技巧:4.woednet(同义词)
优采云 发布时间: 2022-10-31 10:37技巧:4.woednet(同义词)
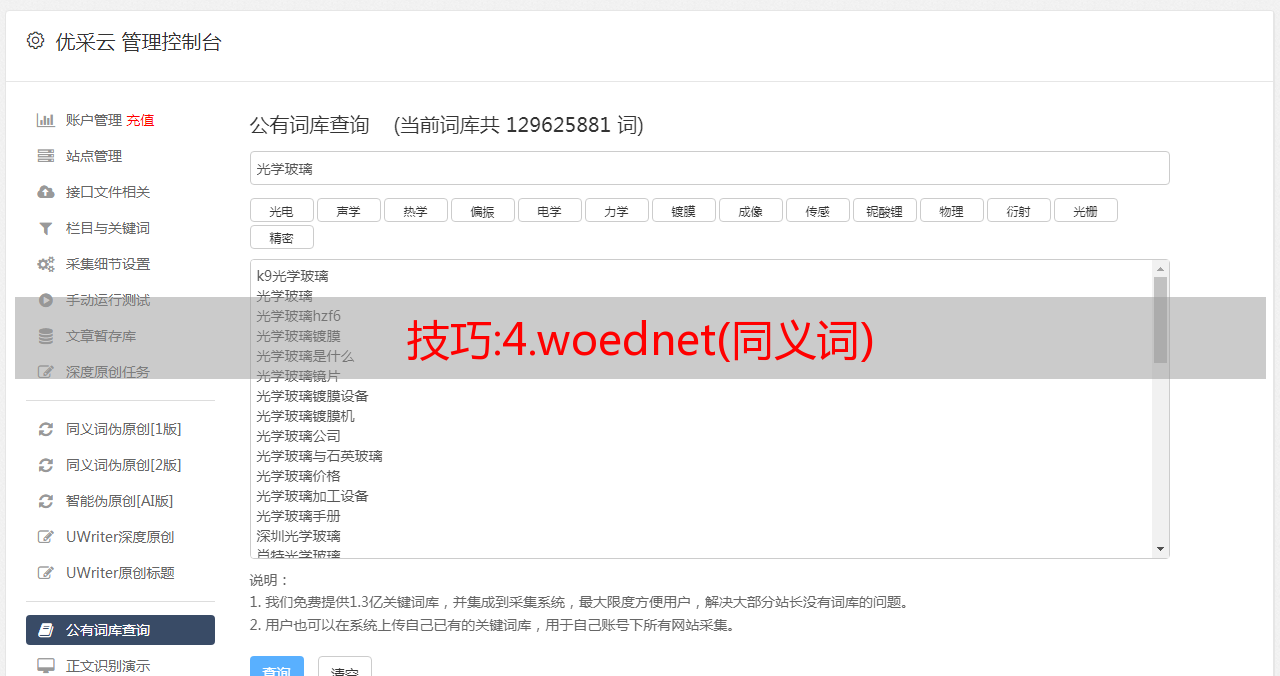
原创论文:“使用知识库自动发现同义词”
背景知识
同义词提取是NLP领域下游任务中广泛使用的一项基础任务。它可用于实体规范化、融合、实体链接、查询重写和提高召回率等任务。现有的方法包括:1)直接扩展Freebase、WordNet等知识库,但这在领域内实体覆盖率很低;2)人工维护词库成本很高;3)有监督/弱监督方法,训练同义词分类器检测固定句型来挖掘同义词,但也需要依靠人工选择一些*敏*感*词*训练数据。本文提供了一种从*敏*感*词*领域期望中自动提取实体同义词的方法。
远程监督:自动从知识库中采集训练*敏*感*词*。过程是:1)从语料库中检测实体;2)将实体链接到知识库;3) 从知识库中采集训练*敏*感*词*。远程监督被广泛用于关系采集、实体分类、情感分类等任务,但远程监督也带来了很多噪音,因为相同的实体文本链接到不同的实体。例如
同义词Washington可以代表地名“Washington State”,也可以代表人名,链接实体库时都可能返回。所以与其使用歧义字符串作为查询,更好的方法是使用一些特殊的概念作为查询,比如知识库中的实体,因为知识库中的实体会携带一些额外的信息来帮助消歧。
将知识库中已有的entity-synonyms作为*敏*感*词*数据,然后利用已有的entity-synonyms对新的同义词串进行消歧,通过投票的方式选择是否接受这个同义词作为新的同义词。在这种情况下,同义词挖掘的任务变为:给定一对候选字符串,判断它们之间的关系是否是同义的(关系分类)。但是问题又来了。现有词库中的*敏*感*词*训练数据很少。如何更有效地使用这些*敏*感*词*数据?有两种方法:
1. 基于分布的方法
考虑语料库级别的统计特征。这里有一个隐含的假设:具有同义关系的配对经常出现在相似的文本中。基于这个假设,该方法通常使用pair的分布特征作为表示,并使用*敏*感*词*数据作为标签来训练分类器来预测给定的pair是否是同义词。但是,这种方法也会带来一些噪音。用过word Embedding的同学都知道,有些pair经常一起出现,但不一定是同义词pair。例如,“阿里”和“腾讯”经常一起出现。.
