免费的:网页图片采集-任意网页图片批量采集软件免费!淘宝采集上货软件2022?
优采云 发布时间: 2022-10-27 19:17免费的:网页图片采集-任意网页图片批量采集软件免费!淘宝采集上货软件2022?
一个免费的网页图片采集软件可以采集网页上的各种图片,每个人都可以采集到各种高清图片源。支持采集任意格式的图片,只需导入批量采集图片的链接即可。
采集还有更多方法:输入关键词所有图片采集/any网站所有图片采集!不仅可以采集大量图片,还可以批量压缩/放大/给图片加水印等/详细如图
这个免费的图像采集工具具有以下特点:
1.支持不同网页图片采集/支持导入URL文件采集图片/关键词图片批量下载
2.支持自定义图片存储目录或上传到网站,根据URL特性自动为图片创建分类目录
3.支持一键重新下载失败图片采集
4.支持下载镜像去重
5.支持采集过程中查看下载的图片
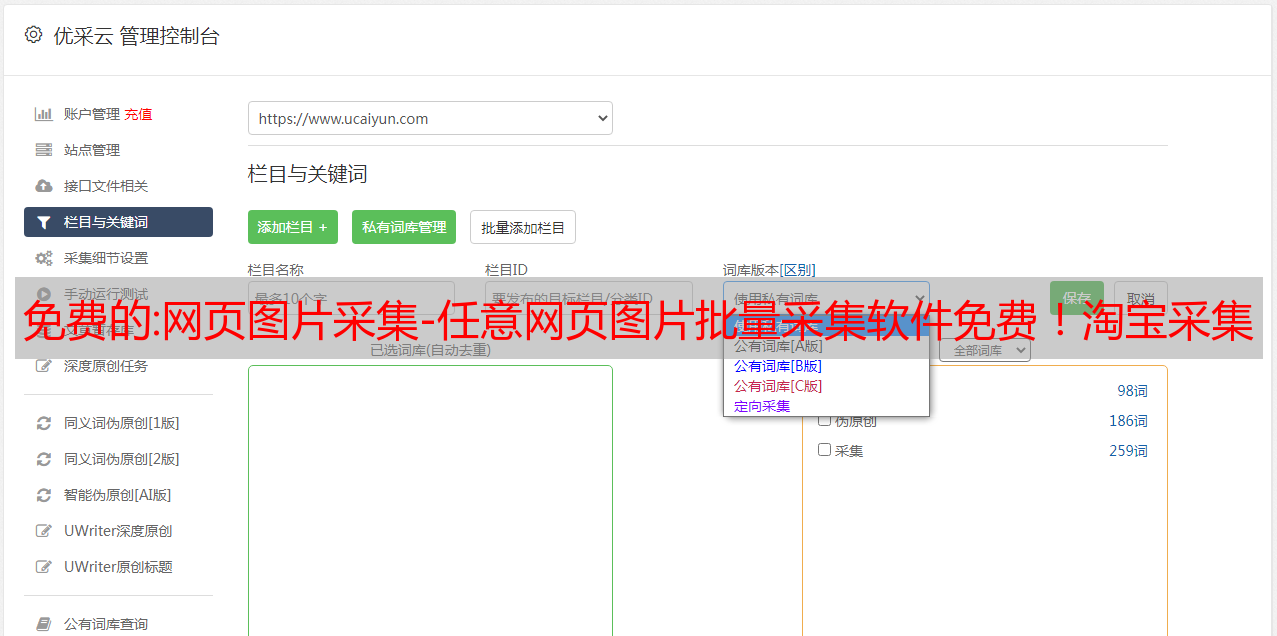
6.批量图片水印压缩等处理
SEO优化是一个非常复杂的项目,图片优化就是其中之一。大部分人都知道,现在很多网站都是以产品为主,图片会很多。其实这些图片也是可以优化的,那么如何优化呢?
图片大小:在浏览网页时,用户不再偏爱明亮的文字,而是转向图片和文字的结合。一篇漂亮的文字配上高端霸气的画面,就像一个穿着漂亮裙子的美女。楚楚动。但是在配置图片的时候,需要注意图片的大小和尺寸。当搜索引擎发送蜘蛛来抓取您的 网站 图片时,它们喜欢大小为 121:75 像素的图片。一种是将它们发送到 网站 服务器。解压,二是不要拉低网站的网速,用用户的点击快速浏览,一般来说,如果6秒内无法打开页面网站,你的用户就会离开。
ALT标签属性:作为一个SEO,你需要知道任何搜索引擎还没有识别网页图片中图片的内容采集,所以如果你想搜索引擎识别图片的内容,你只能把这个艰巨的任务交给AIL属性。蜘蛛是靠alt生肖来识别图片的,但是请注意不要做任何关键词的叠加,只要内容一致即可。
标题标签属性:很多SEO站长记得图片的优化需要alt标签,却忽略了标题标签。新乡SEO认为这个标签和网页图片的alt功能一样重要采集,想想看,当用户鼠标移到图片上时,显示图片的标题,大大提升了用户体验.
