干货教程:Python 数据采集-爬取学校官网新闻标题与链接(进阶)
优采云 发布时间: 2022-11-04 05:25干货教程:Python 数据采集-爬取学校官网新闻标题与链接(进阶)
Python爬虫爬取学校官网新闻头条和链接(进阶)
前言
⭐ 本文以学校课程内容为准。抓取的数据仅供学习使用,请勿用于其他目的
环境要求:安装扩展库BeautifulSoup、urllib(⭐这里不会安装Python下载安装第三方库)基础知识:1.拼接路径
在上一篇文章中,我们获取的网页链接是网页的相对路径,并不是可以立即使用的链接,如下图:
我们常用的链接如下:
这种链接是可以立即使用的链接,那么上面的链接可以换成可以立即使用的形式吗?我们需要使用 urllib 库的 urljoin() 来拼接地址。urljoin()的第一个参数是基础父站点的url,第二个是需要拼接成绝对路径的url。使用urljoin,我们可以将之前爬取的url的相对路径拼接成绝对路径。
首先我们要知道之前爬取的url的基本父站点是谁?很简单,通过对比新闻的链接和我们爬取的链接就可以知道基本的父站,如下图,基本的父站是https:::
二是要知道需要拼接成绝对路径的url,也就是我们之前爬取的url
两个参数都可用后,我们就可以使用urljoin()来拼接路径了,如下:
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取给定 url 的 html 代码
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
content = response.read().decode('utf-8')
# 转换读取到的 html 文档
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
# 获取转换后的 html 文档里属性 class=list-main-warp 的 div 标签的内容
divs = soup.find_all('div', {'class': "list-main-warp"})
# 从已获取的 div 标签的内容里获取 li 标签的内容
lis = divs[0].find_all('li')
# 遍历获取到的 lis 列表,并从中抓取链接和标题
for li in lis:
url1 = "https://www.hist.edu.cn/" # 基础母站
# 需要拼接成绝对路径的 url,也就是我们之前爬取到的 url(相对路径形式)
url2 = li.find_all('a')[0].get("href")
# 使用 urllib 的 urljoin() 拼接两个地址
# urljoin 的第一个参数是基础母站的 url, 第二个是需要拼接成绝对路径的 url
# 利用 urljoin,我们可以将爬取的 url 的相对路径拼接成绝对路径
url = urljoin(url1, url2)
# 我们爬取到的新闻标题
title = li.find_all('a')[0].get("title")
# 打印拼接的路径和对应的新闻标题
print(url)
print(title)
输出如下(仅截取部分):
可以看出我们之前爬取的链接的相对路径已经通过urljoin()与基本父站点拼接成绝对路径,此时的链接可以立即使用
2.存储
我们之前已经获得了新闻的链接和标题。接下来,我们希望存储爬取的数据。例如,每条新闻的链接和对应的标题用逗号分隔,并存储在一个txt文件中。txt 文件命名为 urlList.txt。
已经熟悉Python文件操作的同学肯定会说“我熟悉这波操作”。确实,要完成我们想要的功能,我们只需要掌握文件写入的知识。
