技巧:自动采集文章数量过多,先点击一下手动选择感兴趣的内容
优采云 发布时间: 2022-11-04 02:07技巧:自动采集文章数量过多,先点击一下手动选择感兴趣的内容
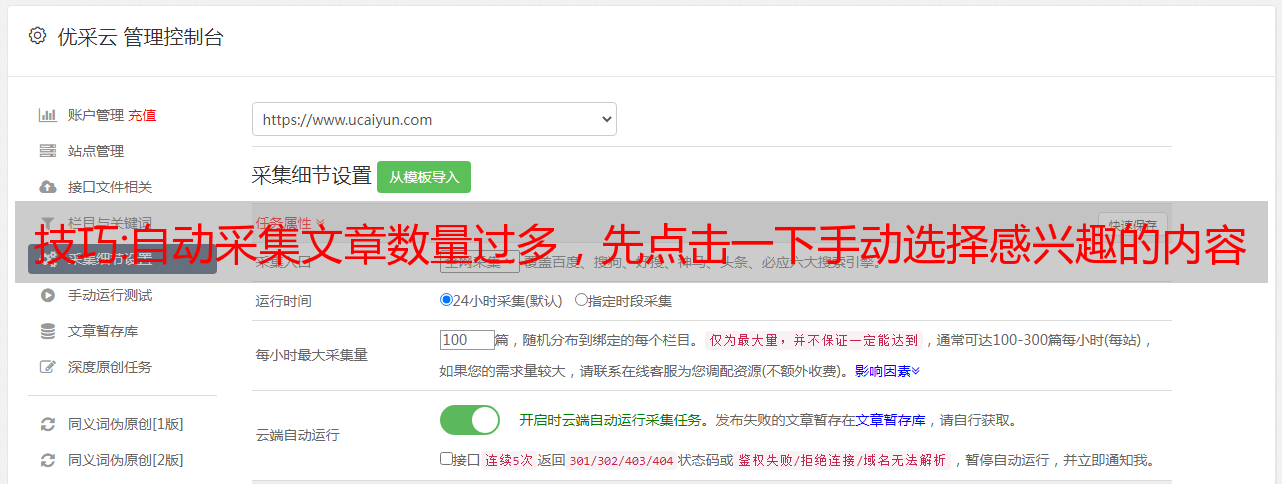
自动采集文章文章数量过多,先点击一下手动选择感兴趣的内容,再点击“自动采集”就可以啦。一般比例在1:10,首先我们需要先实现自动化采集,主要通过改变采集的规则来实现,比如对价格采集,我们选择价格段,那么当要采集价格段为199以下的时候,就需要选择199以下,但是实际情况,并不会这么宽泛,有的还包含200-399。
所以采集价格段的前提需要对采集的对象做一个标识,比如用“=”的规则来进行区分199-499的价格段。那么点击之后呢,就说明某段文章“已下载”,意思就是该段已经被采集完毕了,我们再调用程序,需要清空该段即可。自动发表文章自动发表文章,主要依靠去重功能。我们可以通过gitlab服务器每日自动扫描php.io这个版本库里面是否有更新的文章,如果有,那么gitlab就会将其提交至gitlab。
由于gitlab主要是一个高并发服务器,所以每日每秒可以生成500个请求,当你需要生成500个文章的时候,显然你的服务器会被承受不了的。因此我们要想办法为每一篇提交的php.io文章分配权重,让他们不被相同的一些文章覆盖。直接修改gitlab的配置,将所有的服务器地址变成gitlab.host.199.100这种,然后在请求里将gitlab.host.199.100.1这种地址替换为你gitlab的根路径就可以啦。
可以使用subprocess,fork和push,也可以创建一个采集脚本给其他脚本使用,这个语言也是自定义的。gitlab每日的新增文章数量也设定为500。自动搜索bugfix文章数量超过2万条的时候,就需要搜索文章的bug。这个时候,我们可以使用queryset来对文章进行匹配,queryset的工作原理,是以句法树的形式展示匹配的结果,我们可以通过代码计算一个最简单的匹配模型(递归+表达式匹配)来找到全部匹配的结果。
每一个匹配结果,在文章的左侧都会展示出来,然后再通过一个梯形图,一层一层的连起来。这个梯形图的具体规则,可以在源代码库找到这里可以看到每篇文章,并没有展示在结果里,因为这个方法没有做中间的过滤,他仅仅是根据相似度的大小来展示前后的匹配度,所以为了保证采集的相关性和准确性,queryset需要专门实现。
比如在实际工作中,我需要统计出文章的字数,这样就可以通过多个queryset的匹配统计所有结果,并根据字数,分配权重,权重比较高的,那么再提交进gitlab。如果你能完全解释清楚一个queryset的工作原理,那么这些都是不需要的。vue框架前端模块化开发vue框架的模块化,是其他一些框架都比较缺乏的。而且通过各种模块化实现起来比较方便,在写一些系统后台的时候,发现所有的。

