整套解决方案:熊猫智能采集器软件 2.6.0
优采云 发布时间: 2022-10-31 00:45整套解决方案:熊猫智能采集器软件 2.6.0
熊猫智能采集器软件下载软件介绍
Panda 是领先的下一代智能采集器工具软件。独有解析仿浏览器解析内核,实现各种采集方法,方便快捷。
独有的智能分析模块,可代您实现对内容页的列表页、标题、文字、时间等进行分析。
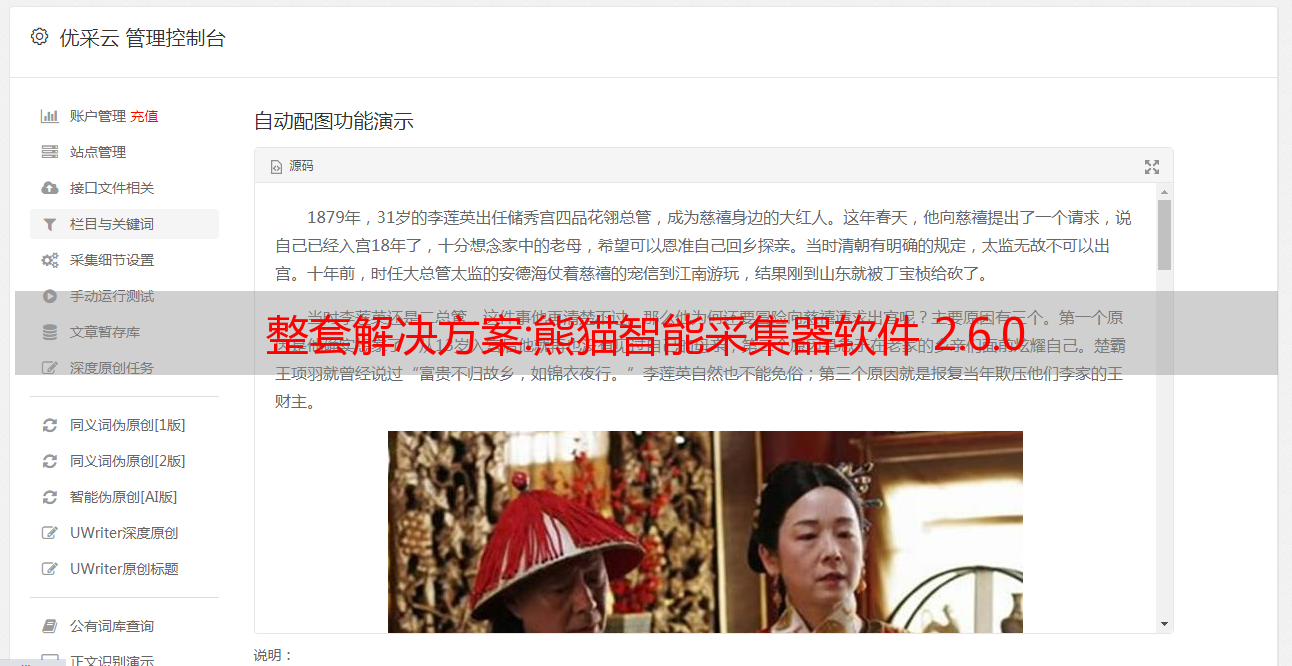
输入实现采集的URL。
输入关键词访问全网采集。
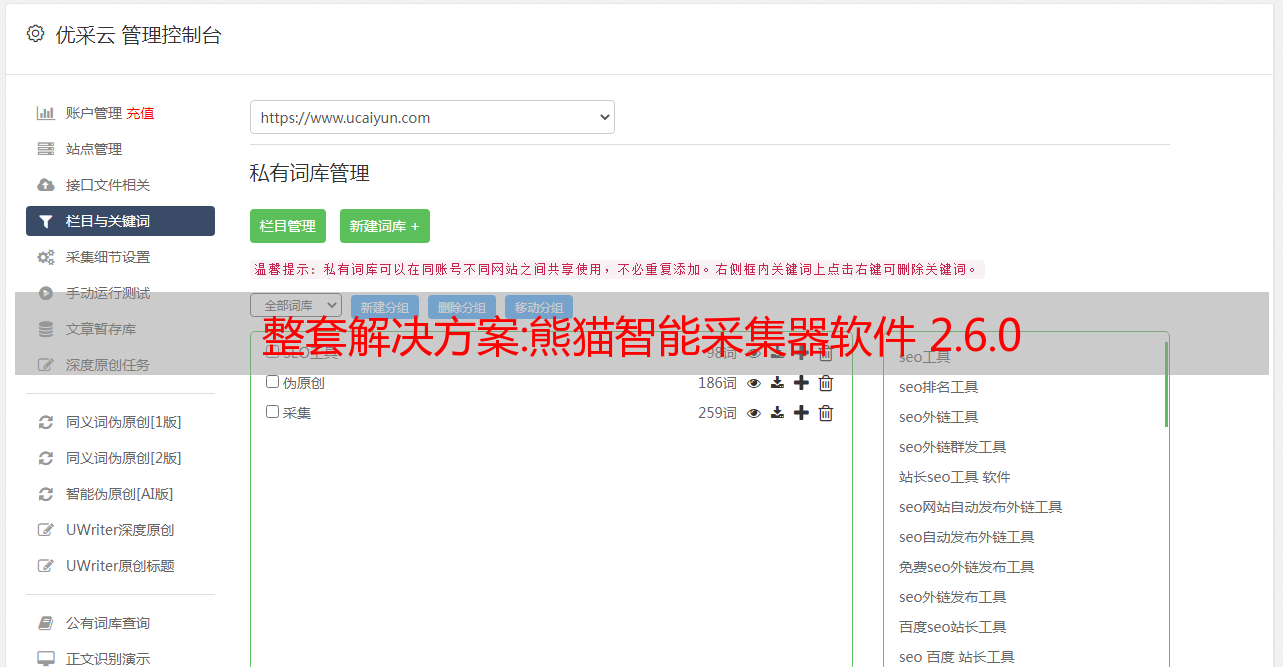
独有的基于点对点P2P模式的云计算采集功能,一键调动上千台电脑,协助您完成采集,从而分散IP,防止IP被封杀.
基于内容相似性过滤重复数据的独特功能。
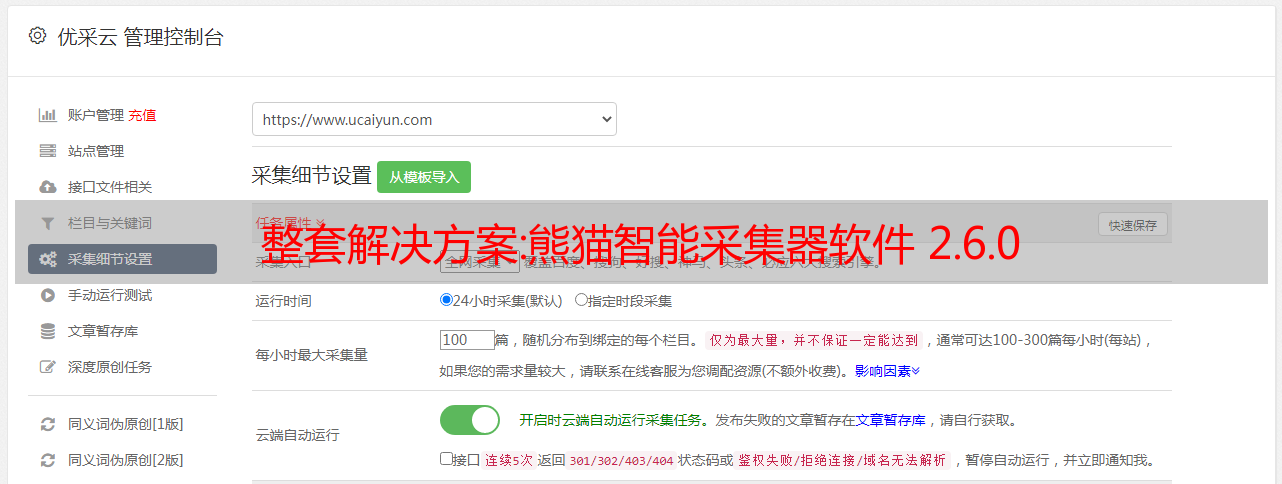
熊猫独有的“多模板”功能,可以实现完整的采集场合,内容丰富的页面。确保数据 100%采集完整。
熊猫智能采集不仅操作简单,而且功能全面强大。丰富的功能可确保满足您复杂的 采集 需求。
总结:搭建风控系统道路上踩过的坑(1)-信息采集
作者前言
在过去的10年里,我参与了3家不同领域公司的风控系统设计。我从前到后仔细琢磨过风控体系的方方面面,但我还是觉得自己只是一只脚踩进了门。