不算太难,直接放代码就行了,注释比较详细。如果您有任何问题,可以在评论中提出。
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取给定 url 的 html 代码
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
content = response.read().decode('utf-8')
# 转换读取到的 html 文档
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
# 获取转换后的 html 文档里属性 class=list-main-warp 的 div 标签的内容
divs = soup.find_all('div', {'class': "list-main-warp"})
# 从已获取的 div 标签的内容里获取 li 标签的内容
lis = divs[0].find_all('li')
# 向 urlList.txt 文件写入内容
with open('urlList.txt', 'w', encoding='utf8') as fp:
# 遍历获取到的 lis 列表,并从中抓取链接和标题
for li in lis:
url1 = "https://www.hist.edu.cn/"
url2 = li.find_all('a')[0].get("href")
# 使用urllib的urljoin()拼接两个地址
# urljoin的第一个参数是基础母站的url, 第二个是需要拼接成绝对路径的url
# 利用urljoin,我们可以将爬取的url的相对路径拼接成绝对路径
<p>
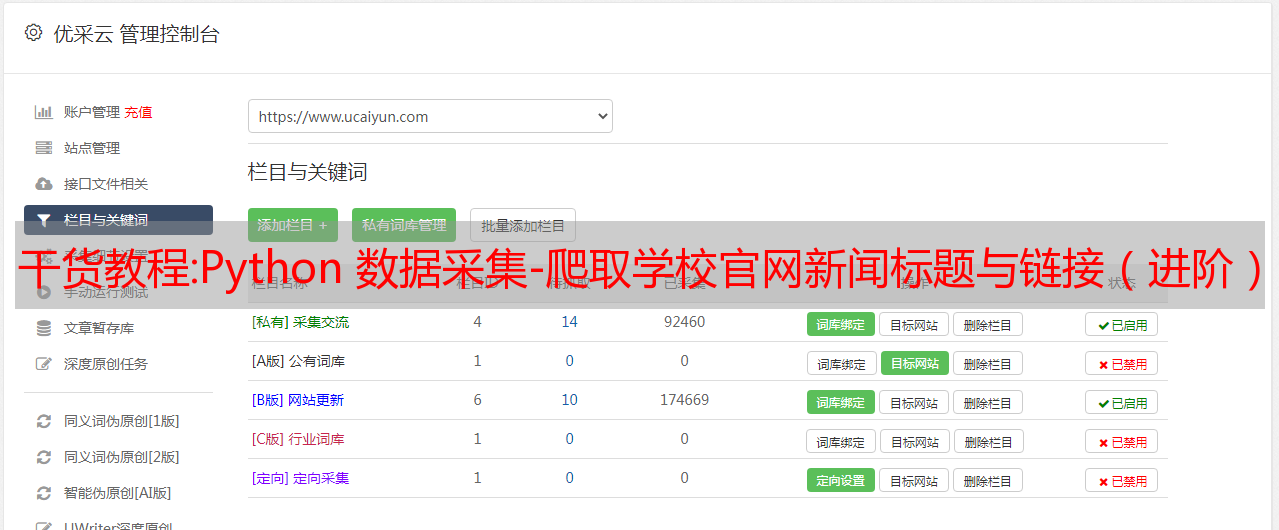
url = urljoin(url1, url2)
title = li.find_all('a')[0].get("title")
# 写入新闻链接和标题,并以逗号分隔
fp.write(url + "," + title + '\n')
</p>
3.读取翻页数据
根据我们爬取的数据,我们只能爬取到当前页面的数据,但是还有不止一页的学校新闻。我们要爬取第二页,第三页,……等所有页面的数据并存储。,如何实现呢?很明显,我们可以爬到一页数据,但是不能爬到下一页数据,因为我们无法实现爬虫的翻页。如果能实现翻页,那么下一页就可以看成是当前页,我们已经爬取了当前页的数据,所以现在的问题是解决如何翻页。
我们做的爬虫是模拟浏览器获取数据,而翻页行为是我们手动点击下一页,然后浏览器跳转到下一页,所以需要让爬虫模拟我们手动手动点击下一页是一种行为,允许浏览器跳转到下一页,然后点击下一页直到最后一页,这样就可以翻转所有页面。
接下来我们调试网页,观察我们点击下一页按钮后浏览器是如何跳转到下一页的,如下:
观察下图可以看到:
然后我们点击下一页,跳转到下一页继续观察(爬虫的过程就是我们需要多观察差异,以便将这些差异作为我们代码实现的条件),如下:
观察显示:
根据上面调试网页的观察,我们希望爬虫实现翻页的一个思路是:
① 从获取的第一页的html代码中过滤tag属性为class="Next"的a标签,然后获取下一页和最后一页的href链接。
② 使用while循环翻页。循环结束的条件是下一页的herf链接等于最后一页的herf链接。在循环体中,
爬取当前页面的新闻头条和链接,然后判断是否是第一次循环,根据判断结果确定拼接的基本主站路径,然后根据我们拼接的跳转到下一页路径,并重复直到循环结束,我们可以得到所有页面的新闻标题和链接
代码实现如下:
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取URL的HTML代码,输入 URL,输出 html
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
# print(response.read().decode('utf-8'))
content = response.read().decode('utf-8')
# 解析
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
endPage = Pages[1].get("href")
# print(endPage)
# 用来判断第一次的基础母站路径
i = 1
while Pages[0].get("href") != Pages[1].get("href"):
# while 循环之外我们已经读取到了首页的新闻内容,直接开始分析
divs = soup.find_all('div', {'class': "list-main-warp"})
lis = divs[0].find_all('li')
# 开始写入
# 需要注意,写入的方式是追加 'a+'
# 因为每读一页都会向文件中写入一次,如果还使用之前的 w 写入方式,
# 就会导致上一页的内容被当前页的内容覆盖,这样最后,文件里就被覆盖的只有最后一页的新闻标题与链接
with open('urlList.txt', 'a+', encoding='utf8') as fp:
for li in lis:
url1 = "https://www.hist.edu.cn/"
url2 = li.find_all('a')[0].get("href")
# 使用urllib的urljoin()拼接两个地址
# urljoin的第一个参数是基础母站的url, 第二个是需要拼接成绝对路径的url
# 利用urljoin,我们可以将爬取的url的相对路径拼接成绝对路径
url = urljoin(url1, url2)
title = li.find_all('a')[0].get("title")
fp.write(url + "," + title + '\n')
# 判断是否是第一次跳转下一页
if i == 1:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/"
i = i+1
else:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/kyyw/"
# 获取下一页链接
url2 = Pages[0].get("href")
# 拼接路径
url = urljoin(url1, url2)
# 用于提示爬到哪一页了
print(url)
# 读取下一页的内容
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
<p>
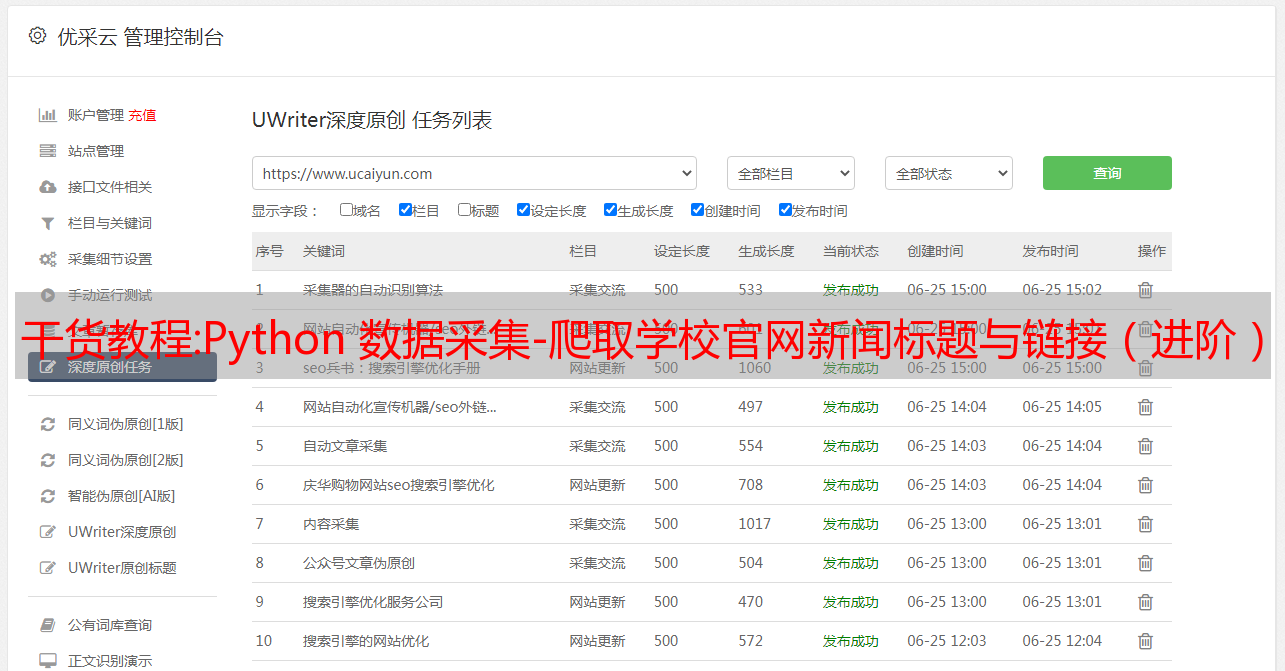
# 解析下一页的内容,同时将soup指向为下一页的内容
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
</p>
输出如下:
四、完整代码展示
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 读取URL的HTML代码,输入 URL,输出 html
response = urllib.request.urlopen('https://www.hist.edu.cn/index/sy/kyyw.htm')
