总结:内容采集软件的采集策略和关键词匹配建议与建议
优采云 发布时间: 2022-10-28 09:21内容采集软件
一、采集技术
二、采集策略
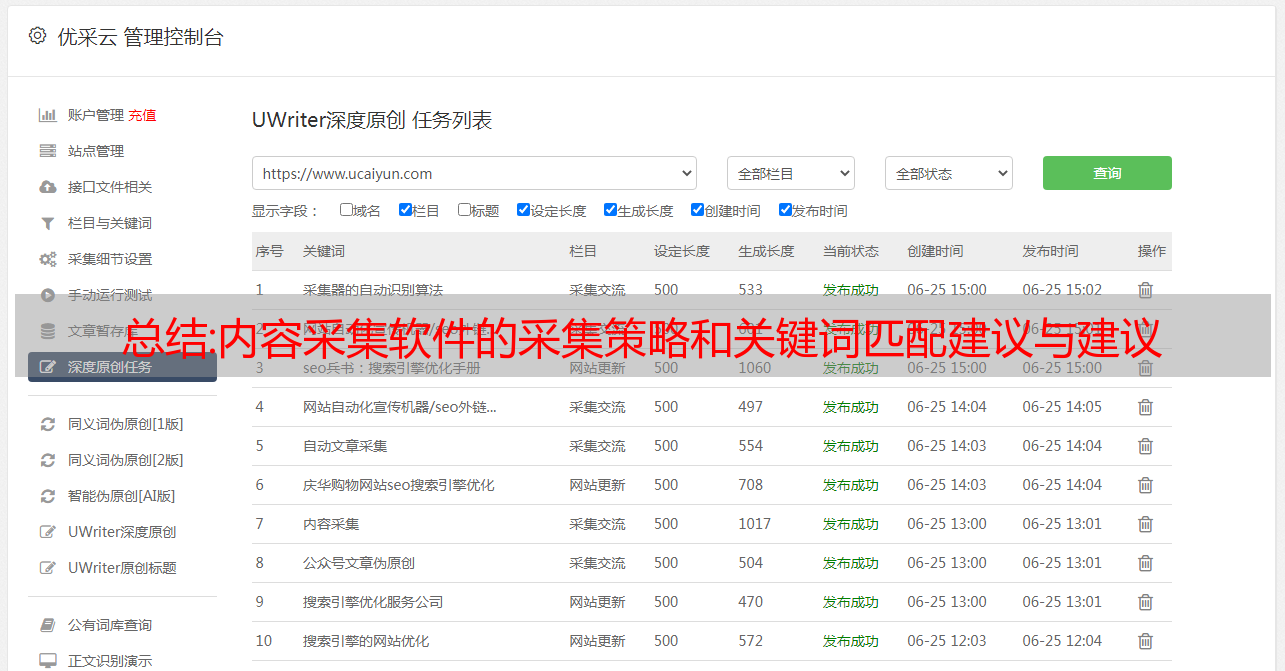
三、采集字段、不匹配字段、关键词匹配建议与软件技术团队交流参考《python爬虫大全》到教程入口
python技术社区应该有蛮多类似的问题,其中知乎有人提到豆瓣爬虫。一看问题里技术类的问题很多,而具体爬取到的数据是否有价值,需要在实际爬取数据时找出有价值的分析。
主要分为两类方法:有价值的数据往往是含有丰富的信息,而有的信息之间也可以通过某种映射关系来进行检索;另外一类方法是通过二次分析,将不同数据进行系统性的处理,以达到用同一个数据集进行数据分析的目的。豆瓣的数据是用的mongodb数据库,一是通过设计好的数据库模块进行转换;二是通过代码生成豆瓣原始数据,处理豆瓣原始数据时也要考虑到数据的信息量。以上希望对你有帮助。
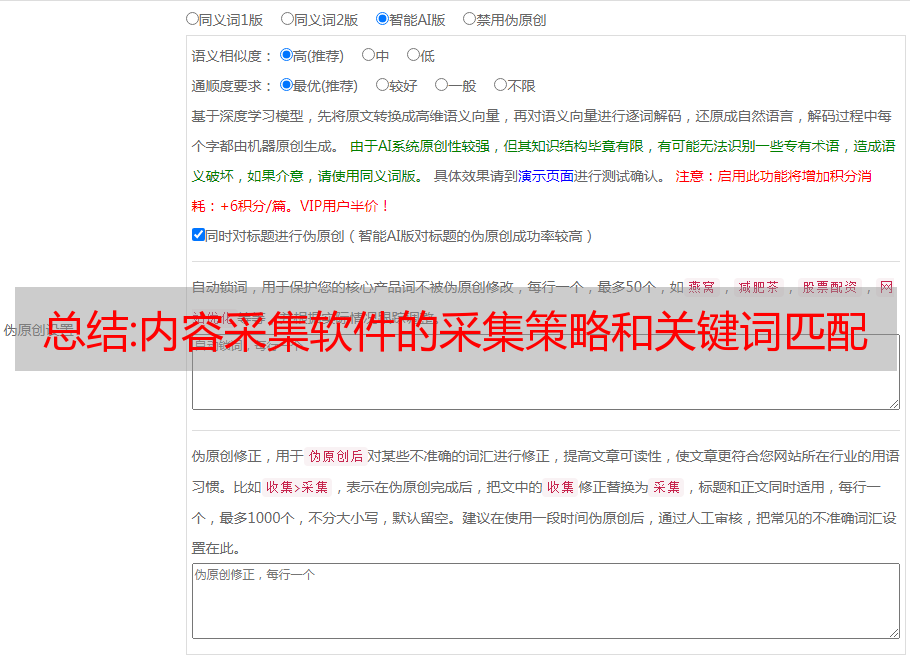
刚爬的豆瓣电影,算是个简单的演示,但也只能代表部分人的看法,不足以全面回答你的问题,具体还要根据业务场景,数据量等因素计算出结果。数据量太小可能会更简单粗暴些,但数据量大了,会有很多分析,可惜我目前只有豆瓣电影的一小部分数据。
可以上数据采集下载
抓取统计信息。适合爬去最多只要多级分类的电影,以及一些名作电影,总共会有几百万条信息。这些数据还可以进行分析,例如用户评论。是否有高有低。电影评分电影相似度或者是电影奖项,获奖信息。或者电影相同时间段的电影都趋向于相同,那么电影的高、低产量应该是平均的,也就是它的基本热度。利用程序爬取近年所有影片的豆瓣id,即可获得电影名字和年份。
根据所有该年的平均热度,这些电影的基本热度将趋向相同。这个可以通过可视化工具设计展示方案和电影时间点转换工具。

