完整的解决方案:帝国采集插件-批量采集软件
优采云 发布时间: 2022-10-27 21:31完整的解决方案:帝国采集插件-批量采集软件
Empire 采集 插件好用吗?Empire是一个免费开源的cms系统,所以很多网站都是Empirecms建站系统。Empire采集 插件好用吗?如果是纯采集,没问题,填数据,但要找不同的采集源写规则。如果熟练使用 HTML+css 编写规则的话,也不是特别难。如果不懂代码规则,使用Empire采集插件,那就更麻烦了!这时候肯定有很多朋友说我看不懂代码。我应该怎么办?
帝国采集
我不知道如何发布 HTML+css 采集:
1、输入关键词到采集即可:搜狗新闻-微信公众号-搜狗知乎-头条新闻-百度新闻-百度知道-新浪新闻-360新闻-凤凰新闻(多个采集可以同时设置来源采集)
帝国cms采集
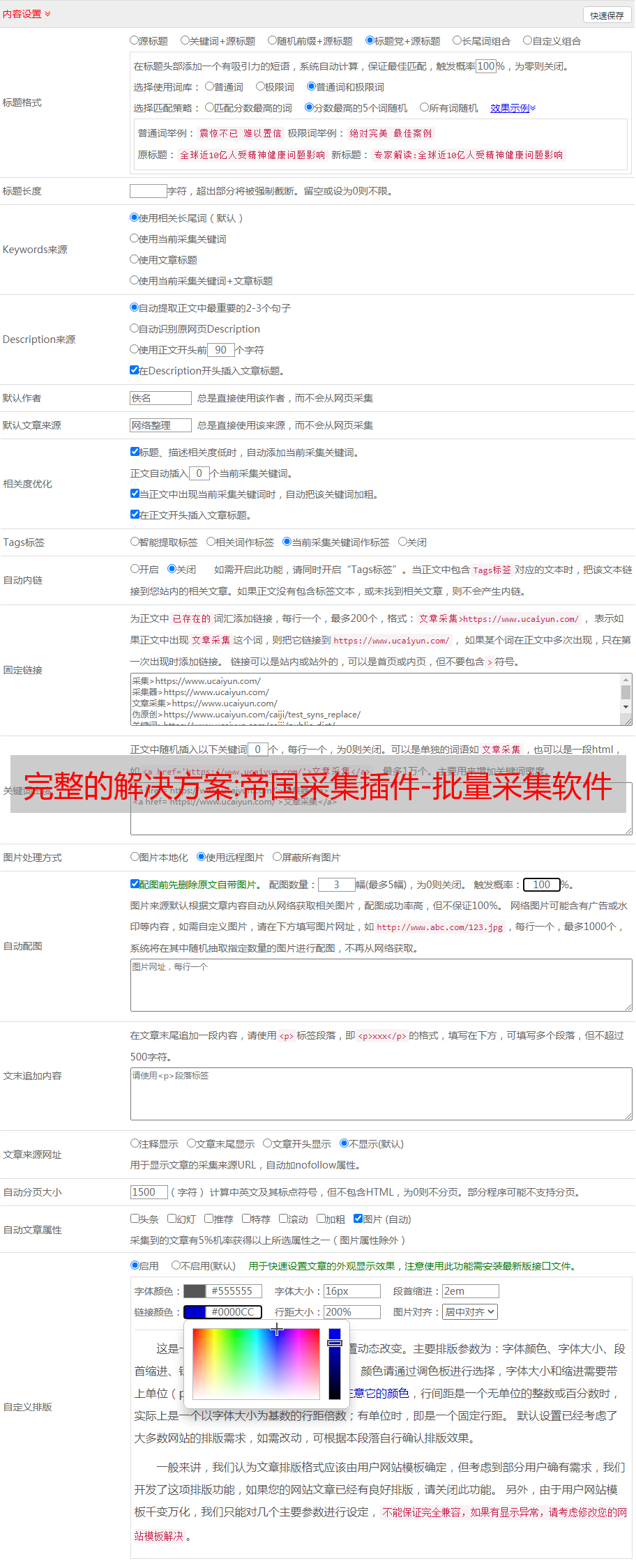
2、根据关键词采集文章,一次可以导入1000个关键词,同时可以创建几十个或上百个采集任务时间,你可以随时挂断采集。
2.可以设置关键词采集文章数量-支持本地预览-支持采集链接预览-支持查看采集状态
2.不同的网站cms版本
监控文件夹发布:你在桌面创建一个文件夹,使用软件监控文件夹,一旦文件夹中有新内容,立即发布到网站。(支持将修改后的文档复制粘贴到其中)
cms发布:支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等主流cms,可同时管理和发布
帝国cms 已发布
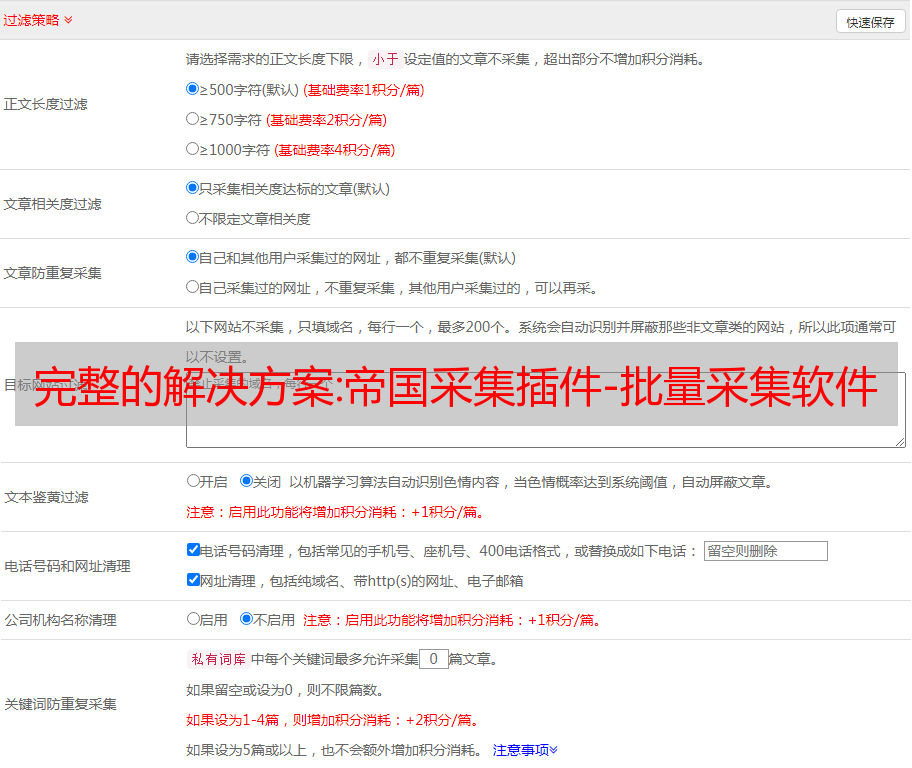
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发布一篇文章
监控数据:已发布、待发布、是否伪原创、发布状态、URL、节目等。
网站详情
