汇总:URL采集-如何通过关键词快速获取网址,网站信息?
优采云 发布时间: 2022-11-01 05:21如何通过关键词获取全网可访问的URL和网站信息
有时我们需要对我们的网站或产品进行市场分析,
这时候,我们需要获取大量数据进行对比。如果是手动获取的话,会耗费太多时间。
于是就有了Msray全网URL采集工具。
Msray的主要功能: 1:URL采集根据关键词
msray可以根据提供的关键词,通过搜索引擎对关键词的结果进行排序。
采集的内容包括:域名、网址、IP地址、IP国家、标题、描述、访问状态
2:根据URL采集网站信息
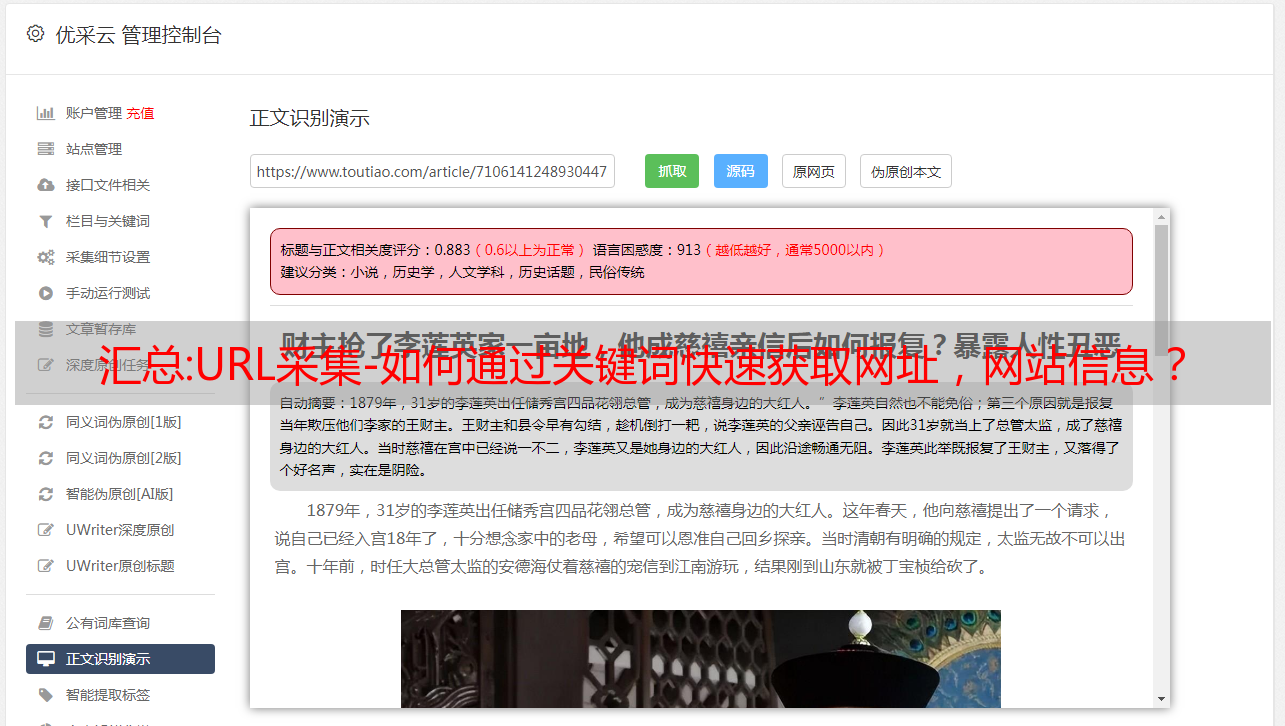
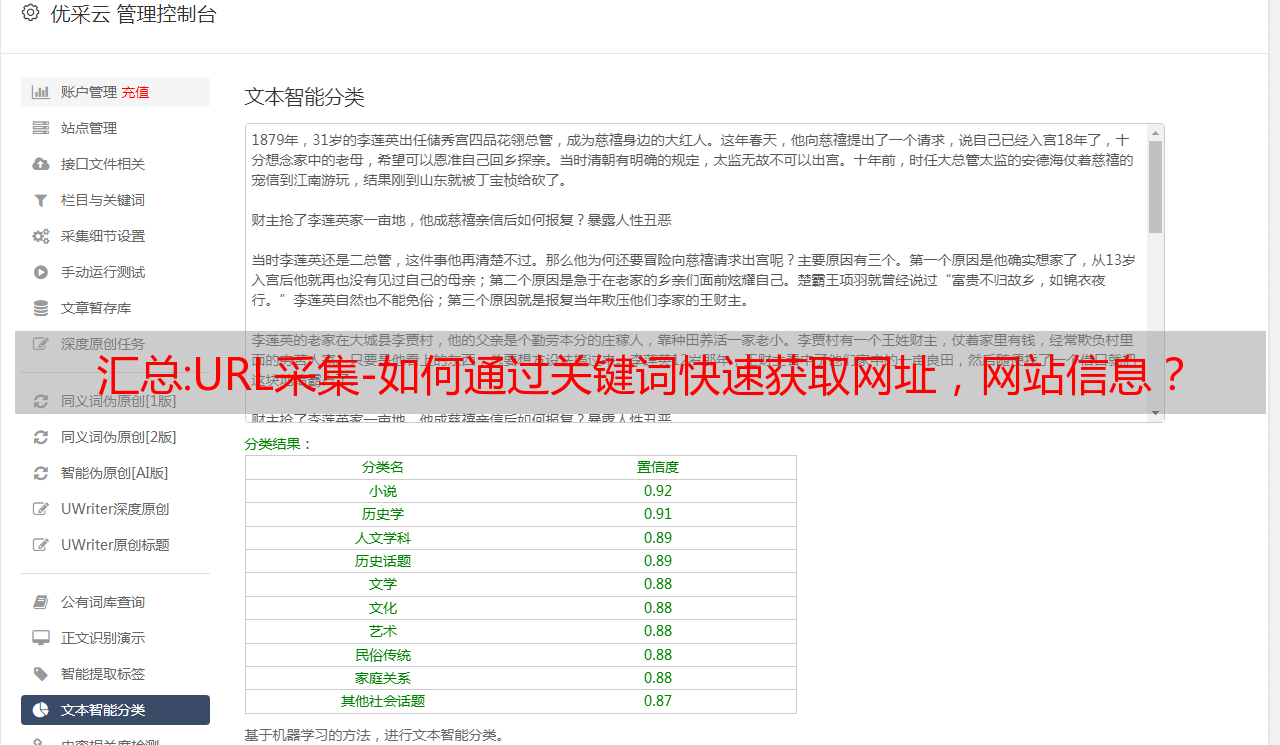
msray可以根据提供的url 关键词,采集已经是网站的收录内容
采集的内容包括:域名、网址、IP地址、IP国家、标题、描述、访问状态
3:*敏*感*词*根据url采集
msray 可以根据提供的 url采集 网页提供联系信息。
如何使用:
此示例通过 关键词 演示 采集
1:创建一个关键词采集任务
您可以根据自己的业务需求填写配置。
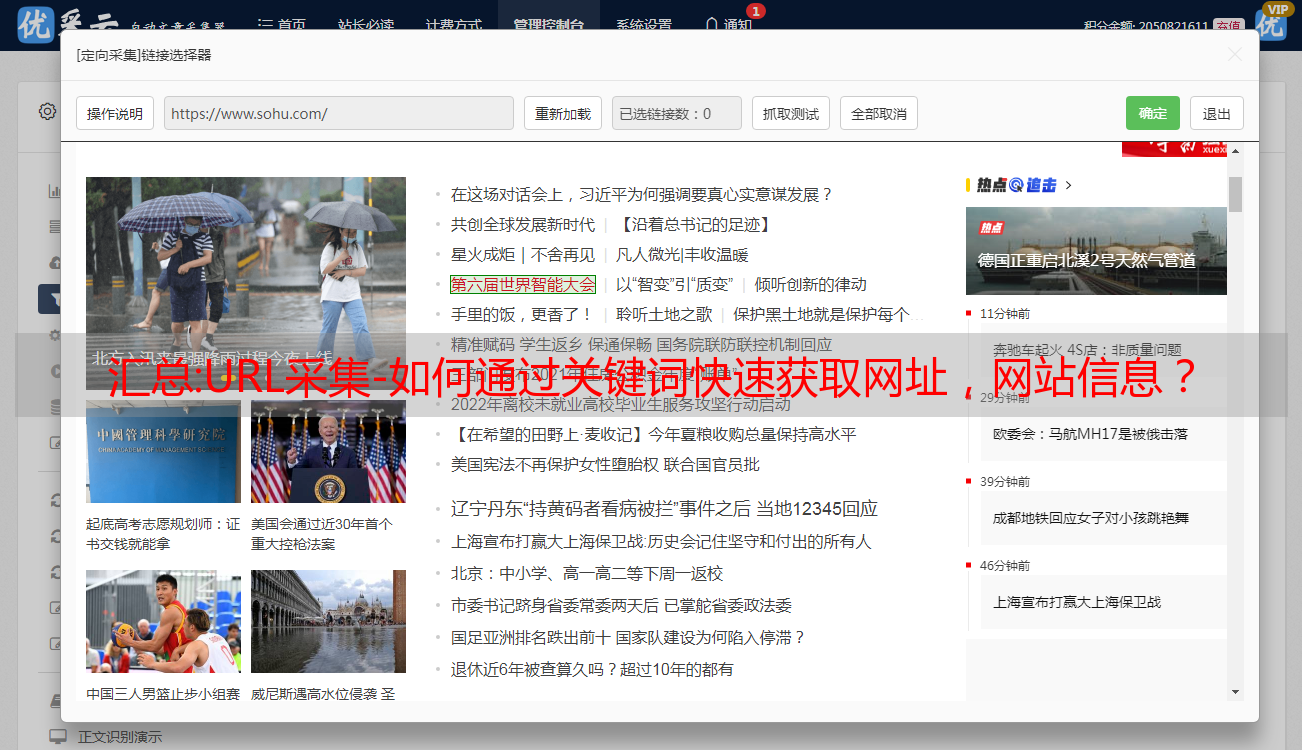
2:执行后预览结果。
msray 支持多种导出方式