# print(response.read().decode('utf-8'))
content = response.read().decode('utf-8')
# 解析
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
endPage = Pages[1].get("href")
# print(endPage)
# 用来判断第一次的基础母站路径
i = 1
while Pages[0].get("href") != Pages[1].get("href"):
# while 循环之外我们已经读取到了首页的新闻内容,直接开始分析
divs = soup.find_all('div', {'class': "list-main-warp"})
lis = divs[0].find_all('li')
# 开始写入
# 需要注意,写入的方式是追加 'a+'
# 因为每读一页都会向文件中写入一次,如果还使用之前的 w 写入方式,
# 就会导致上一页的内容被当前页的内容覆盖,这样最后,文件里就被覆盖的只有最后一页的新闻标题与链接
with open('urlList.txt', 'a+', encoding='utf8') as fp:
for li in lis:
url1 = "https://www.hist.edu.cn/"
url2 = li.find_all('a')[0].get("href")
# 使用urllib的urljoin()拼接两个地址
# urljoin的第一个参数是基础母站的url, 第二个是需要拼接成绝对路径的url
# 利用urljoin,我们可以将爬取的url的相对路径拼接成绝对路径
url = urljoin(url1, url2)
title = li.find_all('a')[0].get("title")
fp.write(url + "," + title + '\n')
# 判断是否是第一次跳转下一页
if i == 1:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/"
i = i+1
else:
# 设置基础母站路径
url1 = "https://www.hist.edu.cn/index/sy/kyyw/"
# 获取下一页链接
url2 = Pages[0].get("href")
# 拼接路径
url = urljoin(url1, url2)
# 用于提示爬到哪一页了
print(url)
# 读取下一页的内容
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
# 解析下一页的内容,同时将soup指向为下一页的内容
soup = BeautifulSoup(content, 'html.parser', from_encoding='utf-8')
Pages = soup.find_all('a', {'class': "Next"})
五、总结
你必须再听我一次。哈哈哈,开始就这么远……
至此,我们已经完成了一些相对于上一篇文章文章更高级的功能。首先,我们通过urljoin()拼接路径,其次,我们使用Python文件写入来抓取我们抓取的新闻。链接和标题存储在txt文件中,最后我们实现读取翻页数据,得到所有的新闻链接和标题。我爬了我们学校的新闻,你们也可以试试你们学校,原理都是一样的!
值得一提的是,这两篇文章的文章看完之后,我们基本可以大致了解一下什么是爬虫了。很容易上手。学校新闻网站是一个静态网页,而且一切,我们都可以看到代码,所以调试网页或者爬取数据会简单很多,但是还是有很多网页是动态的网页,以及一些我们看不到的数据。? 有兴趣的可以关注波拉后续动态网页抓取的文章!
