近期发布:帝国伪原创-可视化批量采集发布管理
优采云 发布时间: 2022-10-29 09:29随着互联网的普及和发展,网站建设变得非常普遍,无论是公司、个人还是各种门户网站都在我们身边。可以说,互联网改变了人们的生活习惯。随着网站的数量越来越多,用户对我们的网站内容的要求也越来越高。如何保持网站高质量的持续更新是很多站长头疼的问题。博主在这里和大家分享一下网站内容更新的一些心得:
1. 使用 Free Empire伪原创插件采集Industry关键词
关键词主要来自用户输入的行业关键词和自动生成的下拉词、相关搜索词、长尾词。一次可以创建几十个采集任务,同时可以执行多个域名任务。可以在插件中进行以下设置:
1.设置屏蔽不相关的词,
2.自动过滤其他网站促销信息
3、多平台采集(覆盖全网头部平台,不断更新覆盖新平台)
4.支持图片本地化或存储到其他云平台
5.支持各大cms发布者,采集之后自动发布推送到搜索引擎
使用帝国伪原创关键词改进网站收录
2. Empire伪原创内容SEO优化功能
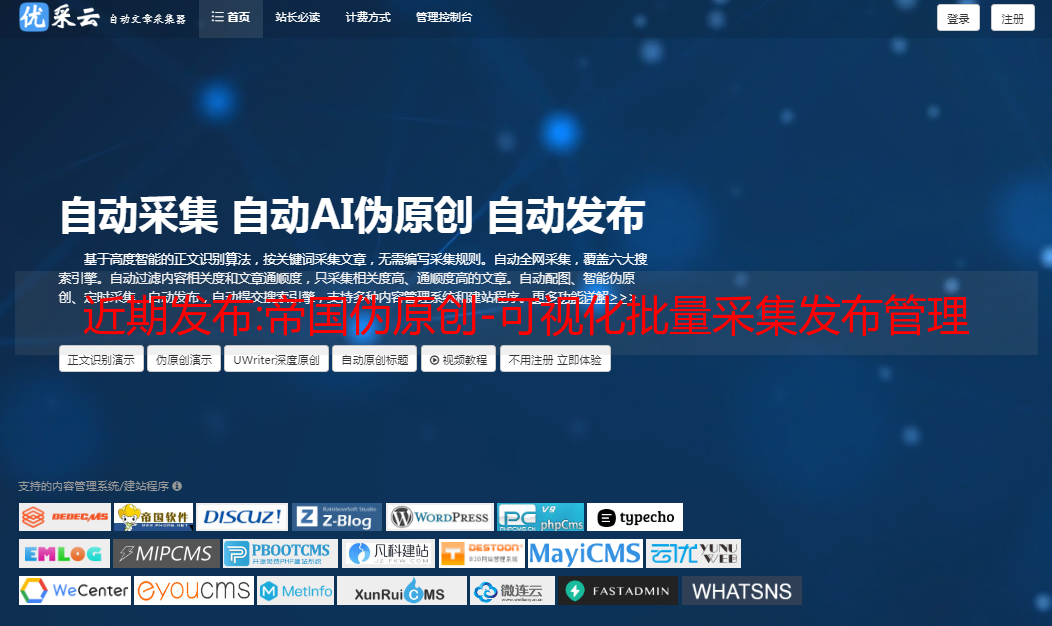
1.标题前缀和后缀设置(区分标题会有更好的收录)
2、在内容中插入关键词(合理增加关键词的密度)
3.产品图片随机自动插入(插入自己的产品图片可以让内容展示更清晰)
4、搜索引擎主动推送(将发布的文章主动推送到搜索引擎,缩短新链接被搜索引擎收录的时间)
5.设置随机点赞-随机阅读-随机作者(增加页面度数原创)
6.设置内容与标题一致(使内容与标题完全一致)
7、设置自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权重)
8.设置定时发布(网站内容的定时发布可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录)
3. 自由帝国伪原创-Visual Batch网站管理
1. 批量监控不同的cms网站数据(你的网站是Empire, WP, ZBLOG, Yiyou, 织梦, Apple, Cyclone, 站群, PB、搜外等主要cms工具,可以同时管理和批量发布)
2.设置批量发布数量(可以设置发布间隔/每天总发布数量)
3.可以设置不同的关键词文章发布不同的栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
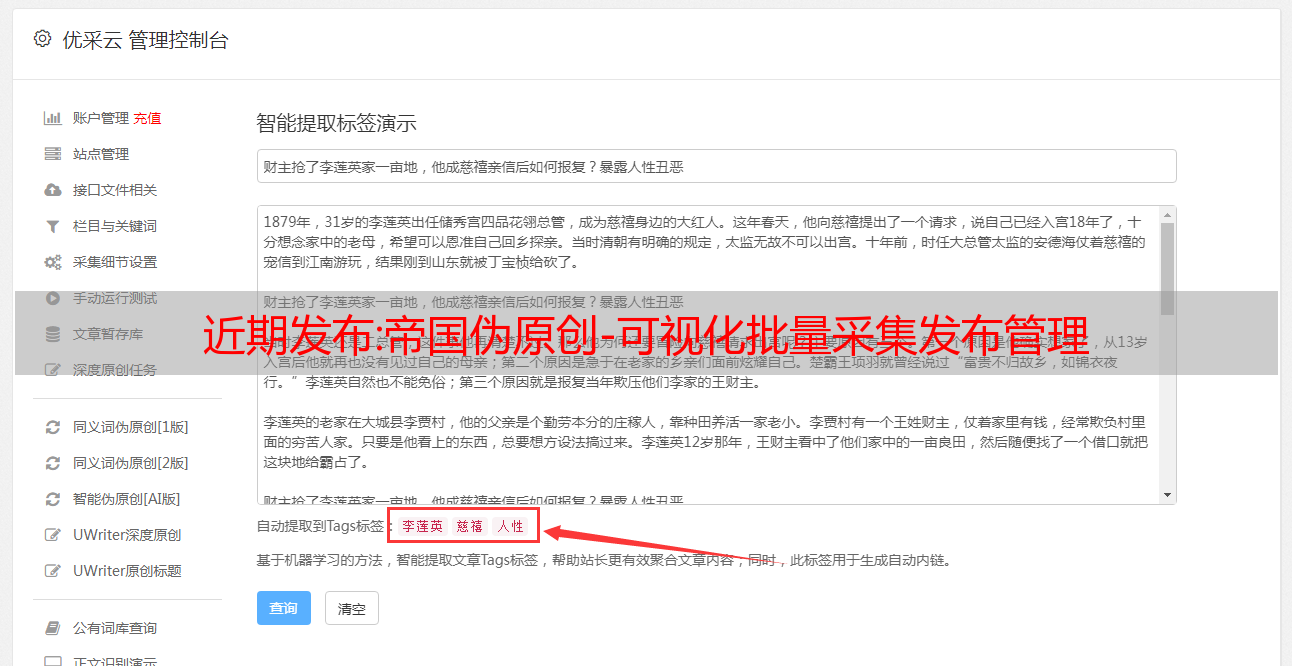
5、直接监控已经发布、即将发布的软件,是否是伪原创、发布状态、网站、程序、发布时间等。
6.每日蜘蛛、收录、网站权重可以通过软件直接查看!
网站优化还要求我们有扎实的基本功,其次,要有良好的嗅觉。当我们发现一些热点新闻时,一定要善于挖掘出一些可能成为热门搜索的词关键词。个人认为做seo优化还需要以下四点必不可少的操作:
1.个性化和目标受众:
原创内容与自己的行业越紧密,价值越高,竞争对手抄袭的可能性就越小。同时,还要考虑目标受众的需求,为客户、为用户编写内容,而不是为搜索引擎编写内容。
2.适当优化
重要的是优化我们的关键词,关键词不要过度优化,关键词不要太密集,尽量控制在5%。重叠关键词增加密度不是一种选择。您通过 关键词 获得的流量非常精确且非常有价值。所以,我们要珍惜并努力提高转化率。
3.网站TDK的稳定性
不要频繁更改网站的基本信息,包括网站的标题、描述、关键词,TDK会在我们建站的时候做最后的决定,记得两天小改,三天大改天。过于频繁的改动会让蜘蛛对我们网站产生反感,所以我们网站的开头一定要有一个明确的目标,明确网站的方向、内容和布局。
4、长期坚持
罗马不是一天建成的,我们的 SEO 工作需要时间才能看到结果。我们要有一种不为事情高兴、不为自己难过的心态,不断根据数据纠正偏差。优质的内容,持续的优化和不懈的努力,就是好的优化!
完整的解决方案:互联网情报系统实践-04:数据源定义和管理
定义:
数据源:这里的数据源不是数据库的数据源,而是我们的采集对象分布的来源,这里特指可以获取有用数据的网站/网页。
URL:需要 采集 的网页 URL 列表。URL可以在采集任务启动前指定,也可以在采集过程中动态添加。
采集规则:由于机器学习建立的模型还没有自动采集,所以需要配置采集规则。采集 规则旨在支持:css 选择器选择器、网页的 jsonpath 选择器和 采集 配置 json 数据。
遵循分而治之的原则,我们不会在情报采集业务系统中定义目标不明确的数据源,比如全网采集,整个网站采集,但是会细分为网站的子栏目,具体集合的目标页面,经过这个约定后,一个数据源的采集页面一般会分为两种:“列表页面”和“详细信息页面”。
列表页通常是栏目/类别或查询结果页,通常收录一些字段,如文章标题、摘要、日期、缩略图等。最重要的是,列表页收录采集详细信息页面的 URL,其中还收录其他分页列表页面的 URL。
详细信息页面通常收录更多单元对象的 采集 字段。
在更复杂的情况下,列表页 采集 中的数据与详情页上的数据相关,甚至详情页还有下一级页面或分页。这些都在采集规则模块的设计和配置中。需要考虑。
针对上述情况,我设计了一个简单的数据源管理模块,实现以下功能:
1.数据源分类管理
2.数据源的增删改查,数据源配置可视化
3.采集数据源目标页面的规则设置
数据源的分类管理比较简单。可以对数据源进行分类和标注,以便管理者根据分类或标签进行过滤,提高工作效率。
对于数据源的可视化配置,每个采集页面都需要设置采集规则,设置过滤器,匹配URL,以及一些关联,所以前端使用类似流程图的工具来实现可视化编辑工具(前端使用jsplumb开源版)。见图片:
数据源目标页面的采集规则设置,采集规则设置将支持脚本化和可视化操作,用户只需选择需要为采集的内容,系统会自动判断对应的 CSS 选择器和 jsonpath 选择器,反过来,技术人员也可以输入选择器来调试匹配的内容。

