完整的解决方案:1个功能搞定引流+转化+留存3大难题:EduSoho用户信息采集功能来了!
优采云 发布时间: 2022-10-27 03:17完整的解决方案:1个功能搞定引流+转化+留存3大难题:EduSoho用户信息采集功能来了!
对于在线学校来说,用户信息无疑是最有价值的。
一方面,用户信息越完整,网校能提供的针对性教学服务就越细;
另一方面,获取的用户信息越多,网络学校营销活动的覆盖面越广,提示用户下单续费的概率就越高。
那么,学生如何主动将个人信息留在合理节点上呢?
别着急,EduSoho用户信息采集功能来了!
EduSoho用户信息采集「功能介绍」
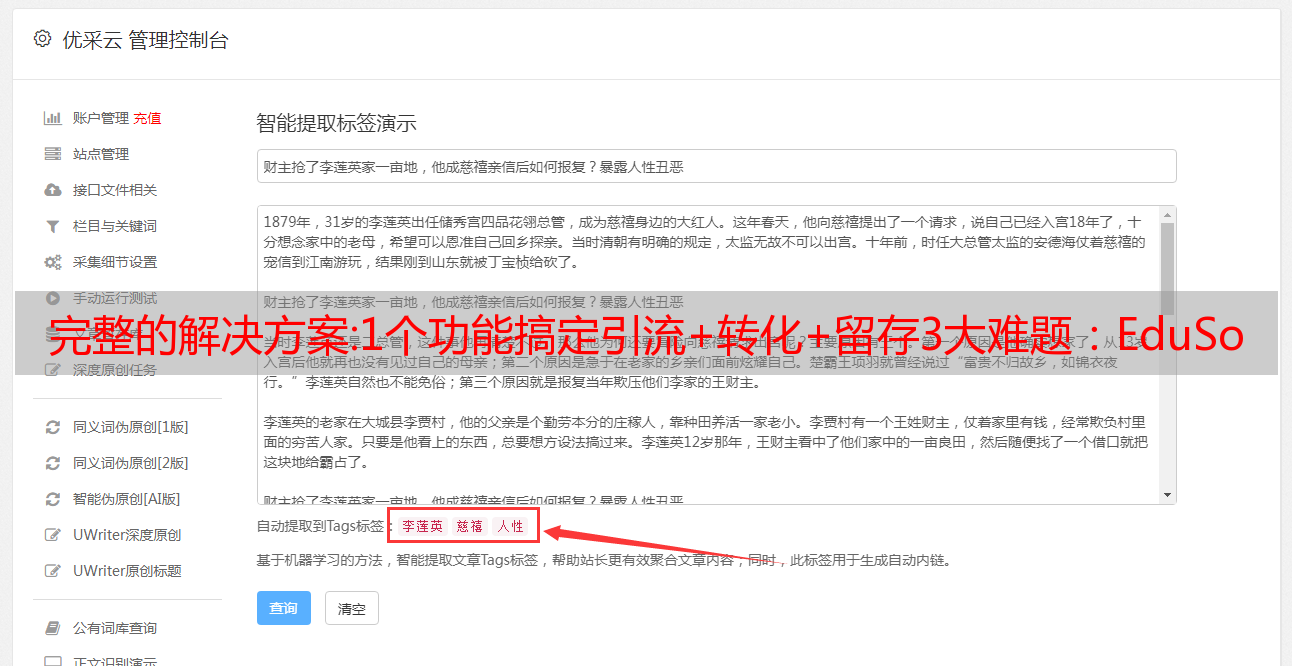
EduSoho用户信息采集功能可以让运营商以表格的形式按需获取用户信息,清晰描绘用户画像。
EduSoho支持自定义采集位置(上课/课程、预付费/后付费)、采集方式(是否允许跳过)、采集信息(手机号、微信ID、名称...)编号和排序等。
▲“用户信息采集”自定义配置项(部分)
▲ 《用户信息采集》自定义表单内容(部分)
灵活的采集设置不仅可以帮助组织有效增加采集的曝光率,还可以根据需要减少对用户的干扰。
EduSoho用户信息采集「申请指南」
有了这个功能,获取用户信息就容易多了。
那么,只要运营商合理利用采集到的用户信息,网校运营中“引流、转化、留存”这三个最头疼的问题也能迎刃而解。
01.解决排水问题
采集免费课程注册信息,搭建私域流量池
目前,交通成本正在上升。您是否只关注免费试听课程的转化率?
