事实:高效伪原创写作——原作者知道后都懵了
优采云 发布时间: 2022-10-27 16:23事实:高效伪原创写作——原作者知道后都懵了
在《建立自己影响力的过程原本这样想,迈出第一步》中,我们说过,为了从外界获得更多的资源,打造个人IP扩大影响力是一个不可回避的环节。基于此考虑,我们策划并成功执行了大量平台的注册。
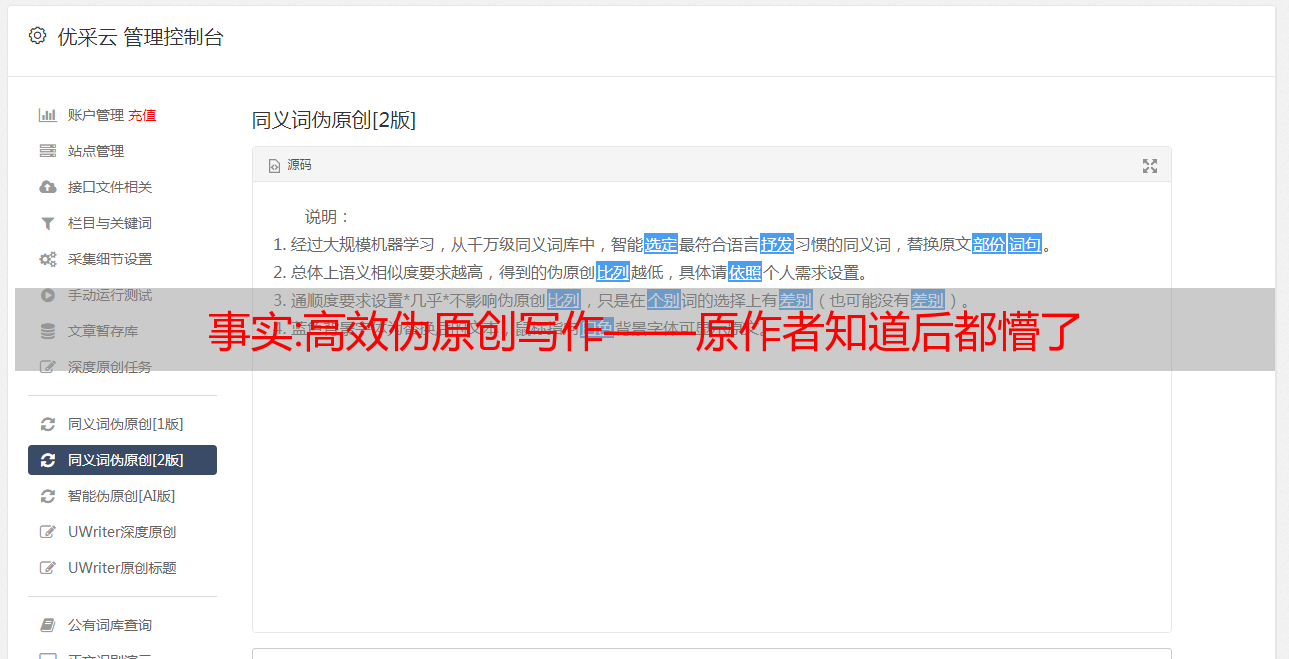
注册账号后,需要不断输出文章。我将 文章 创作分为两类 - 原创 和 伪原创。原创大家都懂,那你怎么理解伪原创呢?中国文化博大精深。对于同一个句子,你可以直接说,倒着说,或者换一种方式说,只有一半是基于你的理解... 伪原创 其实就是这个意思。书面的 文章 重组语言出版。
我们一直在强调,为了让基因继续存在,它需要无限的能量去抓取。作为基因的载体,我们生来就肩负着将身边的资源高效转化为能量的使命。因此,可以选择任何有利于其转化的方法。没有对错,但一定要有原则!小到像我这样的个人或小团体,为了宣传自己,大到组织或公司,发布大量软文来宣传自己的产品或服务,都需要写一个很多事情,不包括极少数全面和知识渊博的出口商。人,大部分人其实并没有这个能力,所以伪原创产品不可避免的出现了。作为一个普通人,我自然会在工作中使用很多这些工具。它在很大程度上提高了我的生产效率。今天又捡了几款产品,慢慢说吧......
