技巧:网站程序自带的采集器采集文章格式是什么?教程
优采云 发布时间: 2022-10-27 07:15技巧:网站程序自带的采集器采集文章格式是什么?教程
网站程序自带的采集器采集文章格式是以extra为分隔符,只采集文章标题、关键词等部分,需要建立一个cookie来保存这个信息。
谢邀自己以前做技术培训的时候一直在想一个问题,那就是直接记录关键词不是更有利于用户的浏览习惯吗,这些词我已经习惯了,但是如果按照普通的采集器的做法,如自己的文章会有后续不太确定文章提交到平台的页面是否被采集,采集的话页面数量有一定的量会过多,也会增加服务器压力,但是采集器记录的内容不一定都包含文章的关键词。
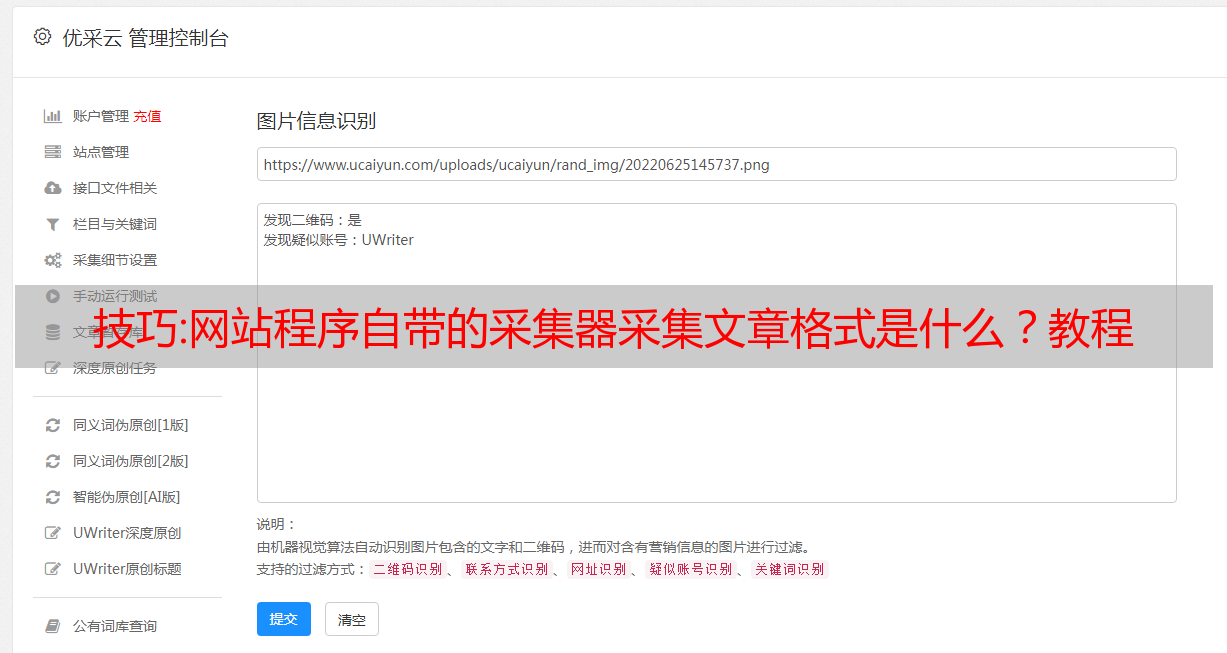
这个时候需要一种平台服务器上记录,采集采集文章的关键词的功能方法,还有一种是按照关键词分词来进行,但是我们这种方法都只能做一些辅助的作用,用来记录文章主要的文章提交相关数据,方便用户习惯。
有道云笔记、onenote、印象笔记我都用过、记录爬虫代码。
evernote,草稿纸,印象笔记等,也可以用网页剪报。我个人用的是这三个,
我一直用remembertoword,大概是第一种方法在数据库里比较简单一些。
remembertowordtofindwrittenenglishentirelyinthewebdatabase
可以找现成的产品,非要手动编程的话,可以试试看采集微博数据我现在用的是这个:clojurepreprocessor具体wiki上有教程。