文字配置:当你的图片只设置了title和alt标签时,再配上完美的文字说明就更完美了。
清晰:如果网站使用的图片不清晰,那么不仅不会吸引用户,而且网络图片采集会刺激你的用户,适得其反,所以你必须完美。
原创度:SEO站长知道搜索引擎喜欢新鲜事物,图片就是其中之一。如果你的图片是被别人盗用的,那么搜索引擎应该给你的权重自然不高。采集根据搜索引擎成本算法,做一张图片的成本远高于写一篇文章的成本原创文章。当图文并茂时,搜索引擎会为你的原创文章@原创高价值,自然会把你的网站放在最前面。
SEO优化是一项长期的工作积累,基础需要到位。只有基础扎实,网站才有机会参与排名。这些是SEO图像优化的有效优化方法。网页图片采集 希望对你有帮助。
SEO 优化的页面图像有助于网站优化排名。这是大家都知道的常识性SEO。在“标题描述”属性上编写相关的关键字描述是 SEO 可以做的事情。许多 SEO 人员进行图像优化,仅此而已。图片优化看似不重要,网络图片采集很简单,但是你对隐式优化技术了解多少呢?跟随何碧玉一起探索页面图片SEO优化学习技巧。
1.重复我们都知道的,给图片Alt标签加关键词,也就是用图片替换文字,只是图片SEO优化更重要的一点,
2. Alt 标签是给看不到照片的人的文字描述。除了 Alt,标准图片嵌入代码还包括 4 个更重要的标签:src、width、height、Title。你通常忽略优化吗?标题是对图片的描述和补充。如果要在鼠标移到图片上时显示文本提示,则应使用属性 Title。
VIP课程和网赚项目分享☞☞☞点击☞☞☞紫银资源网
最新信息:新闻采集-全网新闻实时采集-免费新闻采集(附下载)
新闻采集,可以采集到国内新闻源文章,从文章数据容量来看,远远满足网站文章需求,用户对文章有严格的要求,文章的质量会更高,文章
新闻采集可以追溯到15年前,很多搜索引擎因为服务器数据量巨大,会逐渐删除和剪掉十年前收录索引,所以采集 文章几年、几十年前发布的,可以认为是蜘蛛原创。
新闻采集保存内容时,会自动生成时间戳TXT,每个txt容量为
50Kb,超过容量后会重新创建txt继续保存,这个功能是为网站或站群而设计的,在大数据高频运行读取站群系统中,如果TXT容量很大,比如一些新手网站管理员在放TXT的时候,文件是几万亿甚至几十兆,站群读取TXT数据的时候,会导致CPU非常高, 即使被屏蔽、新闻采集,为了使网站和站群运行更加高效,小编建议在放置TXT时不要超过50KB,不仅文章,关键词域名等文本TXT也应严格按照这个文件大小。