为什么我不使用 Empire 插件?首先使用Empire采集插件需要时间,其次还要写很多规则,一天同时管理10个网站,时间不够用,我已经筋疲力尽了。. 最后,我改变了使用它的方式。效率提升了好几倍,也有更多的时间做SEO的细节,大大提升了网站的流量。
教程:如何批量采集内容?小白站长福音,自动化采集部署攻略
上一篇文章解释了垃圾网站的情况,里面提到了一个特殊的垃圾网站,它使用采集插件来实现网站的内容自动灌装。
作者之前没做过采集,近期打算做一个资源共享站。由于资源材料量太大,自己做,所以花了300块找人做了一个采集,研究了一下,发现不难,就分享一下今天和你一起。
1.了解采集插件
要想用好采集工具,首先要知道有哪些采集工具可用。如果你的网站是用各种开源系统搭建的(开源系统可以参考我之前的文章>),一般会有对应的采集插件,也有一些著名的 采集 软件。
作者不是采集的专业人士,今天只分享作者使用的优采云采集软件。它不是作为插件存在,而是作为独立软件存在。在windows系统下运行。
要使用优采云采集,您需要知道如何配置发布者以及如何配置采集 对象。所谓发布者就是你自己的网站,所谓采集对象就是你要提供的具体采集对象的页面内容。
2.如何配置发布者
由于是付费制作的,这部分正是作者无法解释清楚的地方,因为发布模块设置了访问密码。
由于作者花钱请人制作,有理由相信该模块的创建者也在保护他的劳动成果。但同时作者也找到了一个发布模块网站,可以下载各种开源系统。
同时,在这个网站中也有很多用采集的功能编写的学习类文章。有兴趣的朋友可以深入挖掘。如果你不想深入挖掘,你可以看看有没有你用的。网站系统的发布模块。
3.如何配置采集终端
这里不得不说,作者也很懒,没有认真研究采集,只是按照别人写的规则研究了一下。
从上面的截图可以看出,这是采集的配置的第一个地方。左边的“一级列表页面”表示我要采集的页面只有一级列表。接下来是干货!