2. 基于模式识别的方法
比如中文句型,“XX,学名XX”。具有同义语义的对通常符合一定的模式,可以学习更多的模式来发现更多的同义词对。这种方法的可解释性很强,但是召回率会很低。
3. 基于融合的方法(本文)
DPE(分布式和模式集成嵌入框架),包括统计特征模块(全局)和模式模块(局部)。两个模块使用相同的词嵌入,使用*敏*感*词*数据监督训练更新词嵌入和预测同义关系,使两个模块共享信息,提高学习效率。
在判断同义关系时,直接的方法是判断所有候选实体对是否存在同义关系。对的数量很大,模型速度会变慢。您可以使用统计模块对所有对进行排序。重新排序topK的高潜力对,然后进行关系分类。
模型架构
1. 对给定语料进行实体识别,链接给定知识库,采集同义*敏*感*词*进行监督
实体链接时会有一些错误的*敏*感*词*。为了保证*敏*感*词*的质量,只选择同义词/实体本身中提及的那些进行链接,其余的链接将被删除。
2.联合优化分布特征模块(使用全局分布特征)和模式模块(使用局部上下文特征)
使用嵌入方法来表示提及字符串的语义(包括带有实体链接的词和不带链接的词)。对于链接到不同实体的提及字符串,使用不同的嵌入来表示它们。例如,与水果相关的“苹果”表示与与公司相关的表示不同。
统计特征和模式特征两个模块共享底层嵌入,使用*敏*感*词*数据预测同义关系,反向传播更新嵌入。两个模块联合训练的好处不仅是提高了预测能力,还可以让单个模块从另一个模块中学习“知识”,从而提高彼此的学习效率。
2.1 分布特征模块
收录无监督部分和有监督部分;
在无监督部分,对收录提及的字符串构建共现网络的分布信息进行编码。首先,构建词的贡献网络,使用大小为 w 的滑动窗口来反映词的共现特征。每对的权重定义为贡献网络中的贡献数量。在本文中,发现一个字符串的贡献数与以下两个因素有关:1)语义相似的两个字符串更容易同时出现;2)一个字符串倾向于与另一个字符串同时出现在该字符串出现的文本中,两个字符串更可能同时出现
无监督部分:
在监督部分,我们使用同义词*敏*感*词*学习分布得分函数,以字符串的嵌入作为特征来预测同义词关系。例如,“数据挖掘”和“文本挖掘”的共现机会较多,相关性较高,而“数据挖掘”和“物理”的共现机会较少。但即使是具有不同语义的词也经常同时出现,例如“首都”和“北京”。所以有
其中,c_v为上下文向量,表示v的类别,更容易被共同提及,x表示embedding,Z为归一化项,uv向量相似表示语义相似,则
该术语将很大(对应于因子 1)。如果 u 的向量与 v 的内容向量接近,则说明 u 会经常出现在 v 的内容中,所以
项将很大(对应于因子 2)。
最小化预期分布
和经验分布
的 KL 散度,其中
是两个字符串的贡献数,
是 v 在共现图中的度数。构建优化目标:
由于直接优化上述目标的计算复杂度较大,因此使用了与word2vec相同的负采样技术。
第一项最大化同义对的概率为正,第二项最小化噪声负概率。
监督部分:
使用同义词*敏*感*词*对训练同义词分类器的分布函数。衡量两个词的同义词是如何引入的,一个双线性函数用于定义pair (u, v)的同义词得分
在
是评分函数的参数矩阵,为了简化计算,
设置为对角矩阵,同义字符串对的分数大于非同义字符串对的分数,可以根据排序目标优化学习:
2.2 模式模型
模式模型的目标是预测句子中提及的关系是否同义。对于每个句子,首先会提取模式,采集一些语法特征和语义特征来表示模式,最后整合所有模式,确定字符串的同义关系。
将模式定义为三元组。
同义关系的模式表达应该具有相似的特征。“称为”和“已知”经常出现在相似的文本中,因此它们的嵌入非常接近,这两种模式也会具有相似的词汇特征。句法特征是为了识别模式中的句子结构,所以将词性标签序列中的所有n-gram(N=2)作为句法特征。本文只使用了一个简单的逻辑回归分类器,模式同义的概率定义为:
通过学习最大化似然函数来学习分类器的参数。
使用时,先采集pair所在的句子,提取句子的模式,然后用score函数衡量它们是同义词的概率
分母中所有模式的数量。将对不同的模式进行投票,以确定它们是否具有同义关系。
3. 从联合模型中找出查询实体缺失的同义词
训练模型时,将两个模型的目标函数作为整体目标函数,由统计特征模型中的无监督和有监督目标函数和模式模型目标函数三部分组成。使用边缘采样策略。在一个迭代过程中,训练样本从三个部分中交替采样。
在使用时,对于一个新的实体e,对于每一个候选字符串,同义性分数由如下函数计算:
计算e和同义词*敏*感*词*(知识库)和每个候选实体的分数,最终结果由e实体的同义词*敏*感*词*共同投票,判断每个候选词是否为同义词。