人家做的产品大部分都是有明确目的的,比如订单支付、账户系统从一开始需要做什么,也有很多竞品可以参考;风控系统完全不一样——未来会面临什么问题是不可能完全搞清楚的,每一个功能都要小心翼翼的做好,因为如果不注意方向错了,可能会在一个瞬间被彻底颠覆未来的某个阶段。
而对于研发资源紧缺的安全需求,他们往往会在某个时间把自己置于一个非常尴尬的境地,无法解决问题,转型面临大量的时间和沟通成本。
所以在这里分享一下自己踩过的一些坑,让准备搭建风控的人有个思路。
业务安全风控设计101-信息采集
业务风控主要做四件事:
取数据这件事几乎是决定风控系统成败的核心。由于篇幅问题,我们将主要关注这一点。需要考虑三个主要事项:
1 获得的数据越详细越好:
以账户安全为例,如果能得到基本的登录注册数据,可以从频率和登录注册特征分析;
如果可以进一步获取登录和注册行为的上下文,比如登录前访问了哪些页面,登录后访问了哪些页面,可以从访问行为轨迹上增加更多的分析维度,比如页面停留时间,是否有访问过的必要页面等;
如果还可以获取到用户的操作行为数据,比如鼠标移动和键盘输入的轨迹,那么就可以从操作过程进一步增加分析维度,比如输入密码时是否有多次输入删除?是直接复制粘贴账号密码吗?