但是在这之前,Pola 会发一个词频分析文章,你有没有发现我们只是把新闻头条和链接刮下来存储起来,其实并没有多大用处?你见过年度关键词、网络热词排行榜等词云图吗?我们可以利用爬取的新闻标题和链接获取新闻内容,对所有新闻内容进行分析,找出最常被提及的词,也就是简单的词频分析!根据分析结果,还可以制作词云图!
写在最后,如果您有任何疑问和不理解或者代码调试有问题,请在下方评论文章,Pola 将与您一起解决!
干货内容:网络营销如何获取精准流量?精准流量获取实操
目前,代理网络营销的企业有很多。最近,几个这样的组织的老板通过公众号找到了我。他们都开始在我的公众号上学干货,学到了很多网络营销的高级方法,但是现在这个行业竞争太激烈了。其中之一是进行机械操作。他选择付费渠道,流量成本太高,所以这次他们一起来找我,想知道如何获得精准流量的一些技巧。
如何获得准确的流量是大多数营销人员关注的焦点。虽然我们算是半同行,但既然是通过公众号找到我的,我也不会拒绝。毕竟多交流也是好事。大多数人过于关注付费渠道,也就是百度竞价广告。我之前也负责网络营销。核心是要能玩关键词,但是内容制作对他们来说太难了,更别说获取精准流量了。
今天就以文字的形式跟大家分享之前和他们讨论过的如何获取精准流量的技巧和实践。
如何在网络营销中获得准确的流量
SEO网站关键词布局
关键词的正确选择决定了网站的流量大小,网站的布局和优化直接影响网站是否出现在搜索引擎上并取得好的排名,SEO关键词布局对于获得准确的流量至关重要。关键词布局包括:
关键词选择
关键词密度
站群关键词布局
关键词选择
没有被百度收录列出的关键词是没有意义的。即使排名很好,获得准确流量的机会也很小。
具体操作可以选择你的主要关键词之一,然后在“百度指数”上搜索,选择百度的收录的关键词,然后选择“需求图”,以下是会出现大量与关键词和与收录相关的关键词,然后按照大搜索、业务相关、小搜索的原则选择关键词竞赛