1、抽取规则中的代码是从哪里来的?
· 通过浏览器打开起始URL(即我们要采集的内容的页面)
· 在打开的页面按F12(windows电脑)调出网页调试
· 选择小箭头(mac和windows系统不同,自己找)
· 选择页面中的内容区域
仔细对比一下这里的代码是不是和抽取规则里的代码一模一样?是的,提取规则是将此内容用作条目。同时提取此缩略图以用作您自己的 网站 发布的缩略图。
注意:[parameter]标签是要提取的信息,(*)标签代表忽略信息。
2. 设置区域从哪里获得?
还是用刚才的方法,这次我们用小箭头选择整个列表页:
让我们比较一下
另一个实际上是翻页标签。要知道这个列表有很多页,采集系统需要识别到哪里翻页:
除此之外,还有一些配置需要做,但基本操作方法类似。如下所示:
3.内容采集规则
请注意,上面的标签列表每个人都不一样,只有标题和内容是通用的,这里我主要说一下标题和内容的提取:
首先我们需要到采集对象的文章内容页面,然后用和之前一样的方法获取源码部分。一般情况下,标题会默认在head标签中(如果不知道head标签是什么,可以参考我之前的文章前后端集成介绍):
所以填写固定标签:“title”:“[parameter]”!如下所示:
意思是读取title后面的参数:tag。请注意这里选择的是正则提取,就是从特定的一段内容中提取出我们需要的参数采集。大家注意到下面的截图中有一个数据处理,是什么意思呢?
截图中可以看到,毕竟是来自别人的网站采集内容,难免会被别人带上一些自己的网站标记,我们要自然地使用别人的内容如果你不想出现别人的网站标志,那么你需要使用数据处理功能自动替换一些我们要替换的内容。
可以看出里面有很多高级的替换功能。如果你想移除它,就拿移除规则,你可以自己研究其他规则。
注意:数据处理可以同时添加多个规则,可以同时处理多个替换函数。
下面介绍内容采集,我们选择在内容区前后截取采集,是什么意思,也就是通过定义头部和尾部,采集头尾之间的全部内容:
上面第一个框中截取的代码是开头,第二个框中截取的代码是结尾。由于代码是折叠的,你可能看不到详细的代码,但没必要。我们使用上面的绿色浏览器。而蓝色区域可以看到整个文章内容区域其实已经被截取了。
填写开始和结束字符串。那么在数据替换中,为了防止采集接收到的信息以代码的形式被采集转为自身网站,我们需要做一些数据处理,让内容采集 收到 变成了最简单的文本!HTML标签排除的应用可以排除一些我们不想采集的内容:
其他采集对象需要根据实际发布物品为采集,大体规则类似!最后,您可以测试 采集 并发布它。会玩电脑的小白自己摸摸!(反正小编之前没接触过采集,所以如果你有模板可以参考的话,是拿不到的!)
4。结论
小编之前没玩过采集,第一次接触,觉得真的很方便,不知不觉就分享了!仅仅把它当作教程,也就是让大家有个基本的了解是不够的。如果你想系统地学习,可以找一些采集的资料自学!最后一点,本文中演示的采集对象仅供演示,织梦58net可以理解。
大家请正确、合理、合法地使用采集功能,关注我,了解更多小白可以学习的网络知识。有问题可以留言咨询!

