多个分片键的复合分片场景
3.提示
提示分片策略
4.没有
没有分片
3. 分表策略 1. 模分片算法(MOD)
#------------------------基本配置
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#------------------------数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=server-order2,server-order0,server-order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://192.168.159.103:3307/test1
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=xxxx
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://192.168.159.103:3308/test2
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=xxxx
# 配置第 3 个数据源
spring.shardingsphere.datasource.server-order2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order2.jdbc-url=jdbc:mysql://192.168.159.103:3309/test3
spring.shardingsphere.datasource.server-order2.username=root
spring.shardingsphere.datasource.server-order2.password=xxxx
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..2}.t_order
#------------------------分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
<p>
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=3
#
## 哈希取模分片算法
## 分片算法类型
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
## 分片算法属性配置
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#
##------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
#------------------------分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 分布式序列算法属性配置
#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx=
</p>
2.基于CosId(COSID_MOD)的模分片算法
#------------------------基本配置
# 应用名称
spring.application.name=sharging-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 打印SQl
spring.shardingsphere.props.sql-show=true
#------------------------数据源配置
# 配置真实数据源
spring.shardingsphere.datasource.names=server-order1,server-order2,server-order0
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://192.168.159.103:3307/test1
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=xxxx
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://192.168.159.103:3308/test2
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=xxxx
# 配置第 3 个数据源
spring.shardingsphere.datasource.server-order2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.server-order2.jdbc-url=jdbc:mysql://192.168.159.103:3309/test3
spring.shardingsphere.datasource.server-order2.username=root
spring.shardingsphere.datasource.server-order2.password=xxxx
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..2}.t_order
#------------------------分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
# 分片列名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
# 取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=COSID_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.mod=3
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.logic-name-prefix=server-order
#
## 哈希取模分片算法
## 分片算法类型
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
## 分片算法属性配置
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#
##------------------------分布式序列策略配置
# 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
#------------------------分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
3. 哈希模分片算法(HASH_MOD) 4. 基于分片容量的范围分片算法(VOLUME_RANGE) 5. 基于分片边界的范围分片算法(BOUNDARY_RANGE) 6. 自动时间段分片算法(AUTO_INTERVAL)) 3. 标准分片算法
Apache ShardingSphere 内置的标准分片算法实现类包括
1.行表达式分片算法() 2.时间范围分片算法 3.基于CosId的固定时间范围分片算法 4.基于CosId的Snowflake ID固定时间范围分片算法 4.复合分片算法 1、复合行表达式分片算法(COMPLEX_INLINE ) 5.Hint 切片算法1、Hint 行表达式切片算法(HINT_INLINE) 6.自定义类切片算法1、自定义切片算法(CLASS_BASED)