如果没有与产品词关键词相关的收录,也可以选择行业词进行优化
关键词密度
如果要使用某个关键词获取精准流量,关键词必须出现在网站上,密度在2%-8%之间,常规网站 优化 保持在 5%
也可以将seo网站的链接放到“站长工具”中,查看网站关键词的密度是否满足条件
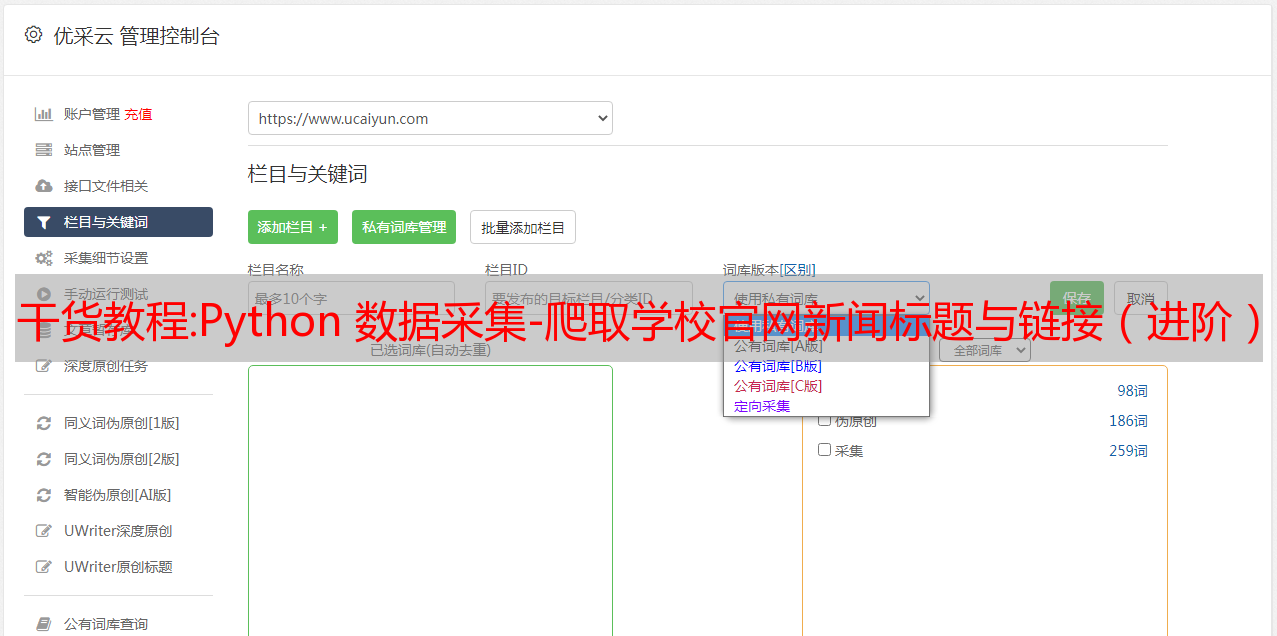
网站首页的关键词设置品牌词不得超过5个,一般遵循三个核心业务词+一个品牌词的原则
站群关键词布局
顾名思义,很多网站同时在做SEO,目的是为了能够起到霸屏的效果,从而获得精准的流量
一般情况下,单个业务会采用1个官网+2-3个站的形式
官网主要是品牌词和所有业务关键词,其他不同的业务站由博客站、专页、小官网三个站组成,可用于其他业务词
SEO伪原创文章写作技巧
内容决定排名,伪原创文章是影响网站排名的重要因素
内容伪原创
伪原创 的前提是了解采集 材料。采集材质分为手动采集和自动采集两种。引擎、自媒体平台、竞争对手网站采集优质内容,然后进行伪原创
自动采集就是利用文章采集工具输出关键词自动生成原创文章
这里提醒一下,这个文章采集工具适用于需要大量发布文章的门户网站或网站
内容伪原创一定要注意关键词的布局,内容是原创可以统一下两种方式
01.将几篇文章合二为一,找几篇大致相同的文章,合并成一篇文章考虑,记得自己写第一段和最后一段
02.颠倒顺序,删除或添加内容,修改头尾
标题伪原创
标题伪原创可以遵循数值修改法和等值代换法
数值修饰:简单来说,数值修饰就是通过增加或减少标题中的值来达到修饰的目的。比如“九种SPAM详解”可以改成“六种SPAM介绍”,然后文章中的三种SPAM介绍可以合并到其他介绍中或删除。
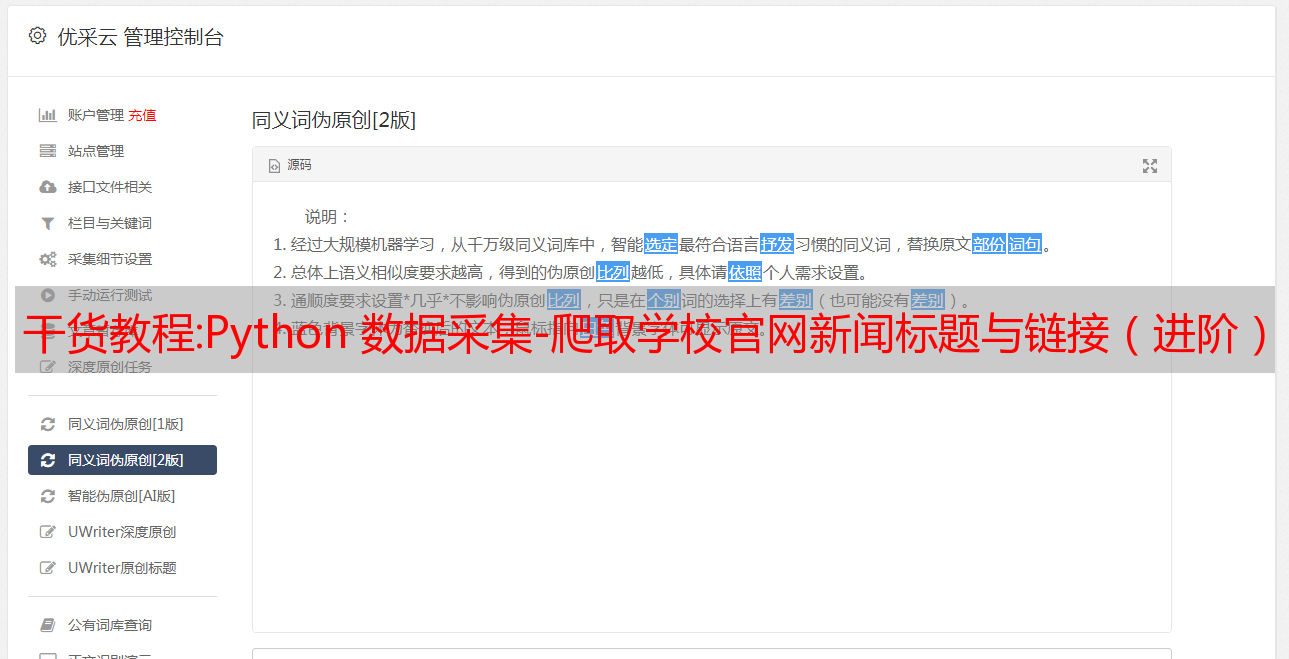
等效替换:等效替换是指通过使用同义词或打乱标题关键字的顺序来修改标题。比如“SEO技巧——减少页面相似度的六种方法”可以修改为“减少页面相似度的六种SEO技巧”