目的
寻找素材,创造灵感,在短时间内完成高效创作
工具
乐观,爱写作,5118,新媒体管家
过程
1. 明确写什么
大多数时候,如果我们要写一篇文章文章,不会有太多的想法。这个时候,顺着热点寻找灵感是个好主意。首先,它可以为我们节省大量的思考时间。做更重要的事情,二是在发布的同时获得更多关注

乐观截图
之前的文章推荐了工具Optimistic。其100,000爆文功能将在指定时间段内显示这些平台的热点文章收录并免费显示。省去了我们一一搜索的时间,把自己的方向和热门话题结合起来,思路自然展开。
2.疯狂采集素材
大多数时候,即使我们有一个想法,我们仍然不知道从哪里开始,幸好我们已经有了一些 关键词
乐观查号截图
5118搜索截图
通过搜索第一步识别的关键词,我们成功获得了大量的文章。大致浏览完这些文章,通过简单的排列组合,一篇文章的整体布局
3.高效写作
大多数时候,即使知道整体布局,还是写得很慢,急得头发都掉光了!那有什么好办法吗?

喜欢写截图
热爱写作——我工具箱里的宠儿之一!它的人工智能算法产品彻底摆脱了市面上同类产品只使用简单的关键词替换或低智能的人工算法(上图为效果图),在这个领域,现在就够了!
乐观数原创检测截图
我们对乐观账户中修改后的内容进行了原创测试,结果显示最高相似度仅为32.89%。我们只需要对修改后的文章进行简单的修改,一篇高质量的文章伪原创文章正在兴起!
4. 优雅的排版
最后一步是针对公众号等平台。找一些吸引人的LOGO,文章模板样式与内容相匹配,绝对是加分项。
新媒体管家式截图
我身边用伪原创赚大钱的人不在少数。他们每天都精力充沛。他们很早就来到办公室,急切地打开了电脑。这时,屏幕右下角的图标突然一闪。随着这突如其来的一闪,他们的眼光越来越贪婪…… 点击打开图标,屏幕前出现了几篇别人发表的文章文章。他们并不着急。短时间内,他们用神秘的黑科技工具换了文章的脸,按下了确认提交按钮。这时,手机的微信钱包突然想起了一个年轻女子温柔的声音:微信钱包到了……(最后放松一下,文章纯属虚构,如有雷同……)
工具有善有恶,我们会在文章分享更多内容。如果你想听到更多不可告人的细节和八卦,可以关注我的公众号和知识星球——本宇的生意;但无论如何,依靠优质内容,打造个人IP,最终获得更多资源和高效转化才是我们的终极目标!
技术文章:「Python」纯干货,5000字的博文教你采集整站小说(附源码)
目录
前言
开始
分析 (x0)
分析 (x1)
分析 (x2)
分析 (x3)
分析 (x4)
完整代码
我有话要说
前言
大家好,我叫山念,这是我的第二篇技术博文(第一篇是关于我自己的经历),已经连续三天更新了,每天花两个小时写一个实战案例。我也很享受。谢谢大家的支持。
我们今天要做的就是用Python爬取整个网站上的所有小说内容,其实在我心里,采集的内容根本无所谓,最重要的是大家可以学我的分析思维,授人以鱼不如授人以渔。
开始
既然我们要采集整个站点数据,那么我们输入目标网站,点击所有作品。
分析 (x0)
第一步是右键查看网站源码看看有没有我们需要的书的源文件地址(当然要看源文件的地址,因为内容一本书这么大,一页书这么多,肯定不是源代码里的全部内容)。
可以看到我可以在元素中找到书名和介绍,然后关键是一个跳转网址,这个网址很重要,因为我们点击这个链接后,他会跳转到单本小说。
一部小说必然有章节分类,我们要做的就是采集每部小说的章节名称。
最终目的是每部小说都是一个以书名命名的文件夹,然后所有章节都存放在文件夹中,每一章都是一个txt文件,没有章节名对应txt文件名。
分析 (x1)
逆向,切记不要把element看成源代码的问题!!元素可能是浏览器执行一些JavaScript后显示的源代码,与服务器传递给浏览器的源代码不同。
所以我们还是要看看源码中是否有跳转链接和书名。
好吧,源代码中也有。但也不能大意,一定要检查源代码中是否有,element不代表源代码。
所以先采集看书名,第一页跳转链接
# 抓取第一页的所有书籍名字,书籍入口
# 到了书籍入口后,抓取章节名字,章节链接(文字内容)
# 保存
import requests
from lxml import etree
import os
url='https://www.qidian.com/all'
req = requests.get(url).text
html = etree.HTML(req)
booknames = html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
tzurls = html.xpath('//div[@class="book-mid-info"]/h4/a/@href')
for bookname, tzurl in zip(booknames, tzurls):
if not os.path.exists(bookname):
# if os.path.exists(bookname) == False:
os.mkdir(bookname) # 创建文件夹
这符合我们的想法。每次 采集 到达书名时,我们都会为其创建一个单独的文件夹。
完全没有问题,到这里我们已经完成了第一步。
分析 (x2)
然后下一步就是模拟我们采集要去的书目录的跳转链接,然后用同样的方法去采集的跳转链接到章节名和章节内容。
同样可以自己查源码,数据也在里面。
然后写代码
import requests
from lxml import etree
import os
url = 'https://www.qidian.com/all'
req = requests.get(url).text
html = etree.HTML(req)
booknames = html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
tzurls = html.xpath('//div[@class="book-mid-info"]/h4/a/@href')
for bookname, tzurl in zip(booknames, tzurls):
if not os.path.exists(bookname):
# if os.path.exists(bookname) == False:
os.mkdir(bookname) # 创建文件夹
req2 = requests.get("http:" + tzurl).text
html1 = etree.HTML(req2)
zjurls = html1.xpath('//ul[@class="cf"]/li/a/@href')
zjnames = html1.xpath('//ul[@class="cf"]/li/a/text()')
for zjurl, zjname in zip(zjurls, zjnames):
print(zjname+'\n'+zjurl)
效果图:
分析 (x3)
你知道为什么我没有将带有章节名称的txt文件保存在文件夹中吗?