EduSoho用户信息采集功能可以让机构在免费课程的注册链接中嵌入表格,不影响用户体验,同时还可以采集试听学生的信息,建立自己的私人域名流量池,最大化营销效益。到最大。
▲《EduSoho PC》用户信息采集预览
组织拥有自己的私域流量池,可以更好地塑造品牌形象IP,提升裂变传播效果。而且,比起为公域流量“撒网”,私域流量*敏*感*词*用户的培养也更有价值。哦!
02.解决转换问题
采集引流课程学员信息,促进销售转化
机构为了促进正价课程的销售,往往会设置1-2个低价课程来吸引流量。这时,在购买低价课程的支付环节设置信息采集表,可以帮助机构快速识别目标用户。
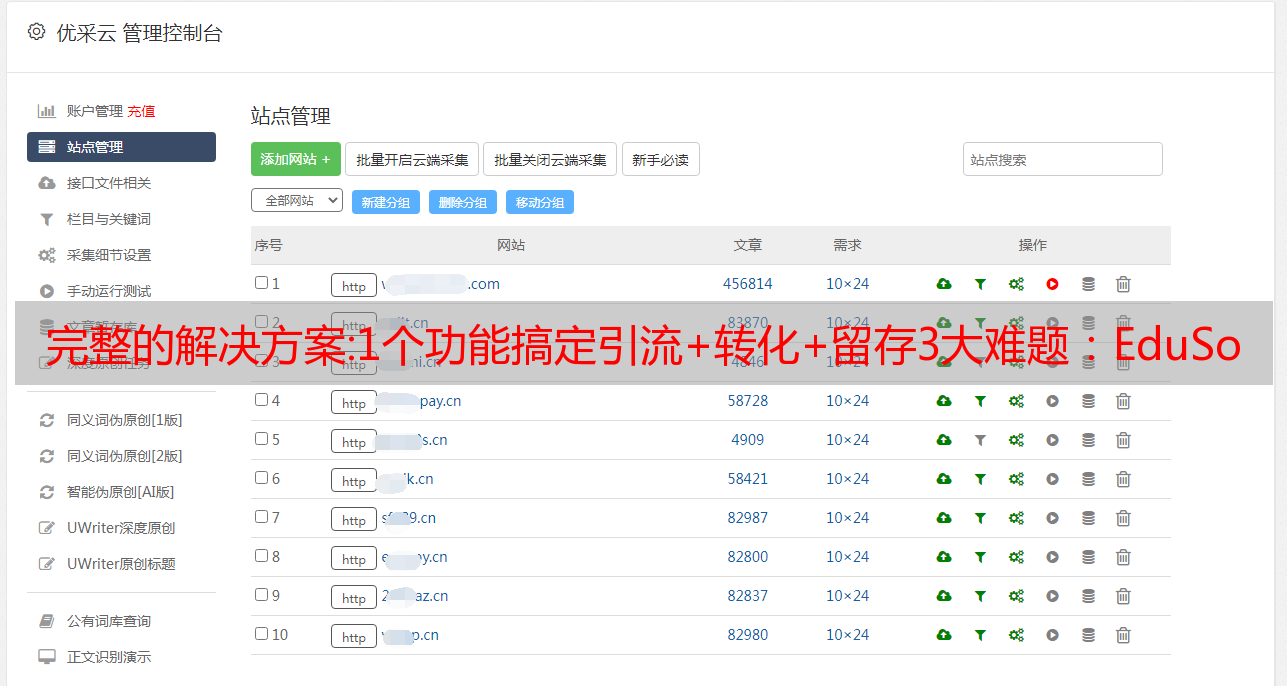
▲ 《EduSoho微网校端》用户信息采集预览
然后将这些用户信息进行点对点跟进,辅以优惠活动、限时福利等促销政策,可以有效提升正价课程的销售转化率。
03.解决留存问题
采集优质课程*敏*感*词*,提高课后教学服务效果
除了注重招生引流和转化,现有学生的用户体验也很关键。为了给学生提供定制化、个性化的贴心教学服务,采集*敏*感*词*是必不可少的。
▲“用户信息采集”后台管理页面
使用EduSoho用户信息采集功能,机构可以采集学生的个人信息,并在后台实时查看和管理采集到的信息数据,方便后续发放课程资料给学生。
此外,借助这些信息,院校还可以有针对性地为学生提供课程推荐、学习路径规划等服务,从而提高院校的美誉度和续订率。
提醒:
更新版本到EduSoho V20.4.1及以上,体验全新的“用户信息采集”功能!