Trick:在计算模式同义词得分时,当候选字符串很多时,计算量非常大。可以先使用分布特征模型的分数排序,利用Top Candidates构建一波潜在对,减少候选字符串的数量。,然后通过混合模型的分数重新计算选出的候选者的分数。
实验结果
有兴趣的朋友可以自己看看~
seo外链工具源码 技巧:seo自动优化 做为一位从SEO初学者一路一路走过来的人来讲
作为一个从SEO初学者一路走来的人,SEO优化离不开网站的外链。为了做外链,很多人发愁从何下手?如何有效地做到这一点?到这里小黛整理了,给大家分享一些外链的好基础。如果你想在一些主流搜索引擎上获得好的排名,当然这也是优化者希望得到的一个效果。同时,作为外链建设者,我想你一定要了解自己。竞争对手的外部链接分布。只有这样我们才能知道我们缺少什么?哪个跟不上?在充分了解对手的基础上,可以让我们的外链建设工作更轻松、更高效!虽然我们在一些 文章 中提到过 如何找到更多外链资源,用对工具,事半功倍!下面列出的工具不仅可以帮助您发现竞争对手的外部链接,还可以提供更多免费的外部链接:那么我将与您分享这十六种更好的外部链接工具。
NO.1:链接工具 - 这是一个 网站 友好的链接质量检测工具。一定有一些初学者不知道。没关系。今天看完这篇文章你就知道了。检查您的 网站 是否有反向链接和其他因素,然后寻找一些高质量的附加链接!这将帮助您的 网站 成长得更好!
NO.2:Recip Links - 也是网站上的一个友好的链接检测工具,但是用起来不是很方便,但是稍有耐心,可以检查一个或多个站点是否有指向指定站点的反向链接. 你明白吗?
NO.3: - 也是一个外链资源的搜索工具,类似'Back link和Link Tool的功能,不过这个工具可以自己组合,很个性,我很喜欢用。
NO.4:链接——也是一个在线制作工具。除了上述工具的功能外,本工具不提供锚文本分析,但可以整理出同域名的外链,遇到来自教育和政府的外链网站。使用时会有特别提示!相信你用了之后就明白是怎么回事了。
NO.5:Admin Tools——相信很多人都会使用Yahoo Site和Admin Tools,但只能分析自己的网站外链状态和锚文本。前两个工具生成的“”是系统内置的,不可能根据自己的需要生成足迹!值得使用!
NO.6:Yahoo 网站——这可能是中国最知名的外链分析工具了。其实上面两个强大的功能都不是必须的,但是它可以快速获取网站的外链数,以及前1000个外链,并且可以显示外链页面的标题,从而与上述两种工具不同。仅列出 URL 的地方!
NO.7:(反向链接分析) - 挖掘竞争对手反向链接的好工具。该工具提供了选择是否过滤同域名下的其他连接、是否只显示首页连接、是否分析锚文本、是否分析外部链接数量等选项,让您拥有更多的控制权.
NO.8:Watch(Backlink Watch)——Watch是一款非常流行的外链检测工具,可以轻松分析网站的外链地址、使用的锚文本以及外链页面的链接数( OBL)。以及连接属性,它将被标记。
NO.9:搜索(链接:)——它和雅虎的工具差别不大,但是通常语法搜索的反向链接比雅虎分析的要少很多,但是这些搜索到的页面往往是影响网站的页面排名和使用价值的链接非常高!
NO.10:Alexa外部链接检测工具——这个比较少用。在查看网站的Alexa数据时,可以看到网站链接了多少个域名,并会给出一个详细的列表。更新速度较慢,但质量很高。Alexa主要用于查看网站排名数据!
NO.11:Bad internal text link tool - 检测链接健康度的检测工具,可以同时检测你的内部链接、友情链接,以及对方链接页面的链接健康!
NO.12:链接工具——一个很不一样的工具,当你输入关键词,网站可以自动为你生成各种“外链足迹()”,包括目录网站、博客、论坛等的搜索语法。 ,用于搜索这些,您会发现大量相关的链接资源!
NO.13: 'Back link Text - 这是一个专门分析网站外部链接使用的锚文本的工具。可以用来查看其他网站外链使用的锚文本的状态,供自己参考!
NO.14:'反向链接——一个很简单的外链资源搜索工具,输入你的关键词,工具会自动查找可能收录你的关键词的链接资源,主要是用“”等字符添加site”、“添加网址”、“添加网址+然后点击链接”都是枚举出来的,相当于Link Tool的进化版。
NO.15:'-基本的网站外链挖矿工具和上面介绍的没有太大区别,可以一次性全部使用。
NO.16:火狐浏览器SEO插件-知名插件seo自动优化,可以分析网站的各种数据,包括PR值、外链状态、政府教育站链接、社交网络等. 最大的特点就是当link属性为yes的时候会用红色标注,SEO必备插件!