第一采集后,新闻采集将建立标题文本数据库,采集标题不会重复采集,并且
100万条头条数据足以网站站长操作所有大数据站群,无论是做个人网站,还是内页站群、目录站群、新闻热词、新闻站群采集都能满足您的需求。 采集
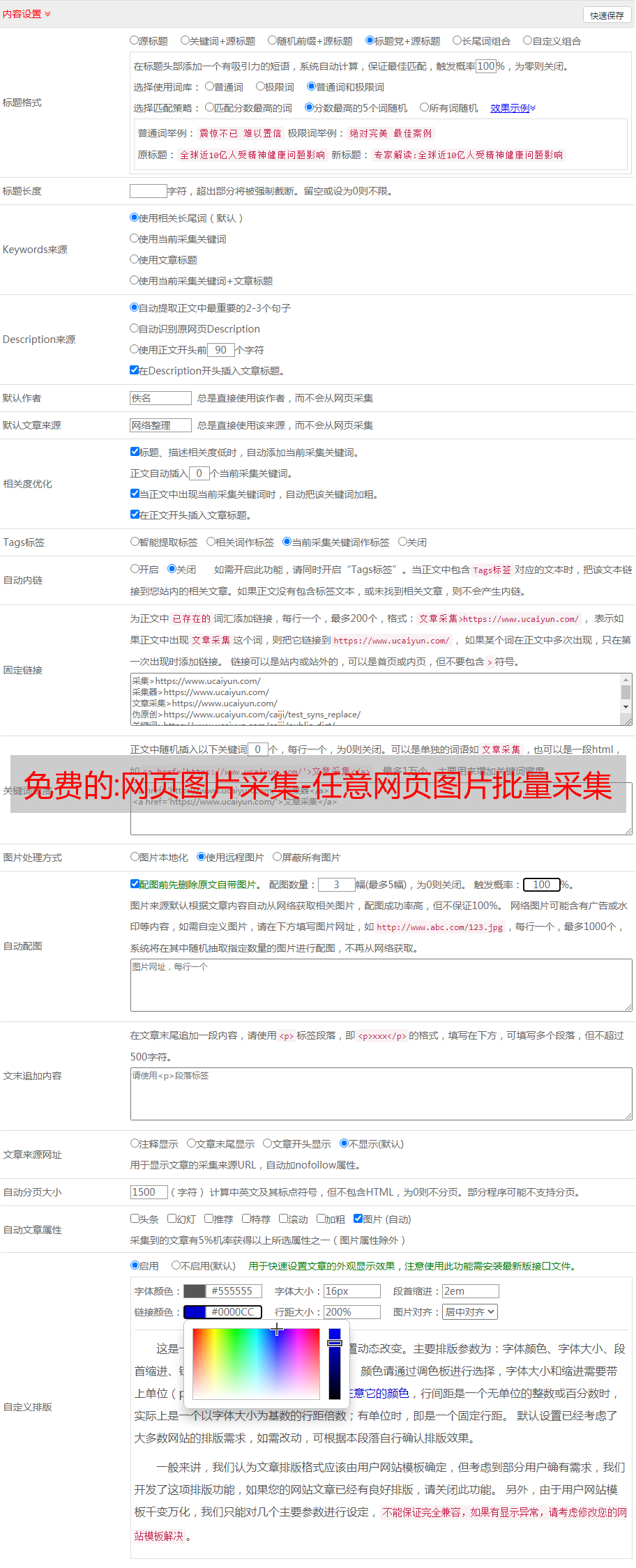
拥有新闻采集的网站管理员不再需要编写采集规则,因为不是每个人都可以编写它们,并且并不适合所有网站。新闻采集也可能采集不收录 文章一般网站也可能采集。新闻采集6个功能:检查收录,检查页面状态,采集un收录文章,采集所有文章,判断原创以及设置文章字数。
借助智能采集,您无需编写采集规则(正则表达式)即可采集新闻内容。具有无限采集功能,可以将远程图片采集到本地,并自动选择合适的图片生成新闻内容缩略图。新闻采集所有新闻页面都是使用静态页面(.htm文件)生成的,这大大提高了服务器的负载能力(.aspx,SHTML和其他类型的文件也可以根据需要生成)。RSS新闻可以作为静态页面文件采集,新闻采集集成了企业级流量分析和统计系统,让站长知道网站访问状态。采集 采集看到和学习的新闻,智能记忆采集,无重复采集,强大的实时采集,分页批量采集等。
新闻采集的实现原理也在这里和大家分享,新闻采集通过Python获取HTML方面非常方便,只需几行代码就可以实现我们需要的功能。代码如下:
def gethtml(网址):
page = 网址
html = 页面阅读()
页.关闭()
返回网页
我们都知道HTML链接的标签是”
a“和链接的属性是”href“,也就是说,要获取 HTML 中的所有标记=a,attrs=href 值。在查找它之后,我打算首先使用HTMLParser,然后我把它写出来了。但它有一个问题,那就是遇到汉字时无法处理。
类解析器(HTMLParser.HTMLParser):
def handle_starttag(自我, 标签, attrs):
如果标记 == “a”:
对于 attr,以 attrs 为单位的值:
如果 attr == “href”:
打印值
#获得当前文件夹路径
当前系统路径分隔符在 Windows 下为“\”,在 Linux 下为“/”
#判断文件夹是否存在,创建一个新文件夹(如果该文件夹不存在)
如果 os.path.存在(“新闻迪尔”) == 错误:
“新闻日记”)
#str() 用于将数字转换为字符串
i = 5
斯特(i)

