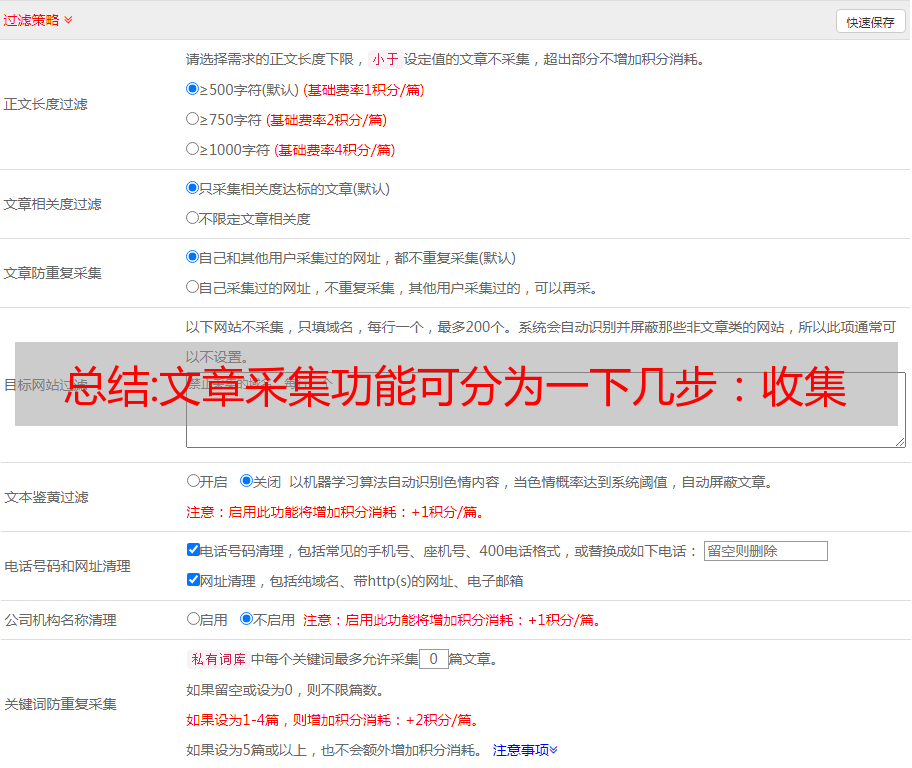
总结:文章采集功能可分为一下几步:收集文章框架、关键词、标题数据收集的方法
优采云 发布时间: 2022-10-30 21:16总结:文章采集功能可分为一下几步:收集文章框架、关键词、标题数据收集的方法
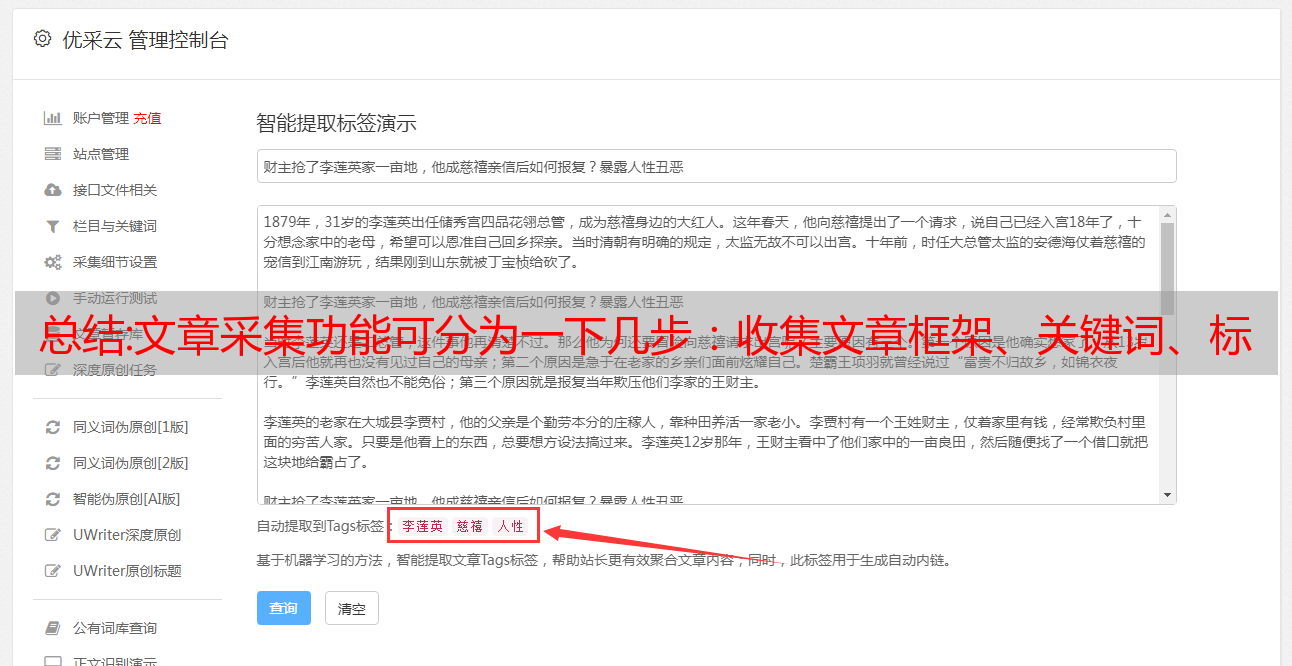
文章采集功能可分为一下几步:收集文章框架、关键词、标题数据收集的方法:网站爬虫爬取、wordpress爬虫爬取,信息存储使用:一次爬取多个页面每次爬取一个页面的文章数据。步骤1:收集源码导入的两个excel文件分别是笔记本sheet1和笔记本sheet2,在sheet1中添加一列,笔记本号,这个问题可以参考我前面的回答:框架使用excel导入要注意什么问题?步骤2:利用wordpress采集器导入网站数据关于wordpress采集器的安装,欢迎参考我前面的回答:使用wordpress最重要的是什么?步骤3:写入excel数据框架代码wordpress框架代码:fromwordpress.contentimportwp_sitemapfromwordpress.pluginsimportloadersimporttimebody=wp_sitemap.png(max_content=1024)meta=loaders.get_text('date')#解析网站urlsession=import_text('user-agent')headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/61.0.2185.105safari/537.36'}start_url=''end_url=''storage={'referer':''}doc=wp_sitemap.backends.jieba.findall("///[@id='suhlgtv']/text/{1}/".format(pile('')))("=",headers=headers)body=doc().get_html()body.append("_site:",doc.text)body.extend("\n")fori,docinenumerate(body):list_html=[]row=doc.text.replace("/\t","")row=doc.text.replace("/\t","")row.append(row[0],row[1])img=doc.text.replace("/\t","")img=doc.text.replace("/\t","")img=doc.text.replace("/\t","")img=doc.text.replace("/\t","")doc.findall("\n",img)new_url=''iflen(list_html)==1:new_url.append(list_html)new_url=session.queryselector("@")ifnew_url.length()==2:content=body[0].astype("text/plain")else:content=content[0].astype("text/ascii")body=parse_jieba("",format=list_html)body.split('\n')body=body[1]body.extend(body[0])。