问答平台获取精准流量
我们现在熟悉的问答平台包括百度知道、百度体验、*敏*感*词*、知乎、悟空问答、搜狗问答、360问答、快搜问答、天涯问答等。
Q&A推广之所以被认可并被广泛使用,主要是因为精准的流量。一旦你的内容能够打动他,他就有可能成为你的忠实客户。
推广问答有两种方式:一是自问自答;另一种是回答别人的问题。
回答别人的问题就不用多说了。为了客观地回答别人的问题,我将详细解释自问自答的推广形式。自问自答必须由多个账号进行。
规划问题的内容
该描述收录至少一个要优化的关键词。问题描述一定要用白话写,要真实客观,给用户更真实的感受
计划你的答案
内容要真实、客观、可信,就像真实网友的回答一样。尝试模拟不同的角色。如果条件允许,可以更换不同的ip答案,从不同角度回答问题,不要写太专业的术语,不要有太强的内容倾向
最后一点是内容必须收录优化的关键词,可以出现3次
百家号&小程序获取精准流量
小程序目前有百度支持,小程序排名甚至比SEO好网站
在百度搜索结果页面中,当智能小程序的某个页面被正常检索时,其显示形式与普通网页相同。用户可以在百度App中点击搜索结果打开智能小程序。建议公司做一个小程序矩阵,每个产品词都可以做一个小程序
百家号文章智能小程序挂载方式
进入小程序开发者后台-流量配置-选择“百家账号文章挂载”,按照流程指南要求绑定熊爪账号,即可将百家账号小程序引流。
流量对*敏*感*词*钱,流量决定企业的生命线。很多媒体和公司都搭建了自己的平台,开通了公众号矩阵,自己折腾了一个APP,试图建立自己的流量池,但实践后发现很难。因为再怎么折腾,也折腾不了微信、今日头条这样的大生态。与其没有目标的折腾,不如静下心来,系统地学习网络营销的实用技巧。因为如何获得精准流量是网络营销中渠道运营的必修课。
不要等到周围的人都超过了你,你才知道如何努力。你必须安静地工作,让每个人都惊叹不已。能力不是在某个年龄出现的。与其花费时间和精力,不如系统地学习。