(本期更新,用户端暂时只支持使用EduSoho新微网校端)
安全解决方案:在k8s上部署日志系统elfk
日志系统elfk前言
经过上周的技术预研,通过周一的一次会议,根据公司现有的业务流量和技术栈,选择的日志系统方案为:elasticsearch(es)+logstash(lo)+filebeat(fi)+kibana( ki) 组合。es选择使用阿里云提供的es,lo&fi选择自己部署,ki由阿里云发送。因为申请ecs需要一定的时间,所以我们暂时选择在测试&生产环境部署(请投诉,我们公司共享一套k8s用于测试和生产,托管在阿里云...)。花了一天时间(之前的部署快结束了),完成了elfk在kubernetes上的部署(先部署,以后根据需要优化)。
组件介绍
es 是一个实时、分布式和可扩展的搜索引擎,允许全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可以搜索许多不同类型的文档。
lo 的主要优点是它的灵活性,主要是因为它有许多插件、详细的文档和简单的配置格式,可以在各种场景中使用。我们基本上可以在网上找到很多可以处理几乎所有问题的资源。
作为 Beats 家族的一员,fi 是一款轻量级的日志传输工具,它的存在正在弥补 lo 的不足。fi 作为轻量级的日志传输工具,可以将日志推送到中央 lo。
ki 是一个分析和可视化平台,可以浏览、可视化存储在 ES 集群上的排名靠前的日志数据,并构建仪表板。ki是一款专业的日志展示应用,集成了大部分的es API,操作简单。
数据采集流程图
日志流:logs_data---> fi ---> lo ---> es---> ki。
logs_data通过fi采集日志,输出到lo,通过lo进行一些过滤和修改,然后传输到es数据库,ki读取es数据库进行分析。
部署
根据我司实际集群状态,本文档的部署将完全还原日志系统的部署。
在本地MAC上安装kubectl连接aliyun到主机k8s
在客户端(在任何本地虚拟机上)安装与托管 k8s 相同版本的 kubectl
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.14.8/bin/linux/amd64/kubectl
chmod +x ./kubectl
mv ./kubectl /usr/local/bin/kubectl
将阿里云托管的k8s的kubeconfig 复制到$HOME/.kube/config 目录下,注意用户权限的问题
部署 ELFK
申请一个命名空间(一般每个项目一个命名空间)。
# cat kube-logging.yaml
apiVersion: v1
kind: Namespace
metadata:
name: loging
部署 es。在网上找了一个类似的资源列表,根据自己的需要适当修改,运行,如果有错误根据日志修改。
# cat elasticsearch.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-class
namespace: loging
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
# Supported policies: Delete, Retain
reclaimPolicy: Delete
---
kind: PersistentVolume
apiVersion: v1
metadata:
name: datadir1
namespace: logging
labels:
type: local
spec:
storageClassName: local-class
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/data1"
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: loging
spec:
serviceName: elasticsearch
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.3.1
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: "discovery.type"
value: "single-node"
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "local-class"
resources:
requests:
storage: 5Gi
---
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: loging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
部署 ki。因为根据数据采集流程图,ki和es结合,配置比较简单。
# cat kibana.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kibana
namespace: loging
labels:
k8s-app: kibana
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana
template:
metadata:
labels:
k8s-app: kibana
spec:
containers:
- name: kibana
image: kibana:7.3.1
resources:
<p>
limits:
cpu: 1
memory: 500Mi
requests:
cpu: 0.5
memory: 200Mi
env:
- name: ELASTICSEARCH_HOSTS
#注意value是es的services,因为es是有状态,用的无头服务,所以连接的就不仅仅是pod的名字了
value: http://elasticsearch:9200
ports:
- containerPort: 5601
name: ui
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: loging
spec:
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana</p>
配置入口控制器。因为我们公司使用的是阿里云托管的k8s自带的nginx-ingress,并且配置了强制转换为https。所以kibana-ingress也应该和https配对。
# openssl genrsa -out tls.key 2048
# openssl req -new -x509 -key tls.key -out tls.crt -subj /C=CN/ST=Beijing/L=Beijing/O=DevOps/CN=kibana.test.realibox.com
# kubectl create secret tls kibana-ingress-secret --cert=tls.crt --key=tls.key
kibana-ingress 配置如下。有两种,一种是https,一种是http。
https:
# cat kibana-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: loging
spec:
tls:
- hosts:
- kibana.test.realibox.com
secretName: kibana-ingress-secret
rules:
- host: kibana.test.realibox.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
http:
# cat kibana-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: loging
spec:
rules:
- host: kibana.test.realibox.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
部署 lo。因为lo的作用是对fi采集的日志进行过滤,需要根据不同的日志进行不同的处理,所以可能会经常变化,解耦。所以选择以configmap的形式挂载。
# cat logstash.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: logstash
namespace: loging
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: elastic/logstash:7.3.1
volumeMounts:
- name: config
mountPath: /opt/logstash/config/containers.conf
subPath: containers.conf
command:
- "/bin/sh"
- "-c"
- "/opt/logstash/bin/logstash -f /opt/logstash/config/containers.conf"
volumes:
- name: config
configMap:
name: logstash-k8s-config
---
apiVersion: v1
kind: Service
metadata:
labels:
app: logstash
name: logstash
namespace: loging
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: logstash
type: ClusterIP
# cat logstash-config.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app: logstash
name: logstash
namespace: loging
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: logstash
type: ClusterIP
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-k8s-config
namespace: loging
data:
containers.conf: |
input {
beats {
port => 8080 #filebeat连接端口
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"] #es的service
index => "logstash-%{+YYYY.MM.dd}"
}
}
注意:修改configmap 相当于修改镜像。必须重新apply 应用资源清单才能生效。根据数据采集流程图,lo的数据由fi流入,流向es。
部署fi。fi的主要作用是记录采集,然后把数据交给lo。
# cat filebeat.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: loging
labels:
app: filebeat
data:
filebeat.yml: |-
filebeat.config:
inputs:
# Mounted `filebeat-inputs` configmap:
<p>
path: ${path.config}/inputs.d/*.yml
# Reload inputs configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
# To enable hints based autodiscover, remove `filebeat.config.inputs` configuration and uncomment this:
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# hints.enabled: true
output.logstash:
hosts: ['${LOGSTASH_HOST:logstash}:${LOGSTASH_PORT:8080}'] #流向lo
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-inputs
namespace: loging
labels:
app: filebeat
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: loging
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: elastic/filebeat:7.3.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env: #注入变量
- name: LOGSTASH_HOST
value: logstash
- name: LOGSTASH_PORT
value: "8080"
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: inputs
mountPath: /usr/share/filebeat/inputs.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: loging
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: loging
labels:
app: filebeat
---</p>
至此,es+lo+fi+ki在k8s上的部署就完成了,进行简单的验证。
核实
查看svc、pod、ingress信息
# kubectl get svc,pods,ingress -n loging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None9200/TCP,9300/TCP 151m
service/kibana ClusterIP xxx.168.239.2xx5601/TCP 20h
service/logstash ClusterIP xxx.168.38.1xx8080/TCP 122m
NAME READY STATUS RESTARTS AGE
pod/elasticsearch-0 1/1 Running 0 151m
pod/filebeat-24zl7 1/1 Running 0 118m
pod/filebeat-4w7b6 1/1 Running 0 118m
pod/filebeat-m5kv4 1/1 Running 0 118m
pod/filebeat-t6x4t 1/1 Running 0 118m
pod/kibana-689f4bd647-7jrqd 1/1 Running 0 20h
pod/logstash-76bc9b5f95-qtngp 1/1 Running 0 122m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/kibana kibana.test.realibox.com xxx.xx.xx.xxx 80, 443 19h
网页配置
配置索引
寻找
到目前为止,它很容易完成。需要进行后续优化,但这是后果。
问题总结
这应该是我第一次在测试和生产环境中亲自部署应用程序,对系统非常陌生。遇到了很多问题,需要总结一下。
如何研究技术栈;如何选择解决方案;因为网上几乎没有类似的解决方案(不知道其他公司是怎么做的,反正我在网上也找不到有效可行的参考)。你需要根据不同的文件总结你的尝试;组件的标签尽可能一致;如何查看公司是否实施了端口限制和https强制转换;遇到IT事情,一定要读日志,这很重要,日志可以解决大部分问题;一个人再好,都会忽略一些点,先试试再请朋友一起进步。该项目首先启动,然后是其他事情。目前,有20%的把握可以做一件事。它没有 在 80% 的情况下这样做是没有意义的。自学侧重理论,公司学习操作。