同时还有消息推送,可以将采集收到的结果推送到目标系统进行统计分析,然后使用
使用 msray 可以帮助我们快速组织我们自己业务所需的数据。
msray官网:
在线文档:
获取免费版本:
技术文章:Python爬虫一步步抓取房产信息!
如上图所示,只要改变关键词后面的参数,就可以获得不同地区的二手房数据。编程时只需要手动编写一个收录每个区域的列表,然后通过循环改变关键字后面的参数,从而启动一个区域,然后爬取其中的链接。这种方法确实可行,而且深圳的区也不多。我已经尝试过这种方法并且它有效。
我真正想说的
上面的方法是可行的,但不是我要推荐的方法。当你回到主页时,搜索栏旁边有一张地图可以找到房间。点进去可以看到深圳全区的房子。如果你能在这里得到爬行动物,那就容易多了。
地图房间位置
深圳二手房
可以看到截图右侧有所有二手房的链接。我们的任务是下载右边所有二手房的数据。第一步是查看页面的源码(Ctrl+U),可以从右边的链表中复制一些关键字,在源码中查找,在源码中Ctrl+F搜索Mission Hills并尝试,结果是No,多尝试几个关键词s 好像不行,但是通过检查元素(Ctrl+Shift+I),可以定位这些关键词s。这样可以初步判断右边的链表是通过Js加载的,需要确认。
关键词 源代码中的观澜湖搜索结果
关键词 页面元素中的 Mission Hills 搜索结果