因为我们还没有获取到章节的内容,是不是需要先把章节的内容写入章节的txt,然后保存到文件夹中呢?
当然,这个解释是为了照顾新手。
那么下一章的内容采集,方法就不说了,一模一样,上一章源码中也有这一章的内容。
每个标签只保存一行内容,所以需要将采集中的所有内容合并起来,并用换行符分隔,尽量保持文章的格式。
代码开始:
import requests
from lxml import etree
import os
url = 'https://www.qidian.com/all'
req = requests.get(url).text
html = etree.HTML(req)
booknames = html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
tzurls = html.xpath('//div[@class="book-mid-info"]/h4/a/@href')
for bookname, tzurl in zip(booknames, tzurls):
if not os.path.exists(bookname):
# if os.path.exists(bookname) == False:
os.mkdir(bookname) # 创建文件夹
req2 = requests.get("http:" + tzurl).text
html1 = etree.HTML(req2)
zjurls = html1.xpath('//ul[@class="cf"]/li/a/@href')
zjnames = html1.xpath('//ul[@class="cf"]/li/a/text()')
for zjurl, zjname in zip(zjurls, zjnames):
print(zjname+'\n'+zjurl)
req3 = requests.get('http:' + zjurl).text
html2 = etree.HTML(req3)
nrs = html2.xpath('//div[@class="read-content j_readContent"]/p/text()') # 分散式内容
nr = '\n'.join(nrs)
file_name = bookname + "\" + zjname + ".txt"
<p>
print("正在抓取文章:" + file_name)
with open(file_name, 'a', encoding="utf-8") as f:
f.write(nr)</p>
效果图:
这里需要注意的是,我们只抓取了第一页的数据。那么如何抓取整个站点的数据呢?
分析 (x4)
一般稍微有经验的人都知道,当我们翻页的时候,网站的url会发生变化,通常页码在url上。
只需要构建一个for循环将页数变成一个变量,不用多说,直接上最终完整代码,代码仅供参考,最终可以自己修改效果。
完整代码
import sys
import requests
from lxml import etree
import os
for i in range(sys.maxsize):
url = f'https://www.qidian.com/all/page{i}/'
req = requests.get(url).text
html = etree.HTML(req)
booknames = html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
tzurls = html.xpath('//div[@class="book-mid-info"]/h4/a/@href')
for bookname, tzurl in zip(booknames, tzurls):
if not os.path.exists(bookname):
# if os.path.exists(bookname) == False:
os.mkdir(bookname) # 创建文件夹
req2 = requests.get("http:" + tzurl).text
html1 = etree.HTML(req2)
zjurls = html1.xpath('//ul[@class="cf"]/li/a/@href')
zjnames = html1.xpath('//ul[@class="cf"]/li/a/text()')
for zjurl, zjname in zip(zjurls, zjnames):
print(zjname+'\n'+zjurl)
req3 = requests.get('http:' + zjurl).text
html2 = etree.HTML(req3)
nrs = html2.xpath('//div[@class="read-content j_readContent"]/p/text()') # 分散式内容
nr = '\n'.join(nrs)
file_name = bookname + "\" + zjname + ".txt"
print("正在抓取文章:" + file_name)
with open(file_name, 'a', encoding="utf-8") as f:
f.write(nr)
我有话要说
——女朋友是私有变量,只有我班可以调用(第二周纪念分手
emmm之前本来是录视频教程的,但是离开之前的公司之后就丢失了。在这里向大家道歉。
不过文章的字现在都写好了,每一个文章我都会说的很详细,所以耗时比较长,一般两个多小时,每一个文章达到五个左右一千字。
原创不容易,再次感谢大家的支持。
①2000多本Python电子书(主流经典书籍应该都有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的培训项目及源码)
④Python基础、爬虫、web开发、大数据分析视频介绍(适合初学者学习)
⑤ Python学习路线图(告别无经验学习)
私信小编01获取大量python学习资源