2 建立标准的日志格式:
一旦确定了可以获取的数据,就该开始构建标准日志格式了。
常见的登录、注册、下单、密码修改、绑定凭证修改等应给出标准的日志格式,并充分考虑字段命名的统一性。例如,如果密码和用户名字段的名称在不同的日志中的名称不统一,后续分析和指定策略会很麻烦。
3 获得的数据质量:
很多时候风控关心的信息,比如IP地址,UserAgent,referer等信息服务都不关心,但是缺少这些信息可能会导致很多策略失败,所以在采集的开头信息,必须有一个清晰的信息清单,一旦被攻破,然后返工做R&D Plus,就会被看不起。
比较常见的是需要用户的访问IP,获取的IP地址是内网的服务器IP;或者需要用户名,并且 UID 作为结果传递。这需要大量的前期沟通和确认工作。一旦上线后发现数据有误,同样会遭到鄙视。
有两种类型的数据采集:主动和被动:
1 主动方式
主动方式是去数据库和日志读取。
这种方式实时性较差,基本拿什么,加信息比较困难,但是不需要研发配合太多东西,适合喜欢自己动手的场景.
当然,一些成熟的公司有自己的消息总线,风控可以订阅实时信息并作为数据源进行分析,但这通常是少数;
2 被动方式
被动的方式是给研发提供一个接口,让业务按照格式标准来喷消息。
这种合作周期很长,但是按照标准可以获得高质量的信息,所以搭建风控体系是比较常见的方式。
踩坑
坑1:
如果消息来自多个数据源,则必须考虑消息的时间顺序:
比如登录日志是从公共服务发送的,access_log是获取网页访问的,用户操作行为数据是从页面JS或者SDK发送的,所以这三者的时间是不一致的。
这必须在确认所有消息都到位后进行分析和判断。否则,如果实时策略认为登录时必须有页面键盘点击,并且两个数据到位的时间不一致,可能会出现大量的假封,造成事故。
坑2:
采集返回的数据必须定期监测数据质量——
已采集返回的数据可能因技术结构调整、代码更新等多种原因不准确,如不能及时发现,可能导致后续分析过程出错。
坑3:
采集积分要尽量选择稳定的业务积分,比如采集登录日志,一次性公共服务采集好的,以后有问题,找个积分就好了。
如果你去前端从web、手机等调用登录服务到采集,如果出现问题要改的工作会成倍增加,并且可能会出现logs的情况不能覆盖新的业务点。
坑4:
关于技术选型:
消息队列是必需的。Restful只能处理业务日志,比如登录,每秒最多可以使用几次。如果以后想去 采集 页面访问行为,就必须使用每秒数千条消息。队列。
开源可以考虑RabbitMQ或者Kafka,稳定性还不错。
坑 5:
关于日志存储:
ELK是为后续分析平台提供基础查询功能的不错选择。
结语
信息采集往往是实施风控最难的部分,但也是最重要的部分。覆盖范围、质量和及时性都决定了一个项目的成败。
由于沟通的压力,往往会出现较多的妥协,这会给后期风控体系的建设埋下隐患。事实上,一篇文章文章很难描述细节。
如果您在这方面遇到困难,请留言与我们沟通。如果您对接下来的内容感兴趣,请分享并鼓励编辑,我们会尽快给出后续章节。
关于作者
刘明启安科技联合创始人、首席产品技术官
6年以上风控及产品相关经验,曾就职于网易,负责《魔兽世界》中国区账号系统安全。现带领奇安互联网业务风控团队为客户提供明星产品Warden、RED.Q等风控服务。