尝试在源码中定位Mission Hills上面的元素,比如no-data-wrapbounce-inup dn,可以在源码中找到。仔细对比两边的上下文,可以看到节点下面的内容差别很大。继续以 关键词 的身份浏览此 roomList。
页眉首页
赫拉德第二页
基本上到这里,整个页面就比较清晰了,也知道我们的爬虫要怎么写了。
开始写代码
逻辑理清后,整个代码就很容易写了。首先通过post访问,通过正则表达式提取response中的roomPageSize,或者最大页数。然后爬取每个页面的内容,输出信息。
第一部分,加载库,需要requests,bs4,re,time(时间用来生成时间戳):
from bs4 import BeautifulSoupimport requests, re, time
第二部分是通过设置合理的post数据和headers来通过post下载数据。payload中收录了地图上显示的经纬度信息(如何获取这些信息,在X房间页面上拖拽鼠标找到合适的位置,到控制台Header查看此时的经纬度即可),并且headers中收录了访问的基本信息(加上一定的反爬效果):
页面下载完成后,第一次下载,首先需要使用正则表达式获取最大页数。我们真正需要的内容是结合Beautiful的get、find和re抓取它:
在控制台中给出一个输出:
最终效果
最后这篇文章文章给了我写X-room网络爬虫全解析的思路。

