分享文章:红叶文章采集器
优采云 发布时间: 2022-10-31 00:49分享文章:红叶文章采集器
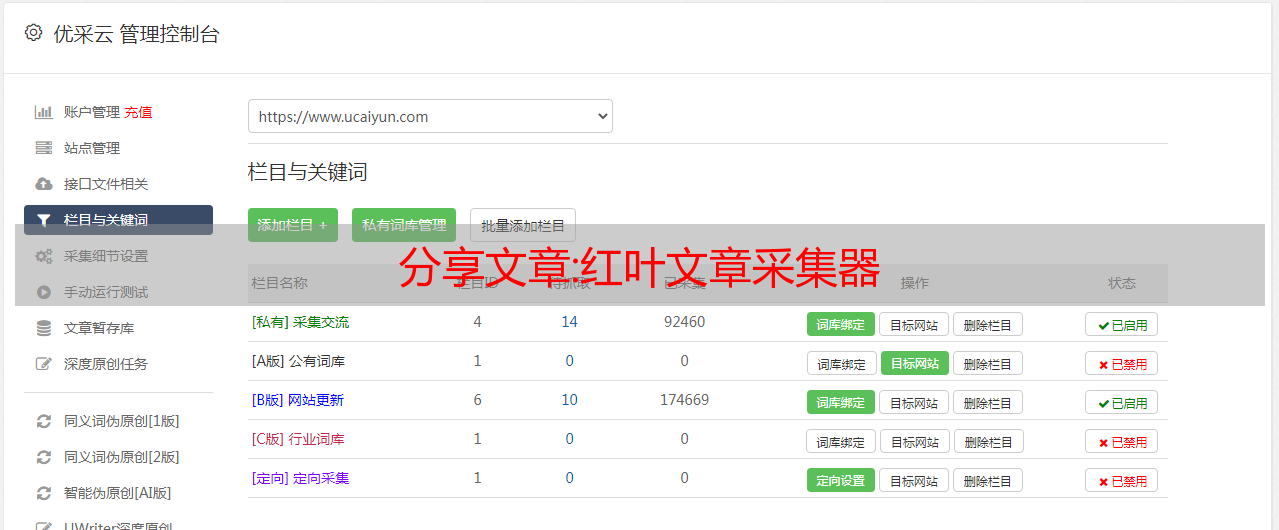
红叶文章采集器是一款超强网站文章采集器,英文名Fast_Spider,属于蜘蛛爬虫程序,用来从指定的海量精华网站采集文章,会直接丢弃垃圾网页信息,只保存具有读取值和浏览值的精华文章,自动进行HTM-TXT转换。该软件在为绿色软件开箱后即可使用!
红叶文章采集器软件功能

(1)本软件采用北大天网MD5指纹称重算法,对于相似、相同的网页信息,不会重复保存。
(2)采集信息含义:[[HT]]代表网页的标题,[[HA]]代表文章的标题,[[HC]]

表示 10 个权重关键字,[[UR]] 表示网页中的图片链接,[[TXT]] 后跟正文。
(3)蜘蛛性能:软件打开300个线程,保证采集效率。通过采集100万精华文章进行压力测试,以普通网民联网计算机为参考标准,一台电脑一天就能遍历200万个网页,采集20万个精华文章,100万精华文章只需5天就可以采集。
干货教程:Xposed实时获取微信公众号推送
友情提示:阅读本文需要一点Xposed开发基础,一点Android逆向工程,以及
一点 Kotlin 基础知识
致谢:@Gh0u1L5,开源Xposedhook框架----WechatSpellbook,很好的框架,推荐一波
(虽然我使用的东西是基于微信魔术师的魔法修改)。
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
正好这个时候在研究Xposed Hook微信,所以打算试试安卓版的微信。需求是什么?
关于什么?如果微信推送一条公众号消息,我们会接受一条并发送到相应的接口进行保护。
保存以供以后浏览。刚准备做的时候,觉得不难,就直接去微信数据库里面的东西了。
下去也没关系,不过太简单了。
幼稚的!!!
微信数据表“消息”中导出的数据是一堆收录乱码的鬼,解析出来的url不是
比如一推五篇文章,只能获取到三个url,让人感觉很不爽。

但是苦就是苦,问题还是要解决的。如何解决?看源代码!
之前我分别反编译了微信的几个dex包的代码,放在一个文件夹里,然后用
打开 VSCode 进行常规查看,
微信反编译出来的源码虽然乱七八糟,但还是能看懂一些代码。
我们看到上面导出的数据有一些乱码,所以我猜微信实现了一个解码工具,比如
如果能hook这个解码工具,解码后能得到正确的数据吗?
说到解码,根据微信之前的数据传输,这些数据很可能是以XML格式传输的。
但是,当涉及到xml时,它必须是键值对的形式。除了我们去的数据中那些杂乱无章的小方块,还有
看起来很有用的“.msg.appmsg.mmreader.category.item”之类的东西。
我打开 vscode,在全球范围内搜索“.msg.appmsg.mmreader.category.item”,很高兴,
搜索的结果并不多,说明这个值确实是一个有意义的值。一一检查这些源代码。
对于:“com.tencent.mm.plugin.biz;” 在包中名为“a”的类中,我发现了一些有趣的东西。
该方法是一个名为 ws 的方法,它接收一个 String 类型的值,并在内部进行一些数据获取工作。
这个 str 参数可以是我想要的标准 xml 吗?
经过hook验证,打印其参数后,发现没有,参数内容的格式与之前数据库中的格式一致
的。
然后我们将重点放在第一行的地图上。方法 ay.WA(String str) 是在做解析操作吗?
毛呢布?
我在 com.tencent.mm.sdk.platformtools.ay 中钩住了 WA() 方法来获取它的返回值,
该返回值是 Map 类型的数据。打印出它的内容后,我的猜测得到了验证。
WA() 方法将刚才的内容解析成一个便于我们阅读的地图。其中收录
图片和短信的数量,以及公众号的id、名字、对应的文章url、图片url、文章描述等信息。
我终于可以在晚餐时加鸡腿了。啊哈哈哈。
此文章仅供研究学习,请妥善食用。
粘贴相关的钩子代码